
Предыстория
Последние полгода я активно занимаюсь разработкой сервисов на базе больших языковых моделей, они же «LLM». Для каждого проекта мне приходится подбирать модель по определенным критериям: языковая поддержка, требования к памяти, типу (instruction-based или completion), скорости генерации и т.п. Первое время я использовал платформу HuggingFace, где ежедневно публикуются около сотни новых моделей. Но кто им пользовался, знает, насколько там неудобный и слабый поиск: даже точные совпадения по названию он иногда не выдаёт. Плюс к этому, приходится тратить достаточно времени, чтобы найти и сравнить модели по нескольким критериям.
На платформе, конечно, можно обнаружить пару рейтингов, которые немного упрощают задачу выбора. Там даже можно сориентироваться по бенчмаркам: HuggingFace Leaderboard (общие) и BigCode LeaderBoard (для генерациии и обработки исходного кода). Но упрощают поиск они не сильно, потому что даже при наличие готовых таблиц с очевидными лидерами, сами списки моделей небольшие. Например, HF Leaderboard ограничивается только 1300 моделями, BigCode отображает всего около 30, в то время как «за бортом» рейтинга остаются десятки других новых и интересных квантизованных или «затюненных» моделей, более подходящих для моих задач. Их только нужно как-то найти.
Иногда мелькали ссылки на github репозитории с рейтингами моделей. Но они обновляются редко и содержат, пожалуй, даже ещё более короткий список моделей. Так что тоже не то.
В результате я решил, что нужно взять актуальную базу моделей с HuggingFace, где их порядка 40.000, и прикрутить к этой базе удобный интерфейс для поиска, фильтрации и сравнения моделей. Так появился проект LLM Explorer.
Каждый день бот сканирует репозитории и добавляет новые языковые модели, удаляет неактуальные, обновляет информацию о числе лайков и загрузок по существующим. Кроме этого, дополняет данные о моделях значениями бенчмарков из нескольких рейтингов, что позволяет их сравнивать по различным срезам. На декабрь в базе LLM Explorer больше 14.000 актуальных языковых моделей. Могло быть и больше, но я не добавляю в базу модели с нулевыми загрузками и те, что сильно устарели.
Теперь выбор нужной языковой модели у меня занимает пару минут.
Возможности LLM Explorer
Если бы меня попросили обозначить наиболее значимые возможности LLM Explorer, я бы назвал следующие:
Готовые тематические списки языковых моделей: те, которые работают на 8GB или 16GB оперативки, сгруппированные по параметрам (7b, 34b), instruction-based модели, доступные для коммерческого использования, «без цензуры» и пр.
Рейтинг по основным группам моделей сразу на стартовой (блоки «TOP 10...»), включая те, что сейчас в тренде.
Наличие таблицы сравнения для списка похожих моделей внутри когорты.
Возможность быстрого анализа «внутренностей» моделей, их параметров обучения и файн-тюнинга.
Функция быстрого и контекстного поиска по ключевым словам и тегам.
Многоуровневая фильтрация с помощью выпадающих меню внутри таблицы: можно задать требуемые языки, лицензии, типы квантизации, теги и другие характеристики.
Сохранение настроек поиска и ранее используемых фильтров.
Анализ списка моделей, полученных на основе базовой модели (см. поле «Базовая модель» в карточке модели).
Стартовая страница
В большинстве случаев мне достаточно зайти на стартовую и сразу «провалиться» в нужную модель, которая обычно оказывается лучшей в своей группе. Для этого есть рейтинги. Но если хочется более детального сравнения, то лучше начать с полного списка или конкретной группы (например, «LLM for Commercial Use» или «Models Fit in 8GB RAM», если хочется найти вариант подешевле).

Ниже я покажу, как находить подходящие модели для решения ваших задач на паре примеров.
Пример использования №1: Поиск более интересной альтернативы для популярной модели Mistral 7B
В качестве базы я возьму популярную модель Mistral 7B, про которую активно рассказывают в блогах и ML-пабликах. Модель хорошая, рабочая, но вдруг есть более качественная альтернатива с той же архитектурой? Открываем страницу https://llm.extractum.io/list/ — здесь размещен полный каталог моделей. После этого введем в строку быстрого поиска «mistral-7b»:

Первая строка — лидер рейтинга, который может похвастаться оценкой 63.64 на Leaderboard. Обратите внимание, это не оригинальная модель Mistral 7B от MistralAI, а её «затюненная» версия. Оригинальная Mistral имеет более низкий балл 54.96. Так почему бы не попробовать альтернативную?
Рассмотрим другой пример, когда вы находитесь внутри карточки оригинальной модели Mistral 7B:

Справа вы найдете список альтернативных моделей, каждая из которых имеет ту же архитектуру и похожие параметры, но другую оценку. Зеленый цвет означает, что модель превосходит выбранную вами по своим параметрам.
Перейдем к первому варианту в списке:

Это лучшее решение в категории. Таким образом, вы можете находить для себя более подходящие варианты по важным для вас параметрам.
Пример использования №2: Поиск модели, совместимой с архитектурой Llama, которой будет достаточно 16 ГБ оперативки на MacOS, с большим контекстным окном и высоким рейтингом на Hugging Face
Снова погружаемся в процесс поиска. На этот раз наша цель — лучшая модель для коммерческого использования, которая эффективно работает на 16 ГБ ОЗУ MacOS и совместима с библиотекой llama.cpp. Так что же будет считаться «лучшей» моделью в этом контексте? — Та, которая имеет самый высокий рейтинг на HF Leaderboard, минимальное требуемое VRAM для вывода (менее 16 ГБ) и максимальную длину контекста.
Начнем поиск отсюда: https://llm.extractum.io/list/?16GB.

Для начала скроем все лишние столбцы:

Затем отфильтруем модели на основе их типа архитектуры. Оставим только те, которые совместимы с Llama:

Перед нами список оставшихся 3900 моделей из первоначальных 8900. Теперь отсортируем все модели, у которых длина контента составляет менее 32 000 токенов:

Осталось 135 решений. Что ж, сузим выбор до моделей с коммерческими лицензиями, включая лицензии MIT, Apache-2.0 и лицензии Creative Commons (и исключая любые с некоммерческими вариациями):

Теперь можно выдохнуть — в списке только 17 моделей. Учитывая, что только две модели из списка имеют оценки на HuggingFace Leaderboard, начать лучше с них. Например, с этой:

Чтобы открыть карточку модели, нужно кликнуть по её названию. Внутри содержится полная информация по ее параметрам, включая размер контекста:

Все они отлично справляются с задачей анализа данных для поиска нужных результатов, хотя и имеют более короткий контекст. Таким образом, если контекст в 32000 токенов — не критический параметр, можно рекомендовать первую модель из списка альтернатив.
Кстати, этот процесс поиска можно запустить и с другой страницы — https://llm.extractum.io/list/?for_commercial. Она содержит все модели, разрешенные для коммерческого использования — это значит, что сразу можно сосредоточиться на поиске по другим параметрам:

Таким образом, можно использовать многоуровневую фильтрацию моделей, начиная с
требуемого объема видеопамяти, типа лицензии, типов моделей (Codegen, основанные на инструкциях), типа квантизации (GGUF, AWQ, GPTQ) и т.д;
выбора конкретных ключевых слов, упомянутых в названии, описании, тегах и т.д. через быстрый поиск;
фильтрации или выбора конкретных элементов через выпадающее меню в таблице или использования предустановок в выпадающем списке.
Альтернативные критерии выбора оптимальной модели
Рейтинг HuggingFace Leaderboard — не единственный помощник для поиска подходящей модели. При выборе вы можете учитывать популярность/трендовость модели, которая формируется на базе динамики загрузок и «лайков» за последние 3 дня.
Выпадающее меню с пресетами позволяет быстро переключаться между списками, сформированными на основе различных критериев:

Интерфейс карточки модели
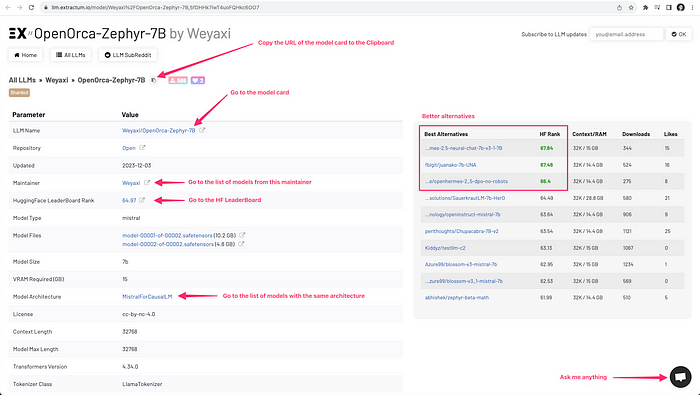
Помимо описанных случаев использования, можно выделить ряд возможностей LLM Explorer, которые помогают сделать навигацию среди тысячей моделей более приятной и эффективной. В частности, повысить удобство работы с карточкой модели. Данные возможности проиллюстрированы на скриншоте ниже:
Планы по развитию
Есть несколько новых возможностей, которые скоро появятся в сервисе:
Отдельные бенчмарки моделей ARC, HellaSwag, MMLU, HumanEval, и другие популярные, а также отдельные бенчмарки по поддержке языков программирования для Code-Generation моделей.
Стоимость использования моделей на типовых конфигурациях.
Быстрый фильтр по поддерживаемым языкам.
Быстрый фильтр по отраслям и тематике модели (математичекая, финансовая, медицинская и пр).
Ну и самая частая просьба от посетителей - это темная тема.
Заключение
Если у вас появились вопросы по функциональности или предложения по развитию сервиса, напишите в комментариях. Буду рад любой обратной связи.
