
Сегодня Яндекс объявил о крупном обновлении Карт. Теперь на сервисе доступна подробная карта мира, с детализацией вплоть до домов и маршрутизацией. Все основные названия на ней представлены сразу на двух языках: местном и русском.
Кроме того, карты России, Украины, Казахстана и Беларуси теперь полностью принадлежат Яндексу.
Сервис теперь работает на единой платформе, позволяющей поддерживать и самостоятельно обновлять любые объёмы данных. Карты России, Украины, Беларуси и Казахстана обновляют картографы Яндекса каждый месяц. Все остальные страны, схемы которых нарисованы партнёром Яндекса — компанией Navteq, изменяются раз в три месяца.

Детальнее всего на части Navteq выполнены Европа и Северная Америка: со всеми основными улицами и домами в городах и подробной сетью дорог, по которым сервис умеет строить автомобильные маршруты.
Большинство топонимов на картах Navteq было записано латиницей, хотя для некоторых языков (например, тайского и арабского) использовались оригинальные алфавиты. Чтобы пользователям было легче ориентироваться, Яндекс автоматически перевёл иностранные названия городов и популярных туристических мест на русский язык. Перед нами стояла задача перевести с 37 языков более 7 миллионов топонимов из 237 стран.
В этом посте мы подробно расскажем о том, как мы выбирали методы перевода и использовали их на практике.
Сегодняшняя новость — результат полутора лет работы. Мы уже давно поняли, что неправильно рассчитывать только на поставщиков данных и нужны свои карты. Первой стала Москва, нарисованная нашими картографами в 2011 году. Сейчас у нас есть собственные детальные карты России, Украины, Беларуси и Казахстана. Они объединены с подробными картами остальных стран от нашего партнёра, чтобы пользователям было удобно «переходить» границы. Нам нужно было не просто объединить схемы стран, но и организовать хранение и быструю обработку всех данных мировой карты, так что мы полностью переписали ядро сервиса. Кроме того, мы создали своё ПО для быстрого внесения изменений в карты, потому что электронные карты очень важно обновлять часто, а существующие на рынке программы не способны осилить наши объёмы. Яндекс теперь — картографическая компания совершенно нового уровня.
Сначала для того чтобы перевести топонимы на мировой Карте, мы подумали воспользоваться Википедией, ведь в ней есть очень много статей о населенных пунктах с указанием точных координат. Нужно было просто взять заголовок эквивалентной статьи на русском языке, и получить искомый перевод. Статей оказалось действительно много, но для наших нужд – совершенно недостаточно. Пойдя по этому пути, мы смогли покрыть не больше 5-7 процентов топонимов. Стало ясно, что проблему можно решить только самостоятельно, т.е. создать правила транскрипции для каждого из используемых языков. Конечно, лингвисты уже давно решили эту проблему, любой учебник иностранного языка начинается правил чтения. Однако эти правила рассчитаны на человека, соответственно мы должны были подготовить их таким образом, чтобы правилами могла пользоваться машина. А это не так уж просто. К тому же, практически у каждого правила встречаются исключения, которые тоже нужно было учитывать и отслеживать вручную. Не стоит забывать и об устоявшихся вариантах перевода многих топонимов. Например, если мы по правилам транскрипции переведем французское слово Paris на русский, у нас получится «Пари». Но у этого города в русском языке уже есть другое, исторически сложившееся наименование – Париж.
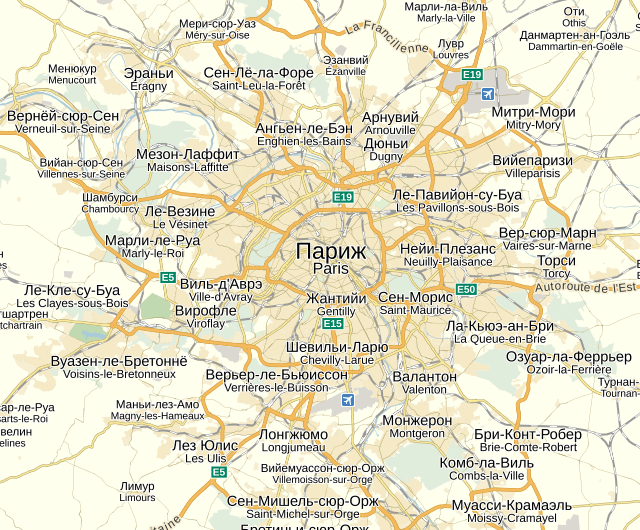
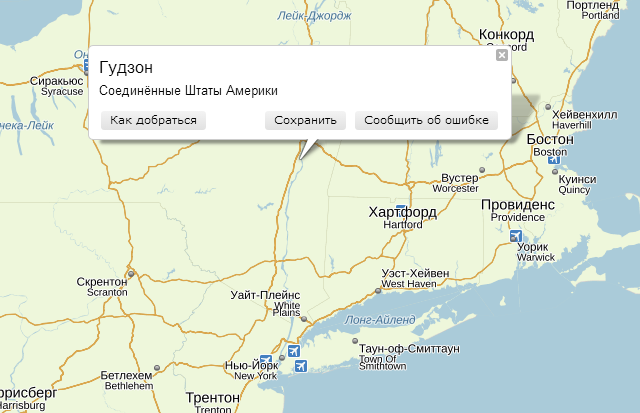
То же самое можно сказать и про реку Гудзон. По-английски это название пишется Hudson. Точно так же как фамилия знаменитой миссис Хадсон – квартирной хозяйки Шерлока Холмса. Написание «Хадсон» – пример фонетического переноса (транскрипции), а историческое «Гудзон», скорее, было получено путем транслитерации – побуквенного переноса. И примеров таких достаточно много, так как фонетический перенос использовался при переводе топонимов далеко не всегда. Кроме того, в некоторых случаях топонимы не подчиняются правилам чтения наиболее распространенного в этой местности языка, так как названия им давались другими народами, проживавшими на той же территории.
Итак, чтобы покрыть всю Мировую карту нам потребовалось перенести правила транскрибирования для 37 языков (плюс различные варианты и диалекты) в понятный компьютеру вид. Правила должны были учитывать контекст: ведь правила чтения той или иной буквы или слога очень часто зависят от того, что находится вокруг, вплоть до межсловных связей.
Когда правила сформулированы, создается скрипт на языке Perl, который с учетом всех правил и контекстов транскрибирует все переданные ему строки. Сначала он разбивает исходное слово на сегменты (группы рядом стоящих букв): отдельные последовательности гласных и согласных. Затем для каждого сегмента выбирается наиболее вероятный вариант транскрипции. Естественно, при этом учитывается контекст: какие сегменты располагаются справа и слева от расшифровываемого участка.
Для разметки используются следующие символы:
Правила выглядят следующим образом:
А на выходе получается вот такой результат:
Результаты работы скрипта тщательно проверяются. Если выявляются серьезные несоответствия и ошибки, добавляются новые правила или исключения из них.
С наибольшими трудностями мы столкнулись при попытке составить набор правил для английского языка. Сформулировать для него простые правила никак не удавалось. А существующие правила практической транскрипции были рассчитаны исключительно на человека, владеющего английской фонетикой. Потребовалось вручную составить обучающую выборку, представляющую собой таблицы языковых пар. Только для британского варианта английского таких пар было подобрано около 70 тысяч. На их основе было создано около 20 000 контекстных правил. Отдельно пришлось дорабатывать выборку под американский вариант английского.
Проверяя исходные данные, мы обнаружили, что на картах Navteq встречаются ошибки в переносе некоторых топонимов на латиницу. Особенно часто это встречалось на картах среднеазиатских стран, где изначально была использована кириллица.
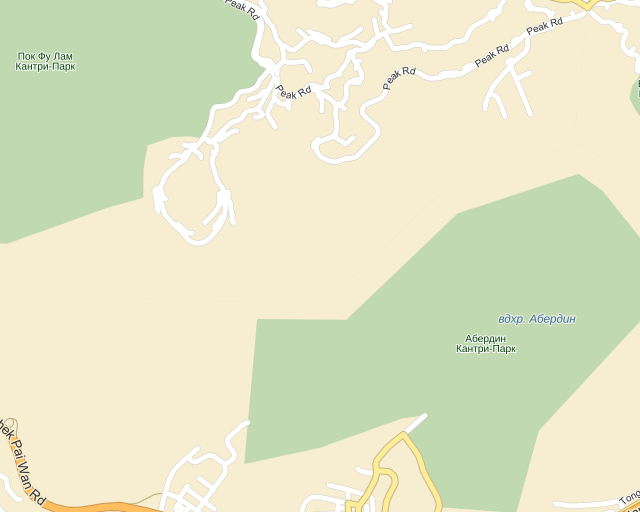
Иногда давали о себе знать последствия колониальной эпохи. Проявлялось это в том, что многие населенные пункты и другие топографические элементы в бывших колониях имеют несвойственные для основного языка страны названия. Например, в Гонконге встречается очень много англицизмов. Когда мы начали транскрибировать местные топонимы по правилам китайского языка, стали всплывать всевозможные артефакты. Там, где должно быть «Абердин Кантри Парк» появлялось «Абердень Цеунтр Парк». Мы были вынуждены создать специальный скрипт, который автоматически отлавливал англицизмы.
В некоторых европейских языках создание формализованных правил транскрипции затрудняет то, что на правила чтения влияет позиция ударения в слове. В имеющихся у нас данных информации об ударениях не было, так что для таких языков приходилось дополнительно создавать правила расстановки ударений.
Благодаря проделанной работе теперь на Мировой карте можно найти даже небольшой населенный пункт в каком-нибудь отдаленном уголке, введя его название по-русски. Но работа еще не завершена, предстоит сделать еще очень многое, чтобы довести функциональность Мировой карты до уровня карты России. Например, мы пока не умеем определять опечатки и неправильные написания топонимов. Кроме того, еще не переведены названия, улиц, площадей, проспектов и т.п. На русском можно посмотреть только названия городских районов. Однако мы надеемся со временем улучшить детализацию.
Кроме того, карты России, Украины, Казахстана и Беларуси теперь полностью принадлежат Яндексу.
Сервис теперь работает на единой платформе, позволяющей поддерживать и самостоятельно обновлять любые объёмы данных. Карты России, Украины, Беларуси и Казахстана обновляют картографы Яндекса каждый месяц. Все остальные страны, схемы которых нарисованы партнёром Яндекса — компанией Navteq, изменяются раз в три месяца.
Детальнее всего на части Navteq выполнены Европа и Северная Америка: со всеми основными улицами и домами в городах и подробной сетью дорог, по которым сервис умеет строить автомобильные маршруты.
Большинство топонимов на картах Navteq было записано латиницей, хотя для некоторых языков (например, тайского и арабского) использовались оригинальные алфавиты. Чтобы пользователям было легче ориентироваться, Яндекс автоматически перевёл иностранные названия городов и популярных туристических мест на русский язык. Перед нами стояла задача перевести с 37 языков более 7 миллионов топонимов из 237 стран.
В этом посте мы подробно расскажем о том, как мы выбирали методы перевода и использовали их на практике.
Сегодняшняя новость — результат полутора лет работы. Мы уже давно поняли, что неправильно рассчитывать только на поставщиков данных и нужны свои карты. Первой стала Москва, нарисованная нашими картографами в 2011 году. Сейчас у нас есть собственные детальные карты России, Украины, Беларуси и Казахстана. Они объединены с подробными картами остальных стран от нашего партнёра, чтобы пользователям было удобно «переходить» границы. Нам нужно было не просто объединить схемы стран, но и организовать хранение и быструю обработку всех данных мировой карты, так что мы полностью переписали ядро сервиса. Кроме того, мы создали своё ПО для быстрого внесения изменений в карты, потому что электронные карты очень важно обновлять часто, а существующие на рынке программы не способны осилить наши объёмы. Яндекс теперь — картографическая компания совершенно нового уровня.
Сначала для того чтобы перевести топонимы на мировой Карте, мы подумали воспользоваться Википедией, ведь в ней есть очень много статей о населенных пунктах с указанием точных координат. Нужно было просто взять заголовок эквивалентной статьи на русском языке, и получить искомый перевод. Статей оказалось действительно много, но для наших нужд – совершенно недостаточно. Пойдя по этому пути, мы смогли покрыть не больше 5-7 процентов топонимов. Стало ясно, что проблему можно решить только самостоятельно, т.е. создать правила транскрипции для каждого из используемых языков. Конечно, лингвисты уже давно решили эту проблему, любой учебник иностранного языка начинается правил чтения. Однако эти правила рассчитаны на человека, соответственно мы должны были подготовить их таким образом, чтобы правилами могла пользоваться машина. А это не так уж просто. К тому же, практически у каждого правила встречаются исключения, которые тоже нужно было учитывать и отслеживать вручную. Не стоит забывать и об устоявшихся вариантах перевода многих топонимов. Например, если мы по правилам транскрипции переведем французское слово Paris на русский, у нас получится «Пари». Но у этого города в русском языке уже есть другое, исторически сложившееся наименование – Париж.
То же самое можно сказать и про реку Гудзон. По-английски это название пишется Hudson. Точно так же как фамилия знаменитой миссис Хадсон – квартирной хозяйки Шерлока Холмса. Написание «Хадсон» – пример фонетического переноса (транскрипции), а историческое «Гудзон», скорее, было получено путем транслитерации – побуквенного переноса. И примеров таких достаточно много, так как фонетический перенос использовался при переводе топонимов далеко не всегда. Кроме того, в некоторых случаях топонимы не подчиняются правилам чтения наиболее распространенного в этой местности языка, так как названия им давались другими народами, проживавшими на той же территории.
Как мы переводили
Итак, чтобы покрыть всю Мировую карту нам потребовалось перенести правила транскрибирования для 37 языков (плюс различные варианты и диалекты) в понятный компьютеру вид. Правила должны были учитывать контекст: ведь правила чтения той или иной буквы или слога очень часто зависят от того, что находится вокруг, вплоть до межсловных связей.
Когда правила сформулированы, создается скрипт на языке Perl, который с учетом всех правил и контекстов транскрибирует все переданные ему строки. Сначала он разбивает исходное слово на сегменты (группы рядом стоящих букв): отдельные последовательности гласных и согласных. Затем для каждого сегмента выбирается наиболее вероятный вариант транскрипции. Естественно, при этом учитывается контекст: какие сегменты располагаются справа и слева от расшифровываемого участка.
Для разметки используются следующие символы:
- правило транскрипции
В круглых скобках - контексты и вероятности
$ - конец слова
^ - начало слова
* - «пустая транскрипция», звук не произносится
// - примечанияПравила выглядят следующим образом:
р(0.95) *(0.03) рь(0.01) ж(0.01) // без контеста
(^)r => р(0.99) ж(0.01) // левый контекст длины 1, ^ - начало слова
r(eu) => р(1.00) // правый контекст длины 1
r(eu l) => р(1.00) // правый контекст длины 2eu => ё(0.39) ой(0.21) эу(0.16) еу(0.14) ей(0.10)
(r)eu => ё(0.55) еу(0.18) ей(0.17) ой(0.10) у(0.10)
eu(l) => ё(0.45) эу(0.30) е(0.20) ей(0.05)
(^ r)eu => ей(0.25) ё(0.25) еу(0.17) ой(0.17) у(0.16)
eu(l eau) => ё(1.00)
l => л(0.86) ль(0.13) *(0.01)
(eu)l => л(0.80) ль(0.20)
l(eau) => л(1.00)
(r eu)l => л(0.50) ль(0.50) // левый контекст длины 2
l(eau x) => л(1.00)
eau => о(0.95) ео(0.02) ау(0.01) эо(0.01) еа(0.01)
(l)eau => о(0.86) ео(0.14)
eau(x) => о(1.00)
(eu l)eau => о(1.00)
eau(x $) => о(1.00)
x => кс(0.52) *(0.24) с(0.21) х(0.03)
(eau)x => *(1.00)
x($) => *(0.59) кс(0.38) х(0.02) с(0.01) // правый контекст длины 1,
(l eau)x => *(1.00) А на выходе получается вот такой результат:
[r eu l eau x] => [р ё л о *] // результат транскрипцииРезультаты работы скрипта тщательно проверяются. Если выявляются серьезные несоответствия и ошибки, добавляются новые правила или исключения из них.
Сложности
С наибольшими трудностями мы столкнулись при попытке составить набор правил для английского языка. Сформулировать для него простые правила никак не удавалось. А существующие правила практической транскрипции были рассчитаны исключительно на человека, владеющего английской фонетикой. Потребовалось вручную составить обучающую выборку, представляющую собой таблицы языковых пар. Только для британского варианта английского таких пар было подобрано около 70 тысяч. На их основе было создано около 20 000 контекстных правил. Отдельно пришлось дорабатывать выборку под американский вариант английского.
Проверяя исходные данные, мы обнаружили, что на картах Navteq встречаются ошибки в переносе некоторых топонимов на латиницу. Особенно часто это встречалось на картах среднеазиатских стран, где изначально была использована кириллица.
Иногда давали о себе знать последствия колониальной эпохи. Проявлялось это в том, что многие населенные пункты и другие топографические элементы в бывших колониях имеют несвойственные для основного языка страны названия. Например, в Гонконге встречается очень много англицизмов. Когда мы начали транскрибировать местные топонимы по правилам китайского языка, стали всплывать всевозможные артефакты. Там, где должно быть «Абердин Кантри Парк» появлялось «Абердень Цеунтр Парк». Мы были вынуждены создать специальный скрипт, который автоматически отлавливал англицизмы.
В некоторых европейских языках создание формализованных правил транскрипции затрудняет то, что на правила чтения влияет позиция ударения в слове. В имеющихся у нас данных информации об ударениях не было, так что для таких языков приходилось дополнительно создавать правила расстановки ударений.
Что дальше?
Благодаря проделанной работе теперь на Мировой карте можно найти даже небольшой населенный пункт в каком-нибудь отдаленном уголке, введя его название по-русски. Но работа еще не завершена, предстоит сделать еще очень многое, чтобы довести функциональность Мировой карты до уровня карты России. Например, мы пока не умеем определять опечатки и неправильные написания топонимов. Кроме того, еще не переведены названия, улиц, площадей, проспектов и т.п. На русском можно посмотреть только названия городских районов. Однако мы надеемся со временем улучшить детализацию.
