
Полтора года назад я выступил на FrontendConf и посвятил 40 минут профилированию. Перечисленные приемы и инструменты по-прежнему актуальны — сегодня публикую видео с подробным конспектом. Доклад расскажет, что такое профилирование, научит локализовывать потенциальные утечки памяти, а также немного углубит ваше понимание инструмента DevTools.
— Всем привет. Меня зовут Артём Несмиянов, я fullstack-разработчик Яндекс.Практикума. И, как видите, сегодня я хочу рассказать о профилировании Node.js, хотя это не совсем фронтендерская тема. Но сейчас очень много приложений используют фронтбэк, где есть свой server-side rendering, где нужно это все отдавать клиенту, и фронтендеру часто приходится взаимодействовать с Node.js. Иногда происходят вещи, которые могут повлиять на ваш сервер, положить его, перегрузить и так далее. С этим надо бороться. Я хочу показать, какие методы использовали мы. Это скорее введение в профилирование Node.js.
Для чего вообще нужно профилирование? В основном для того, чтобы ваш сервер был оптимизирован, чтобы он не кушал много CPU, не потреблял много памяти. Если потребляется много CPU, то потребляется и много денег. Для любого бизнеса это невыгодно. Поэтому нужно всегда следить за своими машинками и стараться, чтобы у них все было очень консистентно и равномерно.
Начнем с ситуации, которая возникла у нас.

Подключив мониторинги, мы увидели, что произошла стандартная проблема: очень сильно скачет memory usage. Это очень плохо для нашего сервиса, нужно что-то делать.
Здесь четыре машины, и выделяемая память постоянно прыгает то вверх, то вниз, вплоть до 4 ГБ. Каким должно быть приложение, чтобы оно использовало 4 ГБ?

Очевидно, что память начинает опускаться вниз, только когда падают машинки. С этим можно жить. Машинка упала, перезапустилась, никто ничего не заметит.
Но на самом деле в этом есть очевидная проблема. При перенагрузке сервера, ответ от него будет довольно долгий. Пользователю нужно ждать три секунды, может отброситься целевая аудитория. И как я уже говорил, это бьет по ресурсам.

CPU тоже ведет себя очень неконсистентно, все выглядит довольно мерзко, с этим нужно что-то делать.
Очевидно, что здесь возникает утечка памяти. Я думаю, нет смысла объяснять в деталях, что это такое — если коротко, это причина, по которой память не возвращается обратно, не освобождается из кучи, вообще не используется. Тем самым приложение просто весит чуть больше.
Почему может возникнуть утечка памяти? В первую очередь из-за случайной глобальной переменной. Также она может возникать из-за ссылок на большие объекты. Также иногда бывает, что к утечкам памяти приводят таймеры и замыкание.
Давайте попробуем пройтись по перечисленным этапам чуть подробнее. Примеры, будут относиться и к фронтенду, и к бэкенду, потому что, как я уже говорил, есть server-side rendering, который также может создавать утечки памяти. Эти же утечки могут плодиться и на сервере, и на фронтенде. Нужно следить за обеими сторонами.

Так вот, случайная глобальная переменная может возникнуть, когда мы в функции просто не объявили переменную. Не указали bar, const или led.
В данном случае произойдет следующее. Он будет присвоен либо к window, если мы на фронтенде, то есть код исполняется в нашем браузере, либо к global на Node.js. Такой элемент никогда не будет удален из памяти. Он будет висеть там вечно, пока мы явно не укажем удалиться данному атрибуту.

Есть основная проблема, которую часто ловят новички при написании кода. Она заключается в том, что вызывается метод класса, его сохранили в другую переменную и вызвали без контекста. Тем самым, this здесь будет тем же самым global или window.
Чтобы этого избежать, есть, конечно, use strict. Он укажет на ваши ошибки. Но иногда бывает, что люди им не пользуются, хотя это довольно плохо.

Еще один из интересных примеров — ссылки на большие объекты. Во фронтенде иногда нужно складывать DOM-элементы к нам в объекты и хранить их там, по ссылкам к ним обращаться.
В React вы можете создать React ref, сложить туда элемент. Допустим, вы захотите его почистить из DOM — конечно, с помощью removeChild. Но у вас все еще будет храниться ссылка на этот объект.
И пока bar не будет почищен или anvar не будет указан как null, этот объект, который может быть очень большим, будет храниться в памяти. Это не очень хорошо. И если вы перестаете что-то использовать, то за такими вещами нужно следить.
В свое время была еще одна популярная ошибка, которая приводила к утечке памяти, — циклические ссылки. Иы можем создать объект, в котором лежит очень большой массив в миллион элементов, и зациклить его самого на себя.

Проблема в том, что раньше это было сделано в виде garbage collection. Это то, что воспроизводится внутри вашего процесса и освобождает всю ненужную информацию, чтобы избавиться от ненужной памяти.

И раньше garbage collection определял, что данный объект в памяти не нужен, только когда на него не было ссылок. На предыдущем слайде элемент замыкал сам себя, на этот же элемент всегда будет одна ссылка. Такой объект, если мы станем его постоянно вызывать, будет просто оставаться в памяти. Это не очень хорошо.
Следующий пример. Мы будем каждую секунду вызывать функцию leak, каждые пять секунд будем пробовать вызывать garbage collection, а после десятой секунды перестанем вызывать функцию leak. Чтобы пользоваться garbage collection, нам нужен флаг —expose-gc для Node.js. Вот что будет происходить:
Там, где есть колоночка JC, видно, что произошел garbage collection. Также есть несколько метрик, о которых я поговорю попозже.
Самая важная здесь метрика — HeapUsed. Видно, что начальный размер приложения — 4 МБ. Далее получается 17 МБ, 23 МБ и так далее. Объект как бы еще хранится в памяти. Но после того как мы числим интервал, все объекты исчезают. Получается, 4 МБ возвращаются обратно. Почему так происходит? На самом деле пример со счетчиком ссылок задействовался раньше.
Недаром я написал IE8, раньше это была популярная ошибка. Сейчас все намного лучше продумано, и есть такой алгоритм сборки мусора, как mark and sweep — помечай и зачищай. Его суть в следующем.
Есть корневое множество элементов, например window. Корневое множество — это то, от чего он будет искать элементы. Очевидно, это window или global, а также все локальные переменные в текущем стеке вызовов.

То есть если в текущий момент срабатывает garbage collection и происходят вызовы, то он возьмет все вызовы, достанет оттуда все переменные, которые может достать, и из этих переменных попытается строить, грубо говоря, BFS, поиск в глубину, поиск в ширину.

Он возьмет корневые элементы, попытается достучаться до всех из них, которые имеют ссылку от корневого элемента, и так далее.
То есть он просто сможет обойти случай, когда есть элементы, которые замыкают друг друга или сами себя, когда ссылок получается одна или более. Да, он немного более затратен по времени, это очень простой счетчик ссылок. Но работает гораздо более эффективно.

Это очень упрощенный алгоритм того, как работает garbage collection. По этим двум ссылкам (1, 2) вы потом можете более подробно познакомиться со всеми методиками.
Основной принцип, который упрощает жизнь garbage collection, — это выделение памяти в новое и старое поколение.
Новое поколение — это объекты, которые были только что созданы через new. Старое поколение — объекты, которые пережили около двух или трех циклов garbage collection. Он на тех элементах будет вызываться гораздо реже. Поэтому под каждое поколение выделена область памяти, и за счет этих поколений он сам понимает, когда ему нужно вызываться.
Но, как я уже сказал, в наших примерах мы будем сами вызывать garbage collection, чтобы явно отслеживать, как была очищена память.
Итак, вернемся к нашим примерам. Еще один из основных багов, когда может плодиться утечка памяти — это, конечно, таймеры. Очевидная проблема в том, что мы просто не освобождаем функцию, когда забываем почистить интервал.
Здесь мы создаем очень большой объект. Создается таймер, который будет делать сложные операции, пытаться реализовывать наш большой array.

Это не самая простая операция, она сама по себе требует дополнительную память, да еще и сам таймер, пока он не окажется освобожден, будет все время содержать в контексте переменную bigBar. Как вы понимаете, пока мы ее не почистим, она будет все время лежать внутри нашей кучи.
Давайте попробуем запустить наш таймер, и в течение 10 секунд ничего не будем делать, посмотрим, что произойдет. Здесь видно, что пока мы не почистим timeout, под этот объект будет потрачено много памяти.

11 мегабайт выделено под наш массив, и видно, что иногда оно выскакивает за 20 мегабайт. Это означает, что как раз JSON.stringify, стерилизация нашего array, тоже в этот момент содержит данные, замыкания, чего-то ей нужно. Но потом она, как видно, успевает их очищать.
То есть JSON.stringify работает более-менее хорошо. А само хранение объектов памяти — не очень хорошо. Если мы когда-то забудем почистить этот таймер, он так и будет висеть. Об этом не нужно забывать. Примерно такая же проблема возникает и в следующем кейсе.

Вот довольно интересный пример. Есть функция outer, тоже создается интервал, и каждый раз в интервале мы сохраняем в переменную res результат функции outer.

Внутри функции outer мы создаем очень большой array и переменную, которая содержит в себе ссылку на предыдущий результат. В первый раз, конечно, это будет undefined, а во второй раз — уже результат выполнения.

Будет ли это вызывать утечки памяти? А если мы добавим сюда вот такую функцию? Все довольно интересно. Давайте для начала посмотрим, что будет.

Каждый раз, когда мы вызываем нашу функцию outer, она создает новый объект. И каждый новый объект будет храниться в памяти, тем самым не давая освобождать еще и предыдущий объект, потому что у нас есть ссылка на предыдущий результат.
Почему так происходит? На самом деле неважно, в какой функции лежали переменные oldRes largeData. Движок V8 просто смотрит на ваш код, собирает все функции, которые могут быть вызваны внутри этой функции, и собирает контекст.

Предположим, здесь была еще одна переменная, которая нигде не использовалась. Если бы вы поставили breakpoint, дошли до этого места, то увидели бы, что там будет стоять Reference Error. Вы не сможете посмотреть, что находится на данном объекте.
Но когда у вас есть хотя бы одна из функций внутри вашей функции, которая использует эту переменную, она будет создавать контекст для всех функций. Вы можете сделать breakpoint внутри этой функции, если она когда-то будет вызвана, посмотреть из контекста на largeData и oldRes, потому что они также будут оставаться внутри контекста.
Это удивительно. С одной стороны, понятно, почему разработчики это взяли. С другой, не очевидно. И нужно просто понимать, как это работает, чтобы не плодить таких штук. Понимать, что иногда функция, которая у вас даже не вызывается, может создать проблемы, утечки памяти.
Конечно, примеры очень синтетические, на продакшене бывает гораздо сложнее найти подобные штуки, но они тоже могут возникать, просто по невнимательности.

Давайте посмотрим, что мы можем сделать, чтобы попрофилировать и подебажить. Какие есть для этого инструменты?
Самый банальный и интересный инструмент, которым злоупотребляют все, — это console.log. На самом деле это очень мощный инструмент.
Особенно фронтендеры любят зафигачить куда-нибудь единичку, двойку, тройку, посмотреть, вызвались ли там эти вызовы, определенные функции, или нет. И, тем самым, понять, где проблема. Да, некогда запускать дебаг-режим, некогда проверять поэтапно. Хотя на самом деле лучше бы это сделать с помощью отладки. Но иногда такая штука бывает очень полезной.
Чтобы все-таки увидеть более интересные инструменты, давайте посмотрим, что еще нам может сделать глобальный объект console.

Мы можем посмотреть Stack trace. У консоли есть встроенный метод Trace, который нам отдаст наш текущий Stack trace, но он будет ограничен неким количеством строк. Это уже будет зависеть от Node.js или от вашего браузера.
У этого подхода есть еще одна проблема — в том, что Stack trace будет отдан как строка. Вы не сможете его распарсить, не сможете получить его как объект и что-то с ним сделать. Но сможете получить его как строку. При желании можно его распарсить. Конечно, этот кейс очень странный, но иногда бывает полезным.

Помимо этого, мы можем использовать newError.stack, указать для Node.js параметр stack-trace-limit и количество строк, которые мы хотим вывести.
Здесь это пока тоже будет являться строкой, но мы можем создать свой генератор Stack trace.

Есть такая штука — prepareStackTrace. Есть даже целый Stack trace API, можно хорошо разобраться в Stack trace, взять конкретные call-сайт объекты, которые позволят достать важную информацию, чтобы ее вводить. Это будет уже не такой Stack trace…
… а гораздо более информативный. Вы сможете описать его как вам угодно — грубо говоря, просто переопределив эти методы. stackTraceLimit — это очевидно, а captureStackTrace тоже собирает для вас Stack trace.
Со Stack trace API вы можете познакомиться по ссылке. Там есть довольно интересные примеры. И в целом, лучше разбираться в том, как правильно и как вообще можно оперировать со Stack trace.

Еще один из очень важных аспектов профилирования и в принципе оценки вашего приложения — это, конечно, тайминг ваших функций. Иногда вам стоит просто замерить ваши функции, убедиться, что они не слишком долгие. Во фронтенде это все используют. Но на бэкенде есть более сложные штуки. О них поговорим чуть дальше. Но есть и гораздо более простые вещи, которые позволяют просто делать console.time и console.timeEnd.
В console.time мы передаем аргумент — имя для нашей группы. Мы просто задаем имя, по которому будет собрана информация. В timeEnd в консоли как раз будет выведена информация о том, сколько времени исполнялась данная функция.
В чем минус такого подхода? Вам придется залезть прямо в код, поставить эти обработчики. Иногда это даже можно сделать, если вы в рантайме зайдете в DevTools и поменяете. Но иногда это накладывает ограничения. Это не очень удобно.
Еще есть проблема с асинхронностью. Если функция, которая генерирует timeEnd, вызывается асинхронно и она может быть вызвана несколько раз, то вы уже не увидите, сколько выполнялся второй запрос. Вы увидите только первый, дальше вам уже ничего не будет выведено.

Есть гораздо более продвинутые API для замеров производительности вашей страницы или Node.js-процесса. Есть те же самые методы, например measure. Он позволяет вам делать то же самое, что time и timeEnd. Timerify — это вообще просто декоратор для вашей функции, который позволит вам сразу же замерить, сколько выполняется ваша функция — то есть не от и до какого-то момента, а полностью.
И есть nodeTiming. Внутри очень много различных методов, таких как loopStart, атрибутов, которые вам, например, могут сказать, когда начался следующий тик вашего land loop. Иногда такие вещи бывают полезны. Например, performance.now, кажется, странной вещью, но она дает вам время того, сколько ваша программа уже работает.
Эти вещи вроде бы не очень нужны, но иногда, как все разработчики, мы любим с чем-то поиграться, понять метрики, узнать, насколько быстро что-то загрузилось. Now с этим хорошо помогает, возьмите на вооружение.
Здесь есть ссылка на performance.hooks. Там очень большой API, много методов, которые позволят вам делать практически все что угодно, замерять все со стороны Node.js. Есть еще обертка для front, где тоже можно смотреть на различные взаимодействия (например, сколько у вас грузилась страница), получать все First Contentful Paints. В общем, все, что вы используете внутри DevTools, можно использовать здесь для измерения производительности.

Еще только у Node есть глобальный объект process. Обычно его используют, чтобы получать переменные окружения. Это самый стандартный его кейс. Но есть еще атрибут memoryUsage, который тоже позволяет получать какую-то информацию. Помните те таблички, которые были при получении наших утечек памяти? Там используются именно эти параметры.
Давайте пройдемся по ним немного более подробно. Как я уже говорил, HeapUsed — это то, сколько памяти было выделено под ваши конкретные объекты. Вы создали массив на миллион символов, под него выделилось, грубо говоря, десять мегабайт. Создали просто ссылочку — выделилось 64 килобайта. Вроде все понятно.
Но heapTotal, размер кучи, всегда оказывается немножко больше, чтобы с этим было просто оперировать в памяти — чтобы было проще выделять объекты, постоянно не выделяя память. Обычно HeapUsed меньше, чем heapTotal. HeapUsed бывает чуть-чуть выше, чем heapTotal, но это очень редкий кейс. Это как раз процесс swapping, момент, когда размер кучи увеличивается.
Есть два других параметра — RSS и external. Они не должны никого заботить, когда вы пытаетесь попрофилировать или подебажить ваши приложения. Но их я тоже немножко затрону.
External — это то, сколько памяти было выделено внутри самого движка. C++ создает объекты для ваших элементов, куда-то завертывает код, а может, создает какие-то строки — все это называется external. Это также хранится в нашей куче.
Про RSS. Есть такое понятие — resident. Это то, сколько ваш процесс весит в памяти. Обычно цифра гораздо больше, потому что ему еще нужно подгрузить все библиотеки, все зависимости и так далее. Как раз RSS вам будет давать общий размер вашего приложения.
Обычно этим не оперируют в профилировании или в дебаггинге, смотрят только на HeapUsed, потому что самый важный тренд — чтобы ваши объекты занимали как можно меньше памяти и чтобы эта характеристика не росла бесконечно много.
Так как все мы фронтендеры, мы не хотим устанавливать себе непонятное дополнительное ПО для профилирования. Нам со всем этим может помочь DevTools. Мы можем спрофилировать Node.js через обычный DevTools, самый понятный для нас инструмент. Но хотелось бы заточиться под то, что он умеет. Давайте пройдемся по тому, что вообще делает DevTools.

В первую очередь, с точки зрения фронтенда мы можем рассматривать и редактировать DOM-элементы, CSS-правила. Не все знают, но можно смотреть все обработчики событий, вот, во вкладочке Event Listeners, которые у нас сейчас повешены на всех DOM-элементах.
Там можно делать очень много всего, я чуть позже приложу несколько ссылочек, в которых показаны скрытые возможности, о них не все знают. Например, можно делать скриншоты ваших элементов, можно сразу же, не вынося в глобальную переменную ваш DOM-элемент, к нему обращаться и так далее.

Панель console. Она довольно тривиальна для использования, но не все пользуются некоторыми фичами.
Например, такими: мы можем посмотреть, какие запросы были отправлены, посмотреть все события, которые могут происходить с XMLHttpRequests. Допустим, мы хотим это делать не во вкладочке network, а здесь.
Можем группировать наши выводы в console, можем сделать Preserve Log, который позволит при переходе на другую страницу или при хэше сохранять нашу console. Это иногда тоже бывает полезно. Можем фильтровать наши сообщения, например, по регулярному выражению.
Также у console есть много различных атрибутов. Например, у console.log, кто не знал, еще есть второй аргумент. Можно даже указать стили для console.log, раскрашивать ваши сообщения, группировать их, делать таблички. Тоже много всего. Но на этом, думаю, нет смысла останавливаться.

Панель Sources — уже более важная для нас панель, которая позволяет зайти в код в рантайме, повесить breakpoint или условный breakpoint.
Условными breakpoint тоже многие почему-то не пользуются. Даже не знают, что если ткнуть правой кнопкой мыши, на строчку, то там можно будет сделать conditional breakpoints и повесить их по определенным условиям, показать, останавливаться на этой точке останова или нет.
Мы можем следить за определенной переменной, можем смотреть текущий call-stack, то есть стек вызовов. Можем посмотреть Scope — то, что находится в контексте на данной строчке. Про Reference Error и наши большие объекты я как раз говорил, что они будут видны внутри контекста.
Также можем вешать breakpoints на определенные события от пользователя. Если пролистать ниже, там будет Event Listeners breakpoints. Туда можно навесить условие вида «по клику сделай точку останова и посмотри, в какую функцию ты попал в данный момент».
Есть еще такая возможность, как Coverage. Позволяет посмотреть, какой код вообще был выполнен, а какой нет. Видно: те строки, которые уже выполнились, помечены зеленым, а которые еще нет — красным.
Например, мы ищем кнопку, на которую не кликнули, и видим, что этот код еще не выполнился. Иногда это бывает удобно, если нужно протестировать компоненты.
То же самое с вашим сервером. Вы можете посмотреть, какой код вообще не выполнился. Иногда бывает легко найти вещи, которые вам, может быть, вообще не нужны.

Раз уж мы пошли по всем панелям, то есть, конечно, панель Network. Мы можем изменять параметры кэширования или пропускной способности, можем вообще уйти в режим офлайн, перейти в throttling нашей сети — например, в 3G. Посмотреть, как будет работать ваш сайт, посмотреть на перфоманс того, как все это выполняется, посмотреть подробную информацию о своем запросе. Как раз для сервера это очень важно — посмотреть, какие хедеры были отправлены, все ли окей.
Если у вас фронтбэк, то обычно может быть сделана какая-то прокси через ваш сервис. Поэтому часто бывает важно понимать все аспекты того, как использовать networking. И, конечно, можно еще фильтровать ваши запросы.

Перейдем дальше. Более важная панель — Performance. Там можно отслеживать все события, происходящие на странице, смотреть, когда используется GPU, смотреть call-stack, который был вызван за определенное время, можно на таймлайне указать.
И можно видеть, сколько времени исполнялся ваш JavaScript-код, сколько времени было выделено на рендеринг. Это такой апогей между двумя вещами: можно смотреть и бэкендовые штуки, и фронтендовые. С фронтендом, думаю, нам всем здесь все понятно.
С бэкендом самая важная часть — это Call Tree. Но когда мы профилируем Node.js, там все-таки нет панели Performance. Там есть другая панель, про которую я расскажу чуть позже.

И, конечно, панель Memory — самая важная, она есть и там, и там. Остановимся на ней более подробно.
В первую очередь в панели Memory можно видеть все, что сейчас находится в памяти. Мы можем найти какой-нибудь элемент. Здесь мне удалось найти в памяти ключи для нашего Intel-объекта, который потом будет переводить наши ключи в нормальные переводы. Видим, сколько он весит.
У нас есть Shallow Size, Retained Size и то, сколько в принципе весит приложение на момент, когда я решил сделать его снепшот.
Есть еще какие-то вкладочки, о них тоже поговорим чуть подробнее. Здесь мы можем смотреть как на фронтенд, и искать там утечки памяти, так и на бэкенд, то есть на Node.js.

Как я уже говорил, есть полезности, о которых не все знают. Можно немного сильнее углубиться в то, как вообще использовать DevTools. Вот две ссылки на proglib и developers.google.com, которые хорошо описывают, чем программисты обычно не пользуются. Почитайте, чтобы легче находить проблемы, легче оперировать этим инструментом.

Вернемся к нашему синтетическому примеру с неявным замыканием. Попробуем попрофилировать.
Для начала нам нужно указать флаг inspect, который нам запустит на web socket соединение, создаст такой мини-сервер, с которым мы можем общаться:
Видим, что наше приложение запустилось, мы можем его попрофилировать, зайдя в браузере в inspect или в chrome://inspect.
Можем его там найти, перейти. Видим, что оно продолжается, можем зайти в кладку Memory и сделать замер нашего приложения. Все как во фронтенде.
Мы сделали замер. Видим, что приложение весит 4,6 МБ. Можем попытаться походить по нашей куче, посмотреть, что там вообще есть. Замеряем еще разок.
Видим, что приложение сильно возросло в памяти. Можем посортировать по Shallow Size и увидеть, что наши элементы массива очень большие, мы нашли их в памяти и можем посмотреть контекст их исполнения, увидеть, что они содержат ссылки на все предыдущие элементы.
Давайте остановимся на метриках Shallow Size и Retained Size.

Shallow Size — это то, сколько весит наш объект. Например, мы нашли наш массив, object elements, который с айдишником 79 983. Он сам весит 800 килобайт, то есть 800 тысяч байт. При удалении у нас удалится 800 килобайт, и это именно сам объект.
А внизу мы видим largeData. Это ссылка на него. Удалив саму ссылку, мы освободим только 64 килобайта. Но при этом есть Retained Size.
Удалив ссылку на него, после garbage collection мы как раз освободим 800 килобайт. То есть Retained Size — это величина, которая будет произведена при удалении вашего объекта из памяти.
Мы видим, что при опускании контекста все ниже Retained Size сильно растет. Если мы удалим oldRes, который находится чуть глубже, он освободит очень много памяти, потому что потеряется ссылка на эти объекты. Тем самым эта память будет не нужна. Garbage collector пройдется с помощью mark and sweep-алгоритма, увидит, что эти данные больше не нужны, и просто очистит их из памяти.
Эти метрики очень важны и удобны, чтобы искать утечки памяти.
Также есть удобный инструмент, который позволяет сравнивать наши наши снепшоты.

Мы можем создать три снепшота — допустим, в промежутке, в начале и в конце.
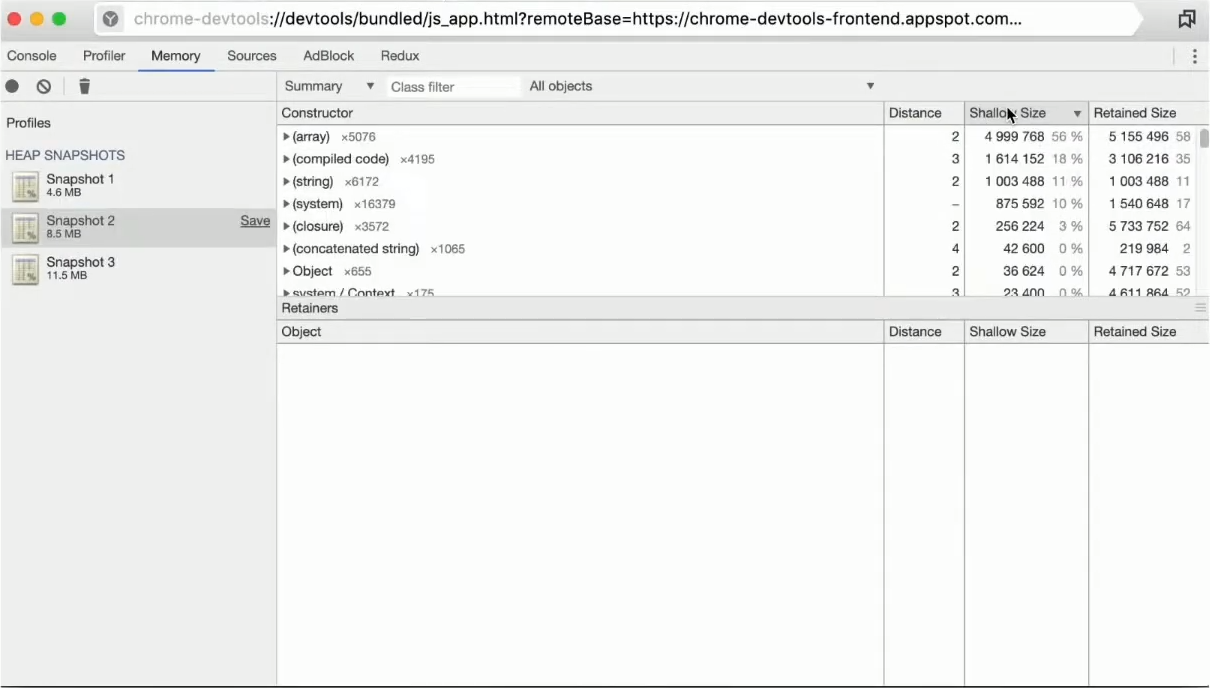
Видим, что при сортировке общий Shallow Size растет. Можем перейти на вкладочку Comparison. Здесь можно сравнивать разные снепшоты друг с другом.
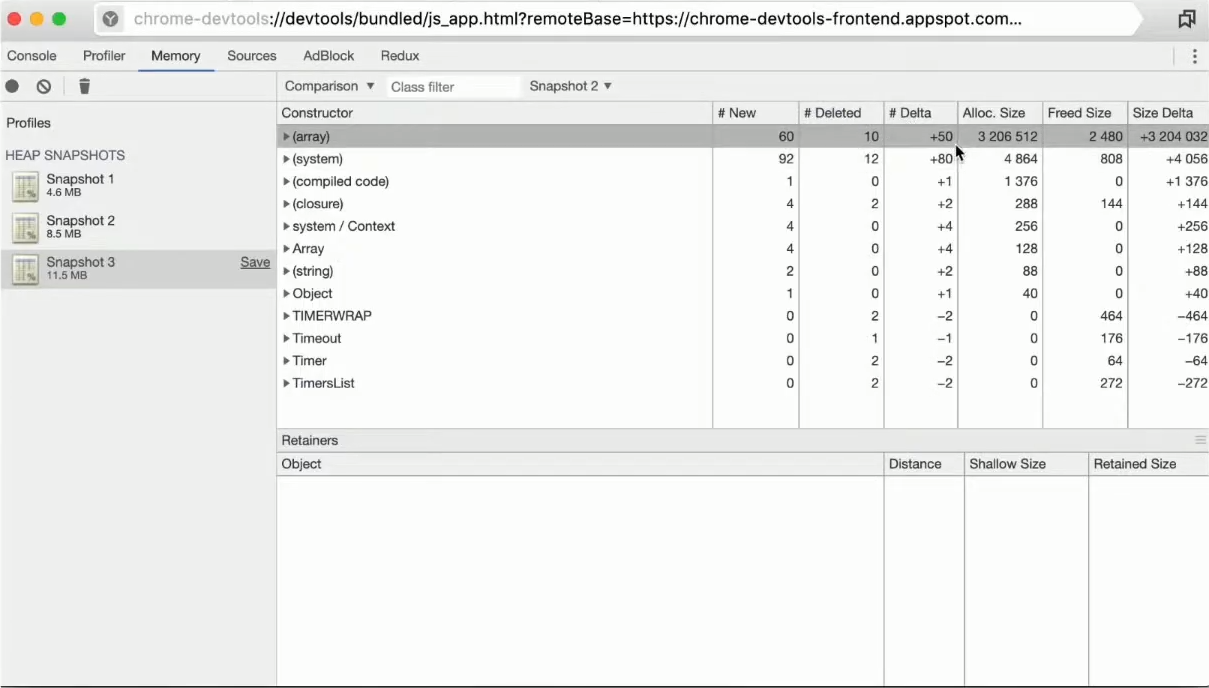
Мы видим то, сколько было создано array, сколько за это время удалено, и общую дельту элементов.
Можем сравнить с первым снепшотом:

Видим, что их гораздо больше, создалось не ровно десять элементов, а еще много всего левого.
Это «левое» генерирует сама Node.js. Да, иногда бывает сложно разобраться, что нам нужно в этом, а что нет, но в таких синтетических примерах это довольно легко.

Видим, что все arrays занимают аж 8 МБ, это не очень хорошо. Здесь также можно перейти и посмотреть весь контекст любых элементов.

Одна из основных полезностей, которые есть у нашего профилировщика, — это CPU Profile. На нем мы не будем долго останавливаться, потому что все, что он делает, — показывает, сколько времени выполнялась ваша функция.
Есть две метрики: Self-Time и Total-Time. Self-Time показывает время исполнения самой функции. То есть если внутри нее вызывались еще какие-нибудь функции, они не берутся в счет. А Total-Time уже показывает время выполнения функции в целом. У вас может быть спокойно создана маленькая функция, обертка, которая передает данные в большую функцию. И эта большая функция вызывается долго. Self-Time у нее будет очень маленький, а Total-Time очень большой. Все понятно. Это бывает полезно, но в случае утечек памяти это практически никогда не помогает.
Мы вооружились инструментом DevTools. Давайте попробуем решить нашу проблему.

Мы делаем снепшот нашего приложения, видим, что он весит 41 МБ. Очевидно, что утечка памяти возникает, только когда мы делаем запрос на сервер.
Давайте вызовем инструмент ab, который в несколько потоков вызовет 100 запросов на ваш сервер:

Видим, что с ростом запросов сильно растет время выполнения ответа, то есть сборки ответа и отдачи сервера. Самый долгий запрос шел 3 с. Это много. Любой пользователь скажет — да идите вы со своим сайтом.
В среднем почти 2 с. Сразу после нескольких первых запросов начала куда-то деваться память. Попробуем найти, куда же она девается.

Делаем еще один снепшот. Видим, что у нас уже 160 мегабайт. Окей, видим, что сильно возросло closure. В предыдущем варианте при размере 41 МБ больше всего strings, наших строк, array. То есть это информация, которая хранится в основном на Node.js, сборках и так далее. Но когда мы провели наши 100 запросов, видим, что стало гораздо больше замыканий. Становится понятно, что эти замыкания остаются в памяти и никуда не исчезают.
Но, побегав по объектам, сложно что-то найти. Какие-то библиотеки могут быть минимизированы, про какие-то объекты просто не понятно, что это такое. Как с этим вообще разбираться?

На помощь приходит еще несколько инструментов, которые есть внутри этого профилировщика. Мы можем воспользоваться таким видом снепшота, как Allocation instrumentation on timeline. Это тот же перформанс, который делает несколько снепшотов по времени выполнения запросов. Также там можно будет получить какой-нибудь таймлайн.

Так это выглядит на бэкенде. А на фронтенде более красивая картинка того, как это все скачет, потому что фронтенд немного проще измерять. В итоге мы получаем вот такую картинку.
Мы можем сдвигать таймлайн и смотреть, какие объекты были выделены за этот промежуток памяти:
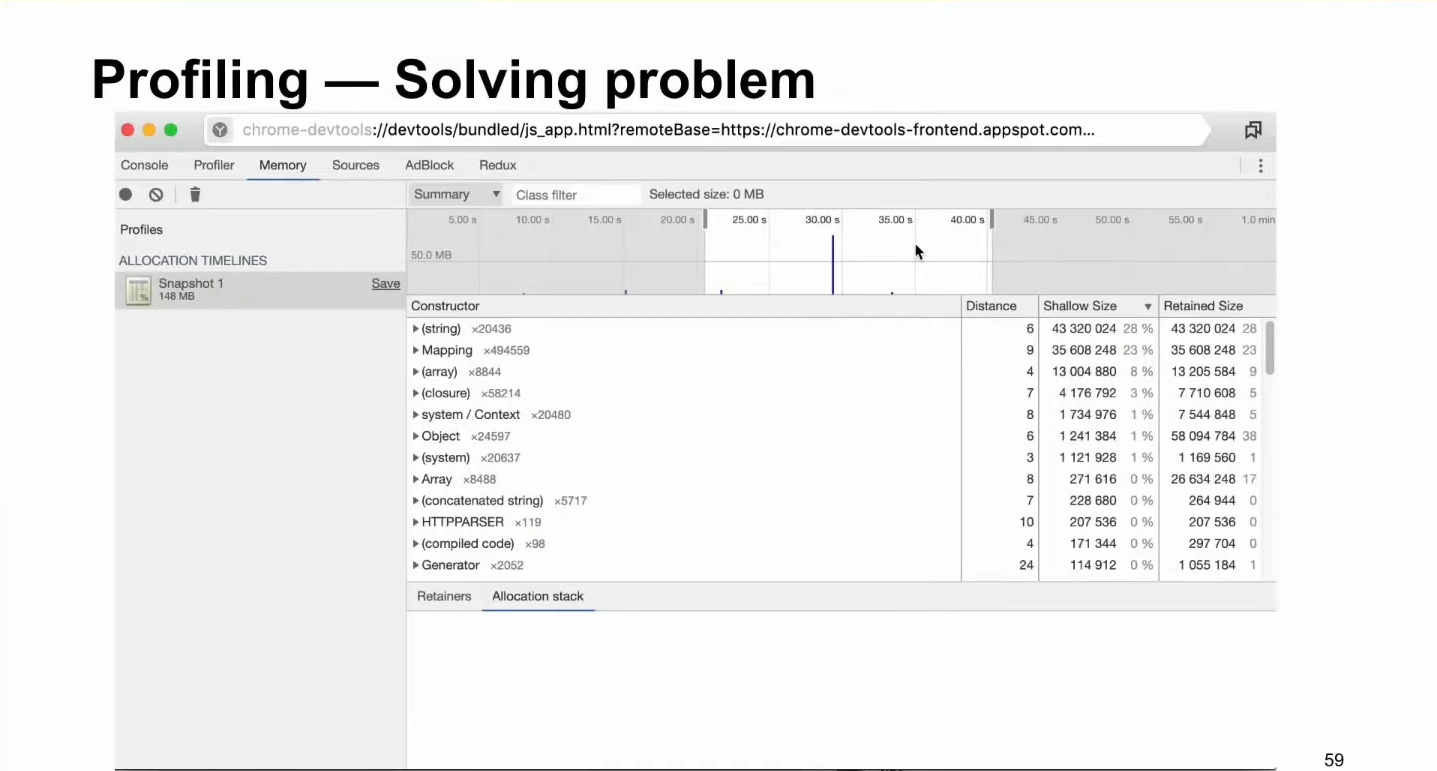
Здесь можно хотя бы примерно понять логику, понять, что конкретно растет.
И мы можем просто выделить конкретный большой объект. Например, сейчас наведем на 99 мегабайт, очень много выделилось. Можем перейти во вкладку Allocation:
Там есть метрики Live Count и Count. Count — это то, сколько есть обращений к нашему файлу, к объектам этого файла. А Live Count — это то, сколько еще осталось жить. Они просто никуда не исчезли.
Есть source map — это понятно, они везде есть. Потом смотрим Redux Saga. Это странно, что она делает на сервере? Смотрим в контексте, находим файлик, который используется на сервере, и видим интересную картину: у нас просто генерируется Redux Saga.
Это, по сути, словарь, который позволяет вам отлавливать события, ваши actions и что-нибудь с ними делать: например, использовать для запросов в сеть. Но в основном они используются для слайд-эффектов. И эта штука на сервере просто не нужна.
Почему-то кто-то из нас не уследил и оставил ее там. Она плодит очень много экземпляров, а сама никуда не исчезает. Можно понять, почему так сделано. Предположим, вы запускаете в браузере страницу, Redux Saga запустилась, и далее она работает, пока вы работаете со страницей. Вы ушли со страницы — все почистилось. Saga не может манипулировать тем, как она запускается, когда ей нужно удаляться и так далее.

Здесь становится очевидно, что просто нужно от Saga избавиться, потому что она не нужна на сервере.
Конечно, есть configureStore, и, как я уже говорил, у нас действует server-side rendering. Мы конфигурируем наш store как на бэкенде, так и на фронтенде. На бэкенде нужно отключить возможность подключения Saga, поэтому мы просто третьим параметром передаем, откуда была вызвана функция configureStore.

Видим, что она вызвана с сервера. В первую очередь мы должны замокать все атрибуты нашего store, связанные с Saga. У нас производится динамическое добавление Saga, мы прямо прямо при компиляции приложения можем добавлять или удалять какие-то Saga. Это очень удобно. Допустим, при переходе с одного bundle на другой иногда нужно подключать новые Saga, чтобы они до этого просто не занимали память.
Мы мокаем с помощью функции saga watchers, запускаем Saga и подключаем все наши нужные методы, только если это не сервер.

И 13 мая в 12 часов дня у нас все становится отлично. Память сильно упала, стала консистентной, перестала расти!

CPU Usage — тоже. Как только мы задеплоились на продакшен, все упало. Ровно в 12 часов. После этого можно было расслабиться.

Что еще хочется сказать? Предположим, вы нашли багу. Как вы обычно ее ловите? Берете все коммиты или пытаетесь вырезать куски кода, посмотреть, есть ли там сейчас утечка памяти, пройти по коммитам бинарным поиском. Но сборка вашего приложения обычно занимает очень много времени. И этот доклад я захотел подготовить именно для того, чтобы просто познакомить вас с возможностями DevTools, чтобы вам было проще пользоваться профилированием ваших Node.js-приложений, находить утечки памяти в вашем коде, локализовывать и избавляться от них. Если бы мне кто-нибудь такое рассказал, я бы потратил намного меньше времени, процентов на 50 точно. Я бы уже знал, где и что искать и как этим оперировать.
Профилируйте ваши приложения. Спасибо.
— Всем привет. Меня зовут Артём Несмиянов, я fullstack-разработчик Яндекс.Практикума. И, как видите, сегодня я хочу рассказать о профилировании Node.js, хотя это не совсем фронтендерская тема. Но сейчас очень много приложений используют фронтбэк, где есть свой server-side rendering, где нужно это все отдавать клиенту, и фронтендеру часто приходится взаимодействовать с Node.js. Иногда происходят вещи, которые могут повлиять на ваш сервер, положить его, перегрузить и так далее. С этим надо бороться. Я хочу показать, какие методы использовали мы. Это скорее введение в профилирование Node.js.
Для чего вообще нужно профилирование? В основном для того, чтобы ваш сервер был оптимизирован, чтобы он не кушал много CPU, не потреблял много памяти. Если потребляется много CPU, то потребляется и много денег. Для любого бизнеса это невыгодно. Поэтому нужно всегда следить за своими машинками и стараться, чтобы у них все было очень консистентно и равномерно.
Начнем с ситуации, которая возникла у нас.
Подключив мониторинги, мы увидели, что произошла стандартная проблема: очень сильно скачет memory usage. Это очень плохо для нашего сервиса, нужно что-то делать.
Здесь четыре машины, и выделяемая память постоянно прыгает то вверх, то вниз, вплоть до 4 ГБ. Каким должно быть приложение, чтобы оно использовало 4 ГБ?
Очевидно, что память начинает опускаться вниз, только когда падают машинки. С этим можно жить. Машинка упала, перезапустилась, никто ничего не заметит.
Но на самом деле в этом есть очевидная проблема. При перенагрузке сервера, ответ от него будет довольно долгий. Пользователю нужно ждать три секунды, может отброситься целевая аудитория. И как я уже говорил, это бьет по ресурсам.
CPU тоже ведет себя очень неконсистентно, все выглядит довольно мерзко, с этим нужно что-то делать.
Очевидно, что здесь возникает утечка памяти. Я думаю, нет смысла объяснять в деталях, что это такое — если коротко, это причина, по которой память не возвращается обратно, не освобождается из кучи, вообще не используется. Тем самым приложение просто весит чуть больше.
Почему может возникнуть утечка памяти? В первую очередь из-за случайной глобальной переменной. Также она может возникать из-за ссылок на большие объекты. Также иногда бывает, что к утечкам памяти приводят таймеры и замыкание.
Давайте попробуем пройтись по перечисленным этапам чуть подробнее. Примеры, будут относиться и к фронтенду, и к бэкенду, потому что, как я уже говорил, есть server-side rendering, который также может создавать утечки памяти. Эти же утечки могут плодиться и на сервере, и на фронтенде. Нужно следить за обеими сторонами.
Так вот, случайная глобальная переменная может возникнуть, когда мы в функции просто не объявили переменную. Не указали bar, const или led.
В данном случае произойдет следующее. Он будет присвоен либо к window, если мы на фронтенде, то есть код исполняется в нашем браузере, либо к global на Node.js. Такой элемент никогда не будет удален из памяти. Он будет висеть там вечно, пока мы явно не укажем удалиться данному атрибуту.
Есть основная проблема, которую часто ловят новички при написании кода. Она заключается в том, что вызывается метод класса, его сохранили в другую переменную и вызвали без контекста. Тем самым, this здесь будет тем же самым global или window.
Чтобы этого избежать, есть, конечно, use strict. Он укажет на ваши ошибки. Но иногда бывает, что люди им не пользуются, хотя это довольно плохо.
Еще один из интересных примеров — ссылки на большие объекты. Во фронтенде иногда нужно складывать DOM-элементы к нам в объекты и хранить их там, по ссылкам к ним обращаться.
В React вы можете создать React ref, сложить туда элемент. Допустим, вы захотите его почистить из DOM — конечно, с помощью removeChild. Но у вас все еще будет храниться ссылка на этот объект.
И пока bar не будет почищен или anvar не будет указан как null, этот объект, который может быть очень большим, будет храниться в памяти. Это не очень хорошо. И если вы перестаете что-то использовать, то за такими вещами нужно следить.
В свое время была еще одна популярная ошибка, которая приводила к утечке памяти, — циклические ссылки. Иы можем создать объект, в котором лежит очень большой массив в миллион элементов, и зациклить его самого на себя.
Проблема в том, что раньше это было сделано в виде garbage collection. Это то, что воспроизводится внутри вашего процесса и освобождает всю ненужную информацию, чтобы избавиться от ненужной памяти.
И раньше garbage collection определял, что данный объект в памяти не нужен, только когда на него не было ссылок. На предыдущем слайде элемент замыкал сам себя, на этот же элемент всегда будет одна ссылка. Такой объект, если мы станем его постоянно вызывать, будет просто оставаться в памяти. Это не очень хорошо.
Следующий пример. Мы будем каждую секунду вызывать функцию leak, каждые пять секунд будем пробовать вызывать garbage collection, а после десятой секунды перестанем вызывать функцию leak. Чтобы пользоваться garbage collection, нам нужен флаг —expose-gc для Node.js. Вот что будет происходить:
Там, где есть колоночка JC, видно, что произошел garbage collection. Также есть несколько метрик, о которых я поговорю попозже.
Самая важная здесь метрика — HeapUsed. Видно, что начальный размер приложения — 4 МБ. Далее получается 17 МБ, 23 МБ и так далее. Объект как бы еще хранится в памяти. Но после того как мы числим интервал, все объекты исчезают. Получается, 4 МБ возвращаются обратно. Почему так происходит? На самом деле пример со счетчиком ссылок задействовался раньше.
Недаром я написал IE8, раньше это была популярная ошибка. Сейчас все намного лучше продумано, и есть такой алгоритм сборки мусора, как mark and sweep — помечай и зачищай. Его суть в следующем.
Есть корневое множество элементов, например window. Корневое множество — это то, от чего он будет искать элементы. Очевидно, это window или global, а также все локальные переменные в текущем стеке вызовов.
То есть если в текущий момент срабатывает garbage collection и происходят вызовы, то он возьмет все вызовы, достанет оттуда все переменные, которые может достать, и из этих переменных попытается строить, грубо говоря, BFS, поиск в глубину, поиск в ширину.
Он возьмет корневые элементы, попытается достучаться до всех из них, которые имеют ссылку от корневого элемента, и так далее.
То есть он просто сможет обойти случай, когда есть элементы, которые замыкают друг друга или сами себя, когда ссылок получается одна или более. Да, он немного более затратен по времени, это очень простой счетчик ссылок. Но работает гораздо более эффективно.
Это очень упрощенный алгоритм того, как работает garbage collection. По этим двум ссылкам (1, 2) вы потом можете более подробно познакомиться со всеми методиками.
Основной принцип, который упрощает жизнь garbage collection, — это выделение памяти в новое и старое поколение.
Новое поколение — это объекты, которые были только что созданы через new. Старое поколение — объекты, которые пережили около двух или трех циклов garbage collection. Он на тех элементах будет вызываться гораздо реже. Поэтому под каждое поколение выделена область памяти, и за счет этих поколений он сам понимает, когда ему нужно вызываться.
Но, как я уже сказал, в наших примерах мы будем сами вызывать garbage collection, чтобы явно отслеживать, как была очищена память.
Итак, вернемся к нашим примерам. Еще один из основных багов, когда может плодиться утечка памяти — это, конечно, таймеры. Очевидная проблема в том, что мы просто не освобождаем функцию, когда забываем почистить интервал.
Здесь мы создаем очень большой объект. Создается таймер, который будет делать сложные операции, пытаться реализовывать наш большой array.
Это не самая простая операция, она сама по себе требует дополнительную память, да еще и сам таймер, пока он не окажется освобожден, будет все время содержать в контексте переменную bigBar. Как вы понимаете, пока мы ее не почистим, она будет все время лежать внутри нашей кучи.
Давайте попробуем запустить наш таймер, и в течение 10 секунд ничего не будем делать, посмотрим, что произойдет. Здесь видно, что пока мы не почистим timeout, под этот объект будет потрачено много памяти.
11 мегабайт выделено под наш массив, и видно, что иногда оно выскакивает за 20 мегабайт. Это означает, что как раз JSON.stringify, стерилизация нашего array, тоже в этот момент содержит данные, замыкания, чего-то ей нужно. Но потом она, как видно, успевает их очищать.
То есть JSON.stringify работает более-менее хорошо. А само хранение объектов памяти — не очень хорошо. Если мы когда-то забудем почистить этот таймер, он так и будет висеть. Об этом не нужно забывать. Примерно такая же проблема возникает и в следующем кейсе.
Вот довольно интересный пример. Есть функция outer, тоже создается интервал, и каждый раз в интервале мы сохраняем в переменную res результат функции outer.
Внутри функции outer мы создаем очень большой array и переменную, которая содержит в себе ссылку на предыдущий результат. В первый раз, конечно, это будет undefined, а во второй раз — уже результат выполнения.
Будет ли это вызывать утечки памяти? А если мы добавим сюда вот такую функцию? Все довольно интересно. Давайте для начала посмотрим, что будет.
Каждый раз, когда мы вызываем нашу функцию outer, она создает новый объект. И каждый новый объект будет храниться в памяти, тем самым не давая освобождать еще и предыдущий объект, потому что у нас есть ссылка на предыдущий результат.
Почему так происходит? На самом деле неважно, в какой функции лежали переменные oldRes largeData. Движок V8 просто смотрит на ваш код, собирает все функции, которые могут быть вызваны внутри этой функции, и собирает контекст.
Предположим, здесь была еще одна переменная, которая нигде не использовалась. Если бы вы поставили breakpoint, дошли до этого места, то увидели бы, что там будет стоять Reference Error. Вы не сможете посмотреть, что находится на данном объекте.
Но когда у вас есть хотя бы одна из функций внутри вашей функции, которая использует эту переменную, она будет создавать контекст для всех функций. Вы можете сделать breakpoint внутри этой функции, если она когда-то будет вызвана, посмотреть из контекста на largeData и oldRes, потому что они также будут оставаться внутри контекста.
Это удивительно. С одной стороны, понятно, почему разработчики это взяли. С другой, не очевидно. И нужно просто понимать, как это работает, чтобы не плодить таких штук. Понимать, что иногда функция, которая у вас даже не вызывается, может создать проблемы, утечки памяти.
Конечно, примеры очень синтетические, на продакшене бывает гораздо сложнее найти подобные штуки, но они тоже могут возникать, просто по невнимательности.
Давайте посмотрим, что мы можем сделать, чтобы попрофилировать и подебажить. Какие есть для этого инструменты?
Самый банальный и интересный инструмент, которым злоупотребляют все, — это console.log. На самом деле это очень мощный инструмент.
Особенно фронтендеры любят зафигачить куда-нибудь единичку, двойку, тройку, посмотреть, вызвались ли там эти вызовы, определенные функции, или нет. И, тем самым, понять, где проблема. Да, некогда запускать дебаг-режим, некогда проверять поэтапно. Хотя на самом деле лучше бы это сделать с помощью отладки. Но иногда такая штука бывает очень полезной.
Чтобы все-таки увидеть более интересные инструменты, давайте посмотрим, что еще нам может сделать глобальный объект console.
Мы можем посмотреть Stack trace. У консоли есть встроенный метод Trace, который нам отдаст наш текущий Stack trace, но он будет ограничен неким количеством строк. Это уже будет зависеть от Node.js или от вашего браузера.
У этого подхода есть еще одна проблема — в том, что Stack trace будет отдан как строка. Вы не сможете его распарсить, не сможете получить его как объект и что-то с ним сделать. Но сможете получить его как строку. При желании можно его распарсить. Конечно, этот кейс очень странный, но иногда бывает полезным.
Помимо этого, мы можем использовать newError.stack, указать для Node.js параметр stack-trace-limit и количество строк, которые мы хотим вывести.
Здесь это пока тоже будет являться строкой, но мы можем создать свой генератор Stack trace.
Есть такая штука — prepareStackTrace. Есть даже целый Stack trace API, можно хорошо разобраться в Stack trace, взять конкретные call-сайт объекты, которые позволят достать важную информацию, чтобы ее вводить. Это будет уже не такой Stack trace…
… а гораздо более информативный. Вы сможете описать его как вам угодно — грубо говоря, просто переопределив эти методы. stackTraceLimit — это очевидно, а captureStackTrace тоже собирает для вас Stack trace.
Со Stack trace API вы можете познакомиться по ссылке. Там есть довольно интересные примеры. И в целом, лучше разбираться в том, как правильно и как вообще можно оперировать со Stack trace.
Еще один из очень важных аспектов профилирования и в принципе оценки вашего приложения — это, конечно, тайминг ваших функций. Иногда вам стоит просто замерить ваши функции, убедиться, что они не слишком долгие. Во фронтенде это все используют. Но на бэкенде есть более сложные штуки. О них поговорим чуть дальше. Но есть и гораздо более простые вещи, которые позволяют просто делать console.time и console.timeEnd.
В console.time мы передаем аргумент — имя для нашей группы. Мы просто задаем имя, по которому будет собрана информация. В timeEnd в консоли как раз будет выведена информация о том, сколько времени исполнялась данная функция.
В чем минус такого подхода? Вам придется залезть прямо в код, поставить эти обработчики. Иногда это даже можно сделать, если вы в рантайме зайдете в DevTools и поменяете. Но иногда это накладывает ограничения. Это не очень удобно.
Еще есть проблема с асинхронностью. Если функция, которая генерирует timeEnd, вызывается асинхронно и она может быть вызвана несколько раз, то вы уже не увидите, сколько выполнялся второй запрос. Вы увидите только первый, дальше вам уже ничего не будет выведено.
Есть гораздо более продвинутые API для замеров производительности вашей страницы или Node.js-процесса. Есть те же самые методы, например measure. Он позволяет вам делать то же самое, что time и timeEnd. Timerify — это вообще просто декоратор для вашей функции, который позволит вам сразу же замерить, сколько выполняется ваша функция — то есть не от и до какого-то момента, а полностью.
И есть nodeTiming. Внутри очень много различных методов, таких как loopStart, атрибутов, которые вам, например, могут сказать, когда начался следующий тик вашего land loop. Иногда такие вещи бывают полезны. Например, performance.now, кажется, странной вещью, но она дает вам время того, сколько ваша программа уже работает.
Эти вещи вроде бы не очень нужны, но иногда, как все разработчики, мы любим с чем-то поиграться, понять метрики, узнать, насколько быстро что-то загрузилось. Now с этим хорошо помогает, возьмите на вооружение.
Здесь есть ссылка на performance.hooks. Там очень большой API, много методов, которые позволят вам делать практически все что угодно, замерять все со стороны Node.js. Есть еще обертка для front, где тоже можно смотреть на различные взаимодействия (например, сколько у вас грузилась страница), получать все First Contentful Paints. В общем, все, что вы используете внутри DevTools, можно использовать здесь для измерения производительности.
Еще только у Node есть глобальный объект process. Обычно его используют, чтобы получать переменные окружения. Это самый стандартный его кейс. Но есть еще атрибут memoryUsage, который тоже позволяет получать какую-то информацию. Помните те таблички, которые были при получении наших утечек памяти? Там используются именно эти параметры.
Давайте пройдемся по ним немного более подробно. Как я уже говорил, HeapUsed — это то, сколько памяти было выделено под ваши конкретные объекты. Вы создали массив на миллион символов, под него выделилось, грубо говоря, десять мегабайт. Создали просто ссылочку — выделилось 64 килобайта. Вроде все понятно.
Но heapTotal, размер кучи, всегда оказывается немножко больше, чтобы с этим было просто оперировать в памяти — чтобы было проще выделять объекты, постоянно не выделяя память. Обычно HeapUsed меньше, чем heapTotal. HeapUsed бывает чуть-чуть выше, чем heapTotal, но это очень редкий кейс. Это как раз процесс swapping, момент, когда размер кучи увеличивается.
Есть два других параметра — RSS и external. Они не должны никого заботить, когда вы пытаетесь попрофилировать или подебажить ваши приложения. Но их я тоже немножко затрону.
External — это то, сколько памяти было выделено внутри самого движка. C++ создает объекты для ваших элементов, куда-то завертывает код, а может, создает какие-то строки — все это называется external. Это также хранится в нашей куче.
Про RSS. Есть такое понятие — resident. Это то, сколько ваш процесс весит в памяти. Обычно цифра гораздо больше, потому что ему еще нужно подгрузить все библиотеки, все зависимости и так далее. Как раз RSS вам будет давать общий размер вашего приложения.
Обычно этим не оперируют в профилировании или в дебаггинге, смотрят только на HeapUsed, потому что самый важный тренд — чтобы ваши объекты занимали как можно меньше памяти и чтобы эта характеристика не росла бесконечно много.
Так как все мы фронтендеры, мы не хотим устанавливать себе непонятное дополнительное ПО для профилирования. Нам со всем этим может помочь DevTools. Мы можем спрофилировать Node.js через обычный DevTools, самый понятный для нас инструмент. Но хотелось бы заточиться под то, что он умеет. Давайте пройдемся по тому, что вообще делает DevTools.
В первую очередь, с точки зрения фронтенда мы можем рассматривать и редактировать DOM-элементы, CSS-правила. Не все знают, но можно смотреть все обработчики событий, вот, во вкладочке Event Listeners, которые у нас сейчас повешены на всех DOM-элементах.
Там можно делать очень много всего, я чуть позже приложу несколько ссылочек, в которых показаны скрытые возможности, о них не все знают. Например, можно делать скриншоты ваших элементов, можно сразу же, не вынося в глобальную переменную ваш DOM-элемент, к нему обращаться и так далее.
Панель console. Она довольно тривиальна для использования, но не все пользуются некоторыми фичами.
Например, такими: мы можем посмотреть, какие запросы были отправлены, посмотреть все события, которые могут происходить с XMLHttpRequests. Допустим, мы хотим это делать не во вкладочке network, а здесь.
Можем группировать наши выводы в console, можем сделать Preserve Log, который позволит при переходе на другую страницу или при хэше сохранять нашу console. Это иногда тоже бывает полезно. Можем фильтровать наши сообщения, например, по регулярному выражению.
Также у console есть много различных атрибутов. Например, у console.log, кто не знал, еще есть второй аргумент. Можно даже указать стили для console.log, раскрашивать ваши сообщения, группировать их, делать таблички. Тоже много всего. Но на этом, думаю, нет смысла останавливаться.
Панель Sources — уже более важная для нас панель, которая позволяет зайти в код в рантайме, повесить breakpoint или условный breakpoint.
Условными breakpoint тоже многие почему-то не пользуются. Даже не знают, что если ткнуть правой кнопкой мыши, на строчку, то там можно будет сделать conditional breakpoints и повесить их по определенным условиям, показать, останавливаться на этой точке останова или нет.
Мы можем следить за определенной переменной, можем смотреть текущий call-stack, то есть стек вызовов. Можем посмотреть Scope — то, что находится в контексте на данной строчке. Про Reference Error и наши большие объекты я как раз говорил, что они будут видны внутри контекста.
Также можем вешать breakpoints на определенные события от пользователя. Если пролистать ниже, там будет Event Listeners breakpoints. Туда можно навесить условие вида «по клику сделай точку останова и посмотри, в какую функцию ты попал в данный момент».
Есть еще такая возможность, как Coverage. Позволяет посмотреть, какой код вообще был выполнен, а какой нет. Видно: те строки, которые уже выполнились, помечены зеленым, а которые еще нет — красным.
Например, мы ищем кнопку, на которую не кликнули, и видим, что этот код еще не выполнился. Иногда это бывает удобно, если нужно протестировать компоненты.
То же самое с вашим сервером. Вы можете посмотреть, какой код вообще не выполнился. Иногда бывает легко найти вещи, которые вам, может быть, вообще не нужны.
Раз уж мы пошли по всем панелям, то есть, конечно, панель Network. Мы можем изменять параметры кэширования или пропускной способности, можем вообще уйти в режим офлайн, перейти в throttling нашей сети — например, в 3G. Посмотреть, как будет работать ваш сайт, посмотреть на перфоманс того, как все это выполняется, посмотреть подробную информацию о своем запросе. Как раз для сервера это очень важно — посмотреть, какие хедеры были отправлены, все ли окей.
Если у вас фронтбэк, то обычно может быть сделана какая-то прокси через ваш сервис. Поэтому часто бывает важно понимать все аспекты того, как использовать networking. И, конечно, можно еще фильтровать ваши запросы.
Перейдем дальше. Более важная панель — Performance. Там можно отслеживать все события, происходящие на странице, смотреть, когда используется GPU, смотреть call-stack, который был вызван за определенное время, можно на таймлайне указать.
И можно видеть, сколько времени исполнялся ваш JavaScript-код, сколько времени было выделено на рендеринг. Это такой апогей между двумя вещами: можно смотреть и бэкендовые штуки, и фронтендовые. С фронтендом, думаю, нам всем здесь все понятно.
С бэкендом самая важная часть — это Call Tree. Но когда мы профилируем Node.js, там все-таки нет панели Performance. Там есть другая панель, про которую я расскажу чуть позже.
И, конечно, панель Memory — самая важная, она есть и там, и там. Остановимся на ней более подробно.
В первую очередь в панели Memory можно видеть все, что сейчас находится в памяти. Мы можем найти какой-нибудь элемент. Здесь мне удалось найти в памяти ключи для нашего Intel-объекта, который потом будет переводить наши ключи в нормальные переводы. Видим, сколько он весит.
У нас есть Shallow Size, Retained Size и то, сколько в принципе весит приложение на момент, когда я решил сделать его снепшот.
Есть еще какие-то вкладочки, о них тоже поговорим чуть подробнее. Здесь мы можем смотреть как на фронтенд, и искать там утечки памяти, так и на бэкенд, то есть на Node.js.
Как я уже говорил, есть полезности, о которых не все знают. Можно немного сильнее углубиться в то, как вообще использовать DevTools. Вот две ссылки на proglib и developers.google.com, которые хорошо описывают, чем программисты обычно не пользуются. Почитайте, чтобы легче находить проблемы, легче оперировать этим инструментом.
Вернемся к нашему синтетическому примеру с неявным замыканием. Попробуем попрофилировать.
Для начала нам нужно указать флаг inspect, который нам запустит на web socket соединение, создаст такой мини-сервер, с которым мы можем общаться:
Видим, что наше приложение запустилось, мы можем его попрофилировать, зайдя в браузере в inspect или в chrome://inspect.
Можем его там найти, перейти. Видим, что оно продолжается, можем зайти в кладку Memory и сделать замер нашего приложения. Все как во фронтенде.
Мы сделали замер. Видим, что приложение весит 4,6 МБ. Можем попытаться походить по нашей куче, посмотреть, что там вообще есть. Замеряем еще разок.
Видим, что приложение сильно возросло в памяти. Можем посортировать по Shallow Size и увидеть, что наши элементы массива очень большие, мы нашли их в памяти и можем посмотреть контекст их исполнения, увидеть, что они содержат ссылки на все предыдущие элементы.
Давайте остановимся на метриках Shallow Size и Retained Size.
Shallow Size — это то, сколько весит наш объект. Например, мы нашли наш массив, object elements, который с айдишником 79 983. Он сам весит 800 килобайт, то есть 800 тысяч байт. При удалении у нас удалится 800 килобайт, и это именно сам объект.
А внизу мы видим largeData. Это ссылка на него. Удалив саму ссылку, мы освободим только 64 килобайта. Но при этом есть Retained Size.
Удалив ссылку на него, после garbage collection мы как раз освободим 800 килобайт. То есть Retained Size — это величина, которая будет произведена при удалении вашего объекта из памяти.
Мы видим, что при опускании контекста все ниже Retained Size сильно растет. Если мы удалим oldRes, который находится чуть глубже, он освободит очень много памяти, потому что потеряется ссылка на эти объекты. Тем самым эта память будет не нужна. Garbage collector пройдется с помощью mark and sweep-алгоритма, увидит, что эти данные больше не нужны, и просто очистит их из памяти.
Эти метрики очень важны и удобны, чтобы искать утечки памяти.
Также есть удобный инструмент, который позволяет сравнивать наши наши снепшоты.
Мы можем создать три снепшота — допустим, в промежутке, в начале и в конце.
Видим, что при сортировке общий Shallow Size растет. Можем перейти на вкладочку Comparison. Здесь можно сравнивать разные снепшоты друг с другом.
Мы видим то, сколько было создано array, сколько за это время удалено, и общую дельту элементов.
Можем сравнить с первым снепшотом:
Видим, что их гораздо больше, создалось не ровно десять элементов, а еще много всего левого.
Это «левое» генерирует сама Node.js. Да, иногда бывает сложно разобраться, что нам нужно в этом, а что нет, но в таких синтетических примерах это довольно легко.
Видим, что все arrays занимают аж 8 МБ, это не очень хорошо. Здесь также можно перейти и посмотреть весь контекст любых элементов.
Одна из основных полезностей, которые есть у нашего профилировщика, — это CPU Profile. На нем мы не будем долго останавливаться, потому что все, что он делает, — показывает, сколько времени выполнялась ваша функция.
Есть две метрики: Self-Time и Total-Time. Self-Time показывает время исполнения самой функции. То есть если внутри нее вызывались еще какие-нибудь функции, они не берутся в счет. А Total-Time уже показывает время выполнения функции в целом. У вас может быть спокойно создана маленькая функция, обертка, которая передает данные в большую функцию. И эта большая функция вызывается долго. Self-Time у нее будет очень маленький, а Total-Time очень большой. Все понятно. Это бывает полезно, но в случае утечек памяти это практически никогда не помогает.
Мы вооружились инструментом DevTools. Давайте попробуем решить нашу проблему.
Мы делаем снепшот нашего приложения, видим, что он весит 41 МБ. Очевидно, что утечка памяти возникает, только когда мы делаем запрос на сервер.
Давайте вызовем инструмент ab, который в несколько потоков вызовет 100 запросов на ваш сервер:
Видим, что с ростом запросов сильно растет время выполнения ответа, то есть сборки ответа и отдачи сервера. Самый долгий запрос шел 3 с. Это много. Любой пользователь скажет — да идите вы со своим сайтом.
В среднем почти 2 с. Сразу после нескольких первых запросов начала куда-то деваться память. Попробуем найти, куда же она девается.
Делаем еще один снепшот. Видим, что у нас уже 160 мегабайт. Окей, видим, что сильно возросло closure. В предыдущем варианте при размере 41 МБ больше всего strings, наших строк, array. То есть это информация, которая хранится в основном на Node.js, сборках и так далее. Но когда мы провели наши 100 запросов, видим, что стало гораздо больше замыканий. Становится понятно, что эти замыкания остаются в памяти и никуда не исчезают.
Но, побегав по объектам, сложно что-то найти. Какие-то библиотеки могут быть минимизированы, про какие-то объекты просто не понятно, что это такое. Как с этим вообще разбираться?
На помощь приходит еще несколько инструментов, которые есть внутри этого профилировщика. Мы можем воспользоваться таким видом снепшота, как Allocation instrumentation on timeline. Это тот же перформанс, который делает несколько снепшотов по времени выполнения запросов. Также там можно будет получить какой-нибудь таймлайн.
Так это выглядит на бэкенде. А на фронтенде более красивая картинка того, как это все скачет, потому что фронтенд немного проще измерять. В итоге мы получаем вот такую картинку.
Мы можем сдвигать таймлайн и смотреть, какие объекты были выделены за этот промежуток памяти:
Здесь можно хотя бы примерно понять логику, понять, что конкретно растет.
И мы можем просто выделить конкретный большой объект. Например, сейчас наведем на 99 мегабайт, очень много выделилось. Можем перейти во вкладку Allocation:
Там есть метрики Live Count и Count. Count — это то, сколько есть обращений к нашему файлу, к объектам этого файла. А Live Count — это то, сколько еще осталось жить. Они просто никуда не исчезли.
Есть source map — это понятно, они везде есть. Потом смотрим Redux Saga. Это странно, что она делает на сервере? Смотрим в контексте, находим файлик, который используется на сервере, и видим интересную картину: у нас просто генерируется Redux Saga.
Это, по сути, словарь, который позволяет вам отлавливать события, ваши actions и что-нибудь с ними делать: например, использовать для запросов в сеть. Но в основном они используются для слайд-эффектов. И эта штука на сервере просто не нужна.
Почему-то кто-то из нас не уследил и оставил ее там. Она плодит очень много экземпляров, а сама никуда не исчезает. Можно понять, почему так сделано. Предположим, вы запускаете в браузере страницу, Redux Saga запустилась, и далее она работает, пока вы работаете со страницей. Вы ушли со страницы — все почистилось. Saga не может манипулировать тем, как она запускается, когда ей нужно удаляться и так далее.
Здесь становится очевидно, что просто нужно от Saga избавиться, потому что она не нужна на сервере.
Конечно, есть configureStore, и, как я уже говорил, у нас действует server-side rendering. Мы конфигурируем наш store как на бэкенде, так и на фронтенде. На бэкенде нужно отключить возможность подключения Saga, поэтому мы просто третьим параметром передаем, откуда была вызвана функция configureStore.
Видим, что она вызвана с сервера. В первую очередь мы должны замокать все атрибуты нашего store, связанные с Saga. У нас производится динамическое добавление Saga, мы прямо прямо при компиляции приложения можем добавлять или удалять какие-то Saga. Это очень удобно. Допустим, при переходе с одного bundle на другой иногда нужно подключать новые Saga, чтобы они до этого просто не занимали память.
Мы мокаем с помощью функции saga watchers, запускаем Saga и подключаем все наши нужные методы, только если это не сервер.
И 13 мая в 12 часов дня у нас все становится отлично. Память сильно упала, стала консистентной, перестала расти!
CPU Usage — тоже. Как только мы задеплоились на продакшен, все упало. Ровно в 12 часов. После этого можно было расслабиться.
Что еще хочется сказать? Предположим, вы нашли багу. Как вы обычно ее ловите? Берете все коммиты или пытаетесь вырезать куски кода, посмотреть, есть ли там сейчас утечка памяти, пройти по коммитам бинарным поиском. Но сборка вашего приложения обычно занимает очень много времени. И этот доклад я захотел подготовить именно для того, чтобы просто познакомить вас с возможностями DevTools, чтобы вам было проще пользоваться профилированием ваших Node.js-приложений, находить утечки памяти в вашем коде, локализовывать и избавляться от них. Если бы мне кто-нибудь такое рассказал, я бы потратил намного меньше времени, процентов на 50 точно. Я бы уже знал, где и что искать и как этим оперировать.
Профилируйте ваши приложения. Спасибо.
