 NUMA (Non-Uniform Memory Access — «Неравномерный доступ к памяти» или Non-Uniform Memory Architecture — «Архитектура с неравномерной памятью») — технология совсем не новая. Я бы даже сказала, что совсем старая. То есть, в терминах музыкальных инструментов, это уже даже не баян, а, скорее, варган.
NUMA (Non-Uniform Memory Access — «Неравномерный доступ к памяти» или Non-Uniform Memory Architecture — «Архитектура с неравномерной памятью») — технология совсем не новая. Я бы даже сказала, что совсем старая. То есть, в терминах музыкальных инструментов, это уже даже не баян, а, скорее, варган.Но, несмотря на это, толковых статей, объясняющих, что это, а главное, как с этим эффективно работать, нет. Данный пост, исправляющий эту ситуацию, предназначен прежде всего для тех, кто ничего не знает про NUMA, но также содержит кое-что интересное и для знатоков-NUMизматов, а главное, он облегчает жизнь мне, инженеру Intel, так как отныне всех интересующихся NUMA русскоязычных разработчиков буду отсылать к нему.
Три Богатыря
И начнем с отрицания отрицания. То есть, посмотрим на Uniform Memory Access (Однородный доступ к памяти), известный также так SMP (Symmetric Multi Processing – Симметричная Многопроцессорная Обработка).
SMP – это архитектура, в которой процессоры соединены с общей системной памятью при помощи шины или подобного соединения)симметрично, и имеют к ней равный однородный доступ. Именно так, как показано на схеме ниже (на примере двух CPU), были устроены все многопроцессорные машины Intel, когда контроллер памяти (MCH/MGCH), больше известный как «Северный Мост» (“NorthBridge”) находился в чипсете.
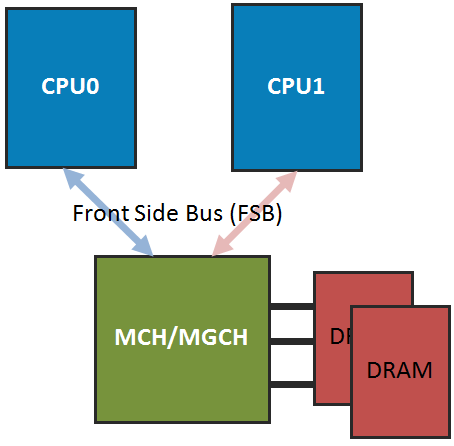
Недостаток SMP очевиден — при росте числа CPU, шина становится узким местом, значительно ограничивая производительность приложений, интенсивно использующих память. Именно поэтому SMP системы почти не масштабируются, два-три десятка процессоров для них – это уже теоретический предел.
Альтернатива SMP для производительных вычислений – это MPP (Massive Parallel Processing).
MPP — архитектура, разделяющая систему на многочисленные узлы, процессоры в которых имеют доступ исключительно к локальным ресурсам. MPP прекрасно масштабируется, но не столь прекрасно программируется. А именно — не обеспечивает встроенного механизма обмена данными между узлами. То есть, реализовывать коммуникации, распределение и планировку задач на узлах должен выполняемый на MPP софт, что подходит далеко не для всех задач и их программистов.
И, наконец, NUMA (Non-Uniform Memory Access). Эта архитектура объединяет положительные черты SMP и MPP. NUMA система разделяется на множественные узлы, имеющие доступ как к своей локальной памяти, так и к памяти других узлов (логично называемой «удаленной»). Естественно, доступ к удаленной памяти оказывается гораздо медленнее, чем к локальной. Оттуда и название – «неоднородный доступ к памяти». Это – не только название, но и недостаток архитектуры NUMA, для смягчения которого может потребоваться специальная оптимизация софта, о которой — дальше.
Вот как выглядит двухсокетная NUMA система Intel Xeon (а именно там дебютировала Intel NUMA) с контроллерами памяти, интегрированными в CPU.
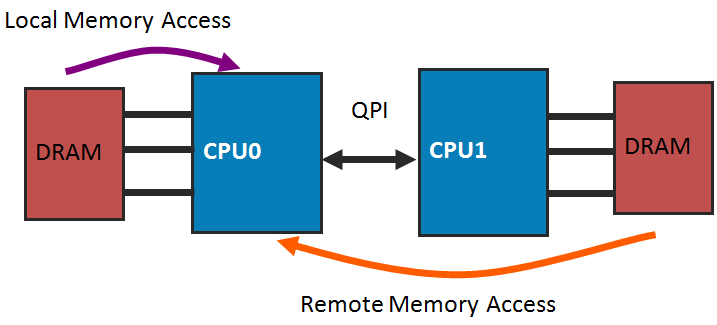
Процессоры здесь соединены QPI — Intel QuickPath соединением «точка-точка» с высокой пропускной способностью и низкой задержкой передачи.
На рисунке не показан кеш процессоров, но все три уровня кеш памяти, конечно же, там есть. А значит, есть и особенность NUMA, о которой необходимо сказать: NUMA, используемая в системах Intel, поддерживает когерентность кешей и разделяемой памяти (то есть, соответствие данных между кешами разных CPU), поэтому ее иногда называют ccNUMA — cache coherent NUMA. Это означает наличие специального аппаратного решения для согласования содержимого кешей, а также и памяти, когда более чем один кеш хранит одну и ту же ее часть. Конечно, такое общение кешей ухудшает общую производительность системы, но без него программировать систему с непредсказуемым текущим состоянием данных было бы крайне
Таким образом, от железа мы плавно перешли к программному обеспечению и производительности NUMA систем.
Итак, NUMA поддерживается следующими OS:
Windows Server 2003, Windows XP 64-bit и Windows Vista – до 64 логических процессоров,
Windows 7, Windows Server 2008 R2 – полная поддержка.
Linux OS kernel: 2.6 и выше, UNIX OS — Solaris и HP-Unix.
Если говорить о базах данных, то NUMA поддерживается Oracle8i, Oracle9i, Oracle10g и Oracle11g, а также SQL Server 2005 и SQL Server 2008.
Поддержка NUMA реализована и в Java SE 6u2, JVM 1.6, а также .NET runtime на вышеупомянутых версиях Windows.
Полностью поддерживает NUMA математическая библиотека Intel – MKL.
«Поддержка NUMA» означает следующее – продукт знает о топологии NUMA машины, на которой исполняется, и пытается использовать ее максимально эффективно, то есть, организовать работу потоков так, чтобы они в полной мере использовали память своего узла (того, на котором исполняется данный поток) и минимально – чужих. Ключевое слово здесь – «пытается», так как сделать это в общем случае возможно не всегда.
Поэтому может случиться, что продукт, не поддерживающий NUMA, то есть, просто не знающий о ней, что совсем не мешает ему запускаться и исполняться на NUMA-системах, покажет не худшую производительность, чем официально поддерживающий NUMA. Пример такого продукта — знаменитая библиотека Intel Threading Building Blocks.
Именно поэтому в BIOS мультисокетных серверов с NUMA есть специальный пункт «Разрешить\запретить NUMA». Конечно же, от запрета NUMA в BIOS топология системы никак не изменится — удаленная память не приблизится. Произойдет только следующее – система не сообщит ОС и ПО о том, что она NUMA, а значит, распределение памяти и планировка потоков будут «обычными», такими как на симметричных многопроцессорных системах.
Если BIOS разрешает NUMA, то операционная система сможет узнать о конфигурации NUMA узлов из System Resource Affinity Table (SRAT) в Advanced Configuration and Power Interface (ACPI). Приложения могут получить такую информацию, используя библиотеку libnuma в Linux, а сами понимаете, на каких системах — Windows NUMA interface.
Эта информация – начало поддержки NUMA вашим приложением. За ним должна следовать непосредственно попытка максимально эффективно использовать NUMA. Общие слова на эту тему уже сказаны, для дальнейших пояснений перейду к частному примеру.
Допустим, вы выделяете память при помощи malloc. Если дело происходит в Linux, то malloc только резервирует память, а ее физическое выделение происходит только при фактическом обращении к данной памяти. В этом случае память автоматически выделится на том узле, который ее и использует, что очень хорошо для NUMA. В Windows же malloc работает по-другому, он выделяет физическую память непосредственно при аллоцировании, то есть, на узле выделяющего память потока. Поэтому она вполне может оказаться удаленной для других потоков, ее использующих. Но есть в Windows и дружественное к NUMA выделение памяти. Это VirtualAlloc, который может работать точно также, как malloc в Linux. Еще более продвинутый вариант — VirtualAllocExNuma из Windows NUMA API.
Следующий простой пример, использующий OpenMP,
main() {
…
#pragma omp parallel
{
//Parallelized TRIAD loop…
#pragma omp parallel for private(j)
for (j=0; j<N; j++)
a[j] = b[j]+scalar*c[j];
} //end omp parallel
…
} //end main
можно подружить с NUMA, обеспечив инициализацию данных каждым потоком, вызывающую соответствующую привязку физической памяти к использующему ее узлу:
KMP_AFFINITY=compact,0,verbose
main() {
…
a* = (char *) VirtualAlloc(NULL, //same for b* and c*
N*(sizeof(double))+1024,
MEM_RESERVE | MEM_COMMIT,
PAGE_READWRITE);
…
#pragma omp parallel
{
#pragma omp for private(i)
for(i=0;i<N;i++)
{ a[i] = 10.0; b[i] = 10.0; c[i] = 10.0;}
…
//OpenMP on TRIAD loop…
#pragma omp parallel for private(j)
for (j=0; j<N; j++)
a[j] = b[j]+scalar*c[j];
} //end omp parallel
…
} //end main
Отдельным пунктом здесь надо упомянуть Affinity — принудительную привязку потоков к конкретным процессорам, предотвращающую возможную переброску операционной системой потоков между процессорами и могущую вызвать потенциальный «отрыв» потоков от своей используемой локальной памяти.
Для установки Affinity имеются соответствующие API как в Linux, так и в Windows ( стандартный Windows API, и NUMA WinAPI). Также функциональность для установки привязки присутствуют во многих параллельных библиотеках (например, в показанном выше примере OpenMP за это отвечает переменная окружения KMP_AFFINITY ).
Но надо понимать, что во-первых, affinity срабатывает не всегда (для системы это, скорее, намек, чем приказ), а во-вторых, положительный эффект от установки Affinity будет только в том случае, когда вы полностью контролируете систему, то есть, на ней работает исключительно ваше приложение, а сама ОС не сильно нагружает систему. Если же, как это чаще всего бывает, приложений несколько, причем, они интенсивно используют CPU и память, пытаясь при этом привязаться к одному процессору, ничего не зная друг о друге, да и ОС конкурирует за те же ресурсы, то от использования Affinity может быть больше вреда, чем пользы
Производительность.
А теперь самое интересное. Попробуем узнать, насколько же в реальности доступ к памяти в NUMA неоднороден, а производительность реальных приложений, соответственно, зависит от этой неоднородности.
Прежде всего, посмотрим теоретические данные. Согласно презентациям Intel, «задержка доступа к удаленной памяти ~ 1.7x доступа к локальной памяти, а пропускная способность локальной памяти может быть до двух раз больше, чем удаленной»
Данные реального сервера на Xeon 5500 приводятся в техническом описании Dell -“задержка доступа к локальной памяти составляет 70 наносекунд, к удаленной – 100 наносекунд (т.е. ~1.4 раза), пропускная способность локальной памяти превосходит удаленную на 40% ”.
На вашей реальной системе эти приблизительные данные могут быть получены при помощи бесплатной утилиты Microsoft Sysinternals — CoreInfo, оценивающей относительную «стоимость» доступа к памяти разных узлов NUMA. Результат, конечно, сильно приблизительный, но некоторые выводы сделать позовляет.
Пример результата Coreinfo:
Calculating Cross-NUMA Node Access Cost...
Approximate Cross-NUMA Node Access Cost (relative to fastest):
00 01
00: 1.0 1.3
01: 1.2 1.0
Но главный вопрос, это насколько разница в «стоимости» доступа к NUMA памяти скажется на производительности реального приложения в целом. При подготовке этой статьи мне попался очень интересный пост специалиста по SQL Linchi Shea, оценивающий влияние NUMA на производительность SQL Server.
Измерения проводились на HP ProLiant 360 G7 с двумя Intel Xeon X5690, дающими в сумме 12 процессоров (24 логических CPU) и представляли собой сравнение двух сценариев работы Microsoft SQL Server 2008 R2 Enterprise X64:
- Использование исключительно локальной памяти (все запросы обрабатываются на первом NUMA узле, в памяти которого лежит тестовая таблица)
- Использование исключительно удаленной памяти (все запросы обрабатываются на втором узле NUMA, с использованием той же таблицы в памяти первого узла.
Тест выполнен исключительно технически грамотно, так что сомневаться в его достоверности не приходится. За деталями отошлю к исходному посту Linchi (на английском).
Здесь же приведу результаты – оценку количества обработки запросов во времени для обоих сценариев:

Как видите, разница составляет всего чуть более 5%! Результат приятно удивительный. И это – случай максимальной разницы, достигаемый при 32 одновременно работающих потоках с запросами (при другом количестве потоков разница еще меньше).
Так нужно ли оптимизировать для NUMA? Зайду издалека. Хотя у меня нет времени убираться дома, зато есть время читать советы по уборке :). И один из полезных, виденных мной советов такой — чтобы меньше убираться, надо избежать потенциального беспорядка, для чего старайтесь хранить все вещи как можно ближе к месту их использования.
Теперь замените «вещи» на «данные», а «квартиру» на «программу» и увидите один из способов достичь порядка в ваших программах. Но это как раз и будет NUMA-оптимизация, о которой вы сейчас и прочли.
