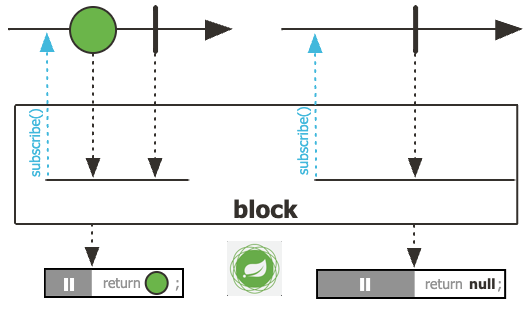
Every programmer is familiar with the concept of "reference." This term usually refers to a small object whose main task is to provide access to another object physically located elsewhere. Because of this, references are convenient to use, they are easily copied, and they make it very easy to access the object to which the reference points, allowing access to the same data from different parts of the program.
Unfortunately, manual memory management, or more precisely, manual memory control, is the most common cause of various errors and vulnerabilities in software. All attempts at automatic memory management through various managers are hampered by the need to control the creation and deletion of objects, as well as periodically run garbage collection, which negatively affects application performance.
However, references in one form or another are supported in all programming languages, although the term often implies not completely equivalent terms. For example, the word "reference" can be understood as a reference as an address in memory (as in C++) and a reference as a pointer to an object (as in Python or Java).
Although there are programming languages that try to solve these problems through the concept of "ownership" (Rust, Argentum, or NewLang). The possible solution to these and other existing problems with references will be discussed further.