
QA Engineer in a Product Company: How I Left Outsourcing and Stopped Panicking Before Releases
6 min
Opinion

From outsourcing to product: a QA engineer’s honest journey to better releases, healthier work culture & real impact on the product.
From outsourcing to product: a QA engineer’s honest journey to better releases, healthier work culture & real impact on the product.

Welcome to my latest article. If you haven't caught my previous ones, I highly recommend checking them out for some really useful content. Today, I'm excited to dive into something special: my top 10 favorite VS Code extensions. These tools are incredibly popular among developers globally, and I believe they're essential for anyone serious about coding.

Every programmer is familiar with the concept of "reference." This term usually refers to a small object whose main task is to provide access to another object physically located elsewhere. Because of this, references are convenient to use, they are easily copied, and they make it very easy to access the object to which the reference points, allowing access to the same data from different parts of the program.
Unfortunately, manual memory management, or more precisely, manual memory control, is the most common cause of various errors and vulnerabilities in software. All attempts at automatic memory management through various managers are hampered by the need to control the creation and deletion of objects, as well as periodically run garbage collection, which negatively affects application performance.
However, references in one form or another are supported in all programming languages, although the term often implies not completely equivalent terms. For example, the word "reference" can be understood as a reference as an address in memory (as in C++) and a reference as a pointer to an object (as in Python or Java).
Although there are programming languages that try to solve these problems through the concept of "ownership" (Rust, Argentum, or NewLang). The possible solution to these and other existing problems with references will be discussed further.
When we are told “There is no thread” we can easily come to an opinion that it is impossible at ALL that asynchronous operation could create thread, but it would be wrong opinion. Simple code example proves the opposite.
Those who are easy to treat the sentence as the universal rule are easy to understand. They would like to simplify the subject and to cut amount of theory they should study and remember. Besides to many it is new level of knowledge to discover there is other layer of classes to manage async-operations behavior beside the Tasks and and SynchronizationContext is only one among them.
Launching a startup often means navigating through stringent constraints, particularly in the early stages where resources are limited. For technical founders, who usually possess deep expertise in certain technical domains, the inclination might be to hire a team of senior engineers—considering you often end up with only one expert in each domain, it might be risky to delegate entire segments to junior specialists.
This situation typically leads to a small team where each member is more skilled than the founder in their respective field. This raises an important question for the technical lead: what role should you play in this team?
While the apparent answer might be task setting and quality control, prompting engineers to do what they love (coding), a less obvious but crucial role emerges. As a leader, your primary responsibility could be to prevent your team from engaging in unnecessary or potentially detrimental tasks, a concept known as "overengineering."
In this article, I will explore the critical role of a technical lead in steering a team away from overengineering and ensuring that their efforts align effectively with the startup's goals and resources.
I wrote a small e-book about terrible tips for C++ developers. Actually, it describes bad programming practices and explains why it's better to avoid them. However, every chapter of this mini-book starts with a terrible tip — just for fun.

By the way, these tips may seem artificial but believe me, they are based on the real experience. In other words, the described terrible tips occur in developers' lives — that's why it's worth discussing them. First of all, this book will be useful for junior developers. But more skilled C++ developers can also find interesting and useful tips.
Even though it's a mini-book, it clearly does not fit into the Habr format. Too many words. So, I decided to write here the review. Here is the link to find the full version of the mini-book: 60 terrible tips for a C++ developer.
If you still hesitate whether to read it or not, below you will find a list of terrible tips that will be discussed in the mini-book.
View the terrible tips:

Faced with situation when had to map STRING VALUE coming from database TO ENUM. The problem happens when value stored in database differs from enum name. And here we need a workaround to make a mapping. I will describe main points on how I was able to realise it.

I have been working in Agile since 2017 in several projects.
And I would like to note here a couple of moments from real experience through the eyes of developer role in project.
Hope it will be helpful for you!
Faced with the situation when calling Mono::block leads to deadlock - in debug I can just see how it stands on Unsafe::park and no more movement at all.

The problem
Unfortunately, when fulfilling their planned business goals, the departments of the organisation rarely take into account such a metric as solution code quality. And usually developers has no time for normal code review process.

This is a translation of my own article
The release of NewLang language with a brand new "feature" is coming, a remodeled version of the preprocessor that allows you to extend the language syntax to create different DSL dialects using macros.
DSL (Subject Oriented Language) is a programming language specialized for a specific application area. It is believed that the use of DSL significantly increases the level of abstractness of the code, and this allows to develop more quickly and efficiently and greatly simplifies the solution of many problems.
We will talk about the second option, namely the implementation of DSL on the basis of general-purpose languages (metalanguages) and the new implementation of macros in NewLang as the basis for DSL development.

Once the Teacher asked the Author:
Are there methods of redundancy introducing at an informational level, other than those that are studied by the theory of error-correcting codes? Emphasizing that he is talking about information redundancy, the Teacher thus made it clear that the question does not imply various ways of energy redundancy introducing, which are well studied in communication theory. After all, the noise immunity of information transmission is traditionally assessed by means of a threshold value that is calculated as the ratio of signal energy to noise energy. It is known that the methods of the theory of error-correcting codes offer an alternative solution, allowing energy saving.
After a cogitative pause, the Author answered in the affirmative, following intuition rather than rational knowledge. Upon hearing the answer, the Teacher noticed that this is a wrong conclusion and there are no such methods.
However, over time, the Author began to suspect that the immutability of the paradigm formulated above could be questioned.

Most influential programmers say that code must be self-documenting. They find comments useful only when working with something uncommon. Our team shares this opinion. Recently we came across a code snippet that perfectly proves it.

Users sometimes ask how new diagnostics appear in the PVS-Studio static analyzer. We answer that we draw inspiration from a variety of sources: books, coding standards, our own mistakes, our users' emails, and others. Recently we came up with an interesting idea of a new diagnostic. Today we decided to tell the story of how it happened.
There is an open project COVID-19 CovidSim Model, written in C++. There is also a PVS-Studio static code analyzer that detects errors very well. One day they met. Embrace the fragility of mathematical modeling algorithms and why you need to make every effort to enhance the code quality.

You may have already read a recent article about the first PVS-Studio run and filtration of warnings. We used the GTK 4 project as an example. It's about time we worked with the received report in more detail. Our regular readers may have already guessed that this article will be a description of errors found in the code.
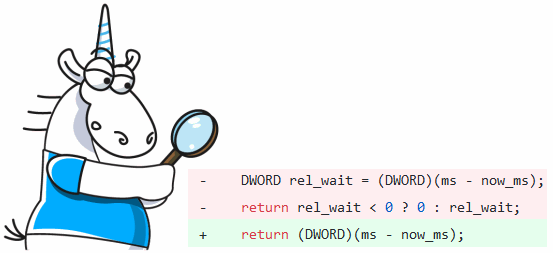

Hey guys! Let me walk you through the next part of our dark-style code academy. In this post, we will discover some other ways how to slow down the reading speed of your code. The next approaches will help you to decrease maintenance and increase a chance to get a bug in your code. Ready? Let's get started.