
SQL *
Domain-specific languageused in programming and designed for managing data held in a relational database management system, or for stream processing in a relational data stream management system

Building Flame Diagram for MSSQL stored procedures

If your code has many nested executions of stored procedures, you can benefit from building popular "flame diagram" of the execution time which is de facto standard for performance profiling.
PostgreSQL 18: Part 2 or CommitFest 2024-09

Statistically, September CommitFests feature the fewest commits. Apparently, the version 18 CommitFest is an outlier. There are many accepted patches and many interesting new features to talk about.
If you missed the July CommitFest, get up to speed here: 2024-07.
How can a manual tester understand an automation tester, and vice versa?

When we go abroad for vacation or meet a foreigner on the street who doesn’t speak Russian but is trying to ask, “Where is the restroom? How do I get to…”, we wonder how to explain things to them in Russian in a way they would understand.
I asked myself a similar question when trying to explain something to a colleague using SQL while they were working with Java. The main goal of my work was to create a quality test model. Without it, there would be no proper regression testing later on.
I started by building a framework filling it with test cases. We held a meeting where we discussed priority of positive and negative test cases briefly. When developing the test scenarios, I used the incremental model, but as practice showed, this approach also required an iterative method. For example, it is like having the outline of the Mona Lisa first, then adding colors, painting the background, and so on.
It’s better to maintain the checklist in Excel format to add columns, write notes, and more. And let’s not forget that, as we take on the role of Leonardo da Vinci, we use different colors and get creative.
I am a manager by profession specializating in Production Management. My motivator is the Theory of Constraints (TOC) methodology, which focuses on identifying and managing the key constraint of a system to determine the efficiency of the entire system as a whole:
PostgreSQL 18: Part 1 or CommitFest 2024-07

This article is the first in the series about the upcoming PostgreSQL 18 release. Let us take a look at the features introduced in the July CommitFest.
Planner: Hash Right Semi Join support
Planner: materializing an internal row set for parallel nested loop join
Planner support functions for generate_series
EXPLAIN (analyze): statistics for Parallel Bitmap Heap Scan node workers
Functions min and max for composite types
Parameter names for regexp* functions
Debug mode in pgbench
pg_get_backend_memory_contexts: column path instead of parent, new column type
Function pg_get_acl
pg_upgrade: pg_dump optimization
Predefined role pg_signal_autovacuum_worker
PostgreSQL 17: Part 5 or CommitFest 2024-03

Since the PostgreSQL 17 RC1 came out, we are on a home run towards the official PostgreSQL release, scheduled for September 26, 2024.
Let's take a look at the patches that came in during the March CommitFest.

Evaluating Performance: CosmosDB vs. Azure SQL

In the evolving landscape of database technology, choosing the right database management system is crucial for the efficiency and scalability of applications. This article presents a detailed comparison of the performance between Microsoft's CosmosDB and MS SQL Server. We'll examine how each database performs under various load conditions and share some interesting findings.
PostgreSQL 17: Part 3 or Commitfest 2023-11

The November commitfest is ripe with new interesting features! Without further ado, let's proceed with the review.
If you missed our July and September commitfest reviews, you can check them out here: 2023-07, 2023-09.
ON LOGIN trigger
Event triggers for REINDEX
ALTER OPERATOR: commutator, negator, hashes, merges
pg_dump --filter=dump.txt
psql: displaying default privileges
pg_stat_statements: track statement entry timestamps and reset min/max statistics
pg_stat_checkpointer: checkpointer process statistics
pg_stats: statistics for range type columns
Planner: exclusion of unnecessary table self-joins
Planner: materialized CTE statistics
Planner: accessing a table with multiple clauses
Index range scan optimization
dblink, postgres_fdw: detailed wait events
Logical replication: migration of replication slots during publisher upgrade
Replication slot use log
Unicode: new information functions
New function: xmltext
AT LOCAL support
Infinite intervals
ALTER SYSTEM with unrecognized custom parameters
Building the server from source
PostgreSQL 17: Part 2 or Commitfest 2023-09

We continue to follow the news of the PostgreSQL 17 development. Let's find out what the September commitfest brings to the table.
If you missed our July commitfest review, you can check it out here: 2023-07.
Removed the parameter old_snapshot_threshold
New parameter event_triggers
New functions to_bin and to_oct
New system view pg_wait_events
EXPLAIN: a JIT compilation time counter for tuple deforming
Planner: better estimate of the initial cost of the WindowAgg node
pg_constraint: NOT NULL constraints
Normalization of CALL, DEALLOCATE and two-phase commit control commands
unaccent: the target rule expressions now support values in quotation marks
COPY FROM: FORCE_NOT_NULL * and FORCE_NULL *
Audit of connections without authentication
pg_stat_subscription: new column worker_type
The behaviour of pg_promote in case of unsuccessful switchover to a replica
Choosing the disk synchronization method in server utilities
pg_restore: optimization of parallel recovery of a large number of tables
pg_basebackup and pg_receivewal with the parameter dbname
Parameter names for a number of built-in functions
psql: \watch min_rows
UX Designer Job Interview: 10 questions to answer, 5 questions to ask

No matter how many degrees you have or how high your experience level is, your recruiters need to evaluate your knowledge of UX design as a whole. But keep in mind that a job interview is not an exam, so here you are expected not to recite the textbook definitions learned by heart, but rather share your personal understanding of UX and your role as a designer in general. Consider talking about how you define UX, what creates value in the design, what are the necessary parts of a UX design process, what are the current trends in UX. You might also be asked to explain the difference between UI and UX to see how you understand the role of each in the development process.
MSSQL: Table Rebuild and Reorg in highload 24/7 Environments

How do you deal with index fragmentation if your SQL server is working in high load environment with 24/7 workload without any maintenance window? What are the best practices for index rebuild and index reorganize? What is better? What is possible if you have only Standard Edition on some servers? But first, let's debunk few myths.
Myth 1. We use SSD (or super duper storage), so we should not care about the fragmentation. False. Index rebuild compactifies a table, with compression it makes it sometimes several times smaller, improving the cache hits ratio and overall performance (this happens even without compression).
Myth 2. Index rebuild shorten SSD lifespan. False. One extra write cycle is nothing for the modern SSDs. If your tempdb is on SSD/NVMe, it is under much harder stress than data disks.
Myth 3. On Enterprise Edition there is a good option: ONLINE=ON, so I just create a script with all tables and go ahead. False. There are tons of potential problems created by INDEX REBUILD even with ONLINE and RESUMABLE ON - so never run index rebuilds without controlling the process.
Finally, we will tackle the REBUILD vs REORGANIZE subject and what is possible to achieve if you have only Standard Edition.
PostgreSQL 17: Part 1 or Commitfest 2023-07

We continue to follow the news in the world of PostgreSQL. The PostgreSQL 16 Release Candidate 1 was rolled out on August 31. If all is well, PostgreSQL 16 will officially release on September 14.
What has changed in the upcoming release after the April code freeze? What's getting into PostgreSQL 17 after the first commitfest? Read our latest review to find out!
How to partition a MySQL table

Alright, folks! Get ready to dive into the world of MySQL table partitioning. In this guide, we'll cover why partitioning is so darn important for your MySQL tables. Plus, we'll dish out all the juicy benefits you can expect from partitioning a table. So, buckle up, and let's get started!
PostgreSQL 16: Part 5 or CommitFest 2023-03

The end of the March Commitfest concludes the acceptance of patches for PostgreSQL 16. Let’s take a look at some exciting new updates it introduced.
I hope that this review together with the previous articles in the series (2022-07, 2022-09, 2022-11, 2023-01) will give you a coherent idea of the new features of PostgreSQL 16.

Database selection cheat sheet: SQL or NoSQL?
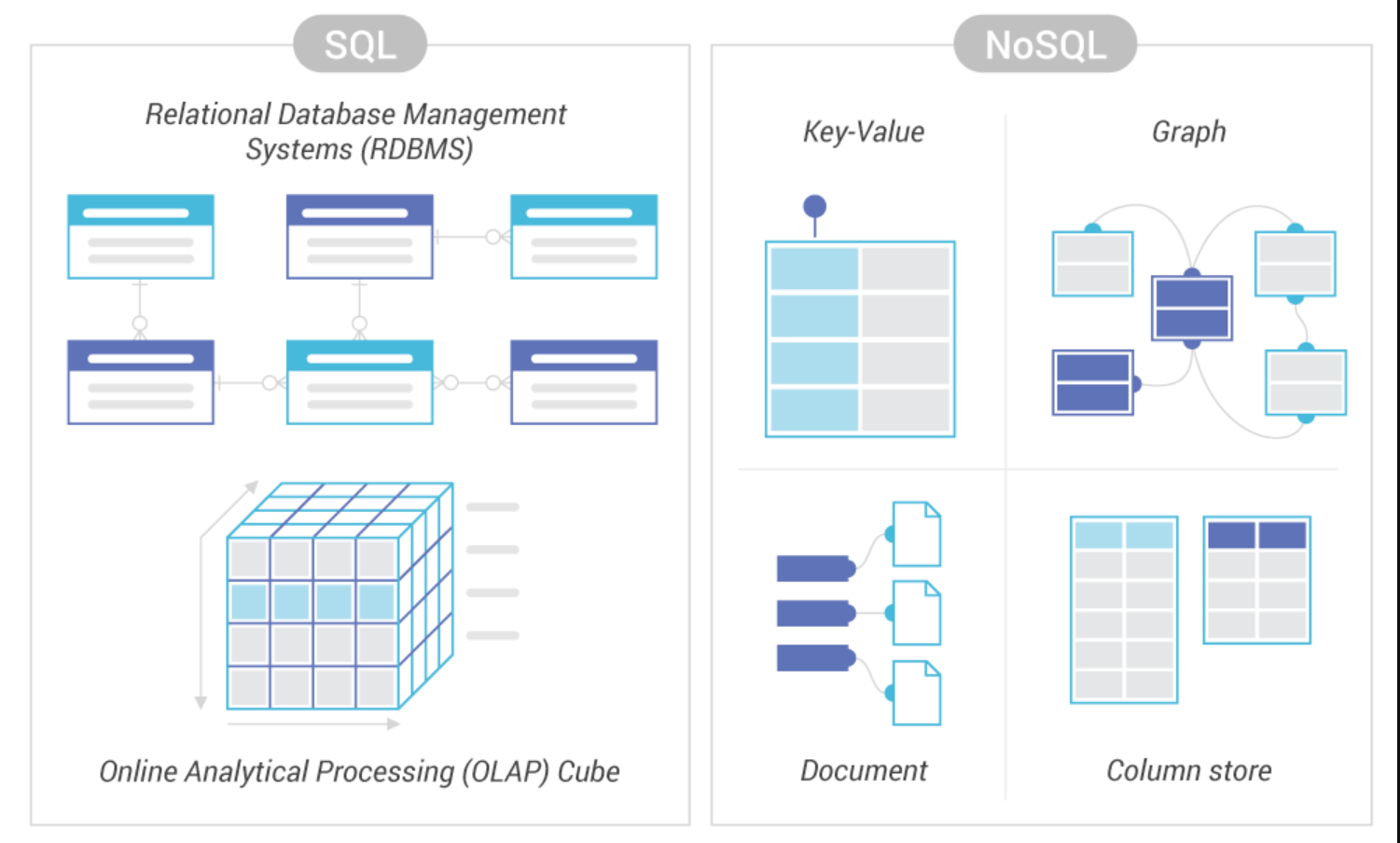
This is a series of articles dedicated to the optimal choice between different systems on a real project or an architectural interview.
This topic seemed relevant to me because such tasks can be encountered both at work and at an interview for System Design Interview and you will have to choose between these two types of DBMS. I plunged into this issue and will tell you what and how. What is better in each case, what are the advantages and disadvantages of these systems and which one to choose, I will show with several examples at the end of the article.
SQL or NoSQL?
PostgreSQL 16: Part 3 or CommitFest 2022-11

We continue to follow the news of the upcoming PostgreSQL 16. The third CommitFest concluded in early December. Let's look at the results.
If you missed the previous CommitFests, check out our reviews: 2022-07, 2022-09.
Here are the patches I want to talk about:
meson: a new source code build system
Documentation: a new chapter on transaction processing
psql: \d+ indicates foreign partitions in a partitioned table
psql: extended query protocol support
Predicate locks on materialized views
Tracking last scan time of indexes and tables
pg_buffercache: a new function pg_buffercache_summary
walsender displays the database name in the process status
Reducing the WAL overhead of freezing tuples
Reduced power consumption when idle
postgres_fdw: batch mode for COPY
Modernizing the GUC infrastructure
Hash index build optimization
MAINTAIN ― a new privilege for table maintenance
SET ROLE: better role change management
Support for file inclusion directives in pg_hba.conf and pg_ident.conf
Regular expressions support in pg_hba.conf
PostgreSQL 16: Part 2 or CommitFest 2022-09

It's official! PostgreSQL 15 is out, and the community is abuzz discussing all the new features of the fresh release.
Meanwhile, the October CommitFest for PostgreSQL 16 had come and gone, with its own notable additions to the code.
If you missed the July CommitFest, our previous article will get you up to speed in no time.
Here are the patches I want to talk about:
SYSTEM_USER function
Frozen pages/tuples information in autovacuum's server log
pg_stat_get_backend_idset returns the actual backend ID
Improved performance of ORDER BY / DISTINCT aggregates
Faster bulk-loading into partitioned tables
Optimized lookups in snapshots
Bidirectional logical replication
pg_auth_members: pg_auth_members: role membership granting management
pg_auth_members: role membership and privilege inheritance
pg_receivewal and pg_recvlogical can now handle SIGTERM
Queries in PostgreSQL. Nested Loop

So far we've discussed query execution stages, statistics, and the two basic data access methods: Sequential scan and Index scan.
The next item on the list is join methods. This article will remind you what logical join types are out there, and then discuss one of three physical join methods, the Nested loop join. Additionally, we will check out the row memoization feature introduced in PostgreSQL 14.