
Заметки о SQL и реляционной алгебре
12 мин
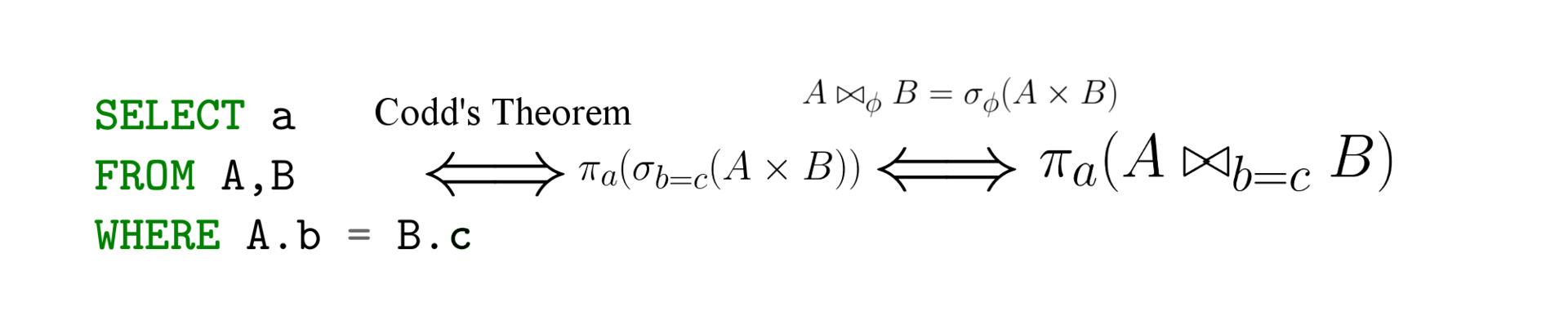
На Хабре и за его пределами часто обсуждают реляционную алгебру и SQL, но далеко не так часто акцентируют внимание на связи между этими формализмами. В данной статье мы отправимся к самым корням теории запросов: реляционному исчислению, реляционной алгебре и языку SQL. Мы разберем их на простых примерах, а также увидим, что бывает полезно переключаться между формализмами для анализа и написания запросов.
Зачем это может быть нужно сегодня? Не только специалистам по анализу данных и администраторам баз данных приходится работать с данными, фактически мало кому не приходится что-то извлекать из (полу-)структурированных данных или трансформировать уже имеющиеся. Для того, чтобы иметь хорошее представление почему языки запросов устроены определенным образом и осознанно их использовать нужно разобраться с ядром, лежащим в основе. Об этом мы сегодня и поговорим.
Большую часть статьи составляют примеры с вкраплениями теории. В конце разделов приведены ссылки на дополнительные материалы, а для заинтересовавшихся и небольшая подборка литературы и курсов в конце.
Содержание
 Есть три агрегатные функции, которые чаще всего используются на практике: COUNT, SUM и AVG.
Есть три агрегатные функции, которые чаще всего используются на практике: COUNT, SUM и AVG.



 Недавно выдалась минутка посмотреть почему старый тестовый сервер безбожно тормозил… К нему я не имел никакого отношения, но меня одолевал спортивный интерес разобраться, что с ним не так.
Недавно выдалась минутка посмотреть почему старый тестовый сервер безбожно тормозил… К нему я не имел никакого отношения, но меня одолевал спортивный интерес разобраться, что с ним не так.
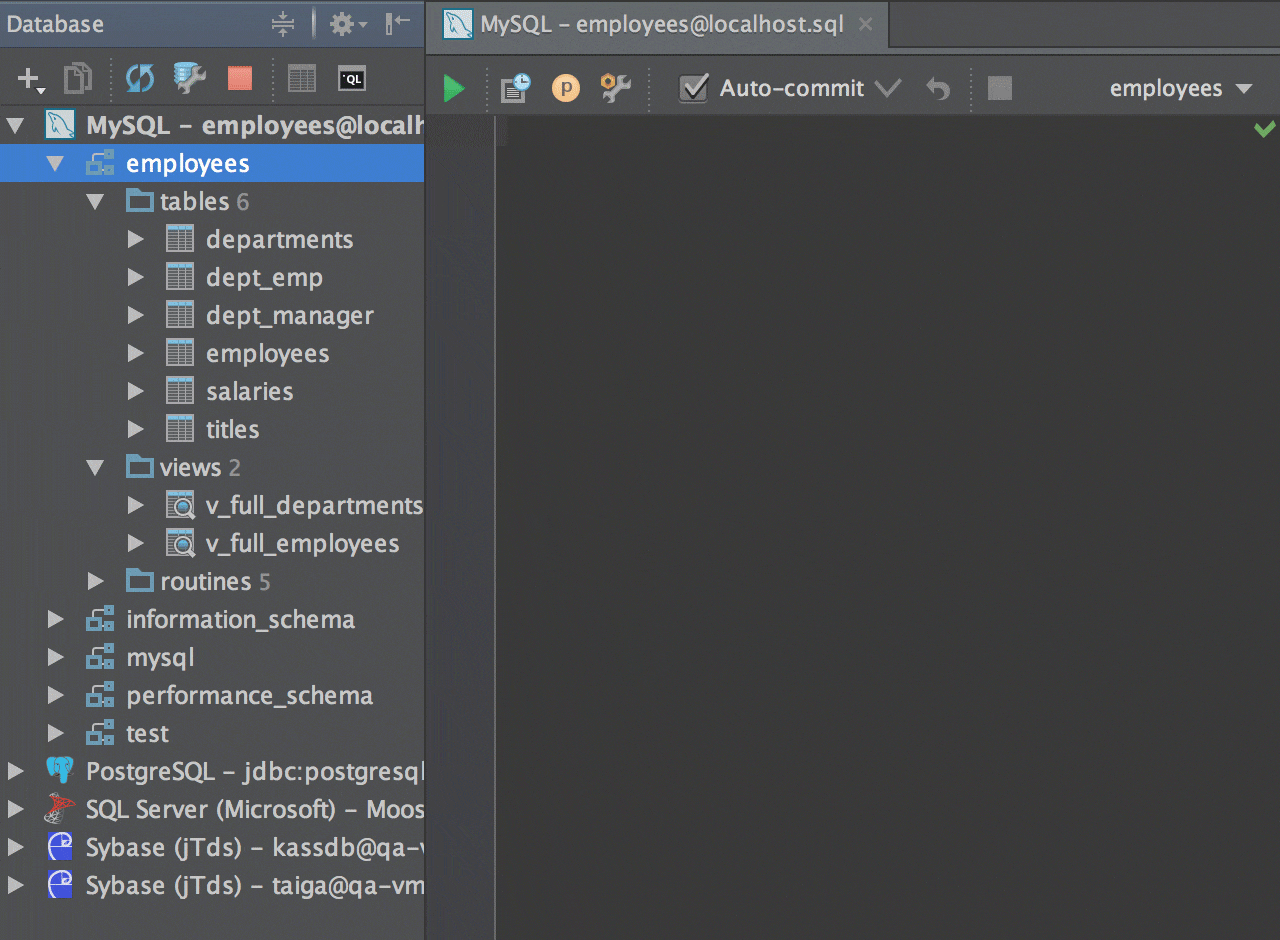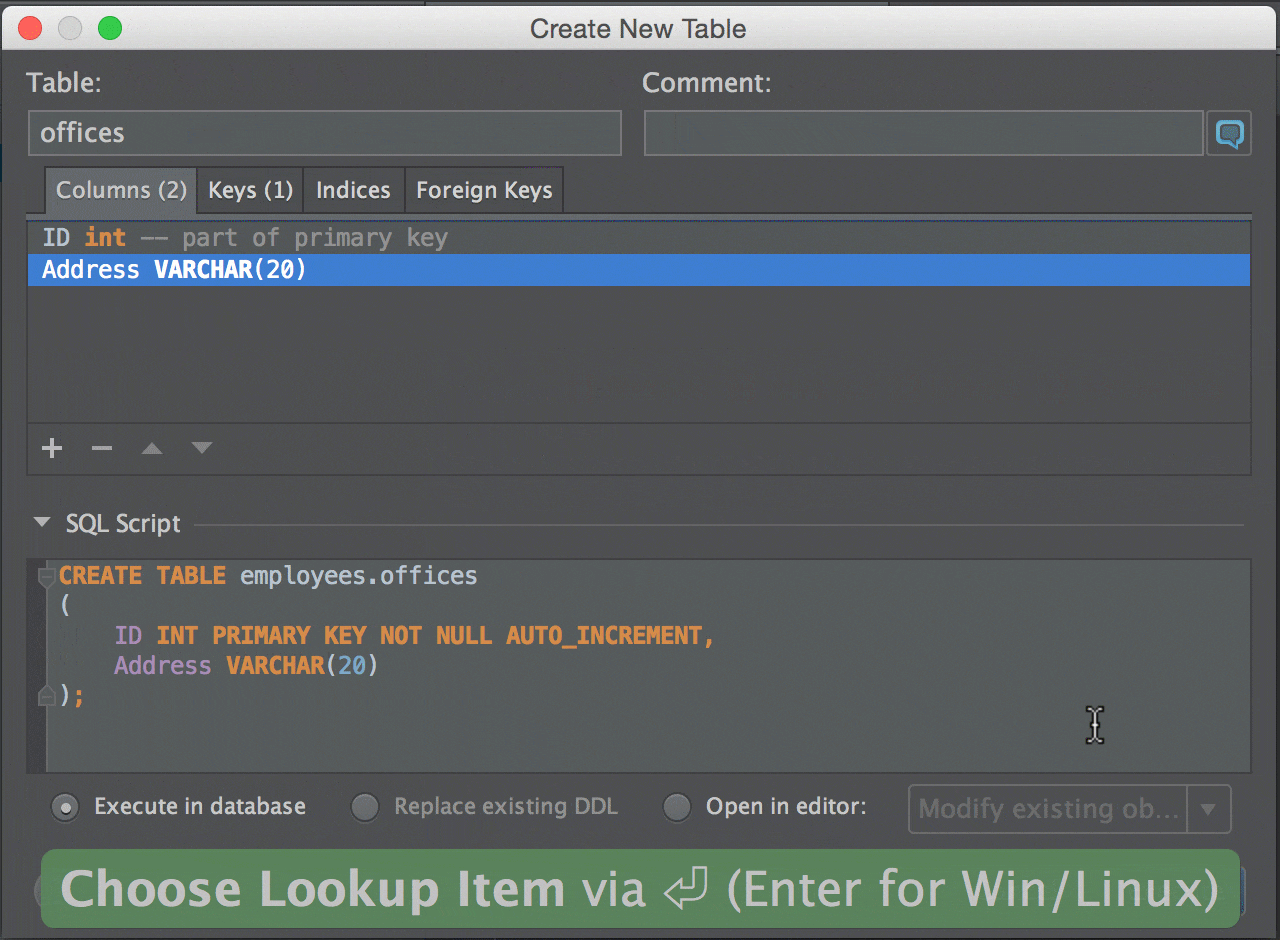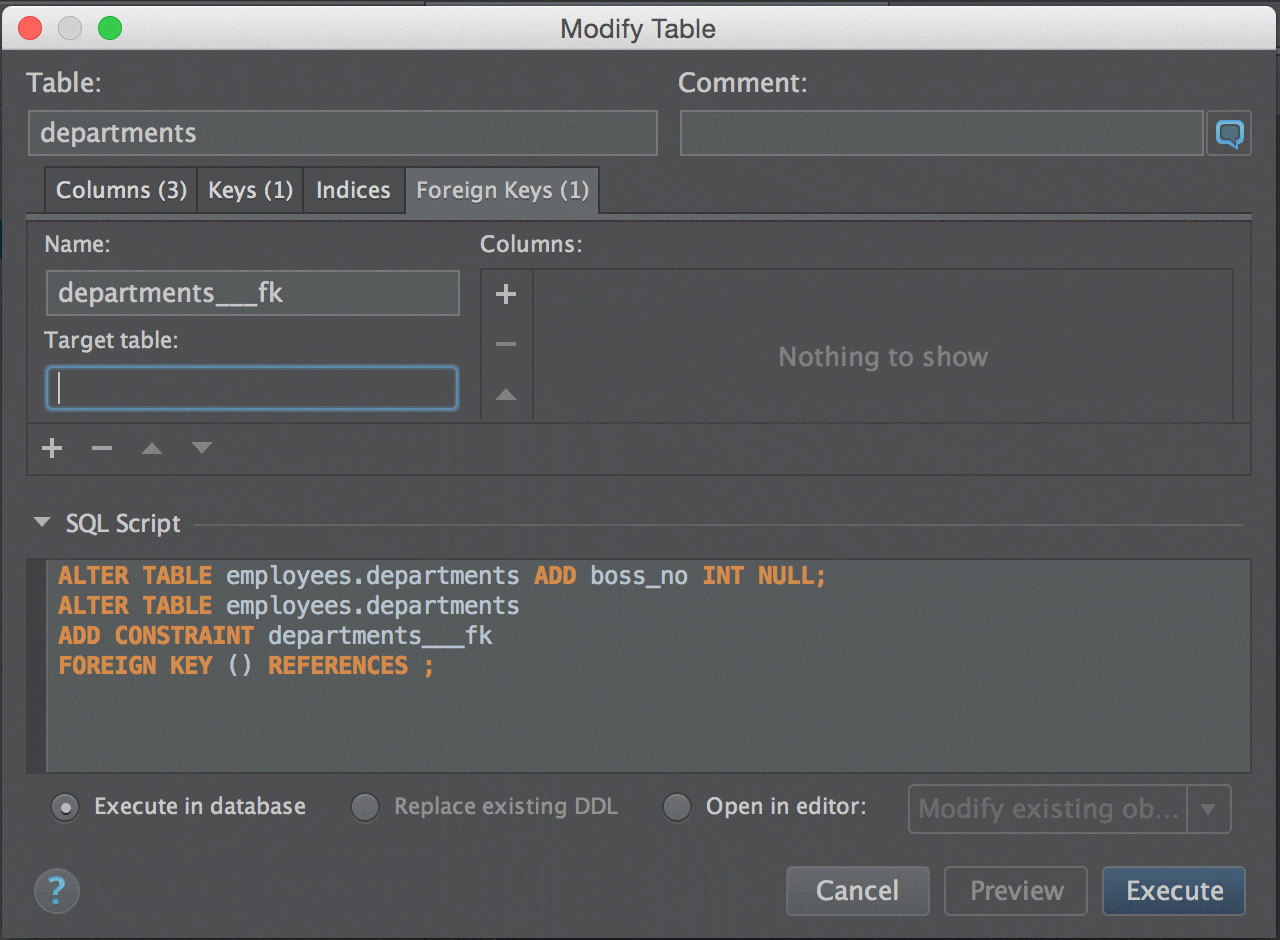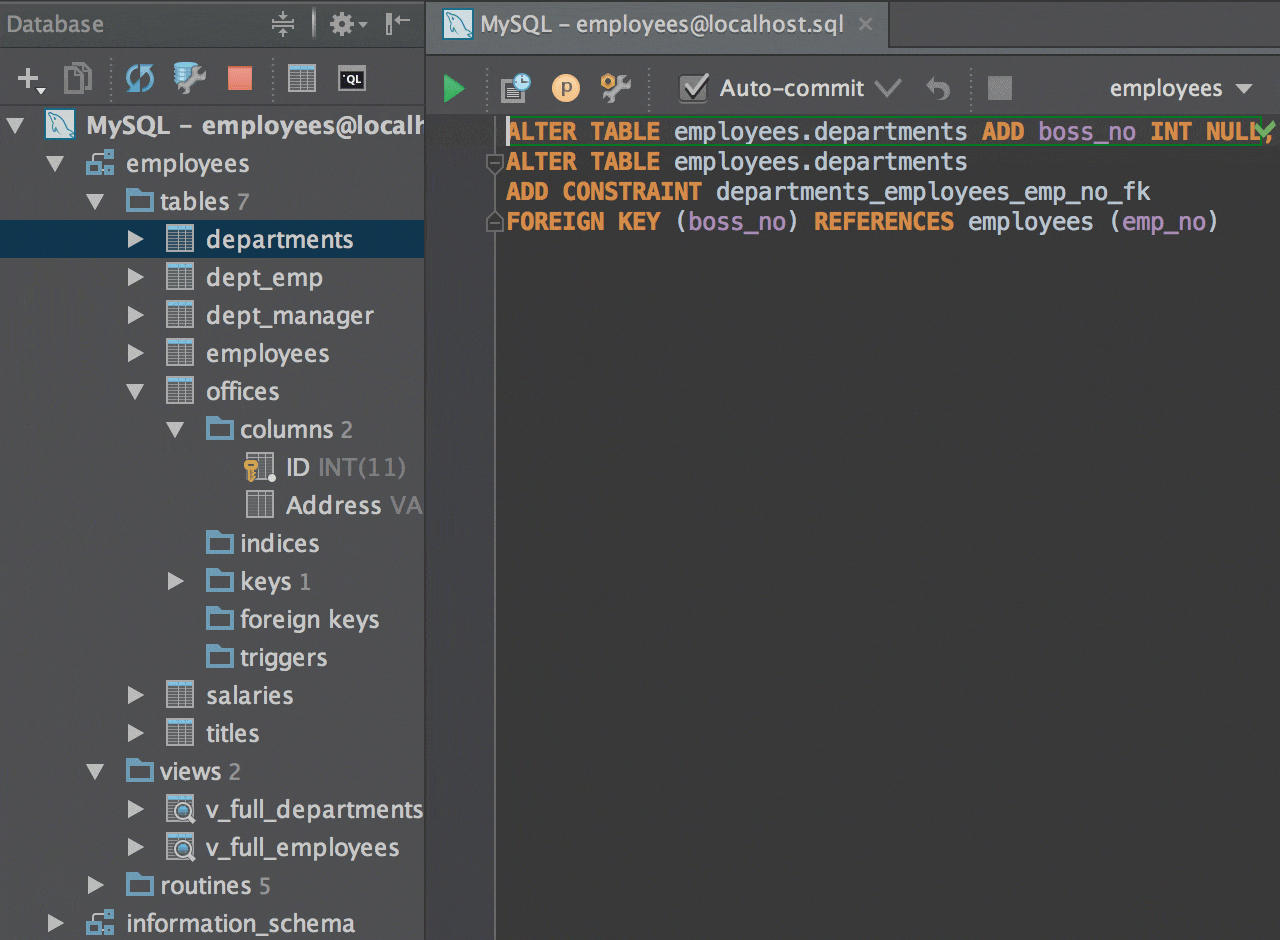

 СУБД Neo4j — это NoSQL база данных, ориентированная на хранение графов. Изюминкой продукта является декларативный язык запросов Cypher.
СУБД Neo4j — это NoSQL база данных, ориентированная на хранение графов. Изюминкой продукта является декларативный язык запросов Cypher.

