Случайные числа — темная лошадка обеспечения механизмов безопасности в цифровой среде. Незаслуженно оставаясь в тени криптографических примитивов, они в то же время являются ключевым элементом для генерации сессионных ключей, применяются в численных методах Монте-Карло, в имитационном моделировании и даже для проверки теорий формирования циклонов!
При этом от качества реализации самого генератора псевдослучайных чисел зависит и качество результирующей последовательности. Как говорится: «генерация случайных чисел слишком важна, чтобы оставлять её на волю случая».

Вариантов реализации генератора псевдослучайных чисел достаточно много: Yarrow, использующий традиционные криптопримитивы, такие как AES-256, SHA-1, MD5; интерфейс CryptoAPI от Microsoft; экзотичные Chaos и PRAND и другие.
Но цель этой заметки иная. Здесь я хочу рассмотреть особенность практической реализации одного весьма популярного генератора псевдослучайных чисел, широко используемого к примеру в Unix среде в псевдоустройстве /dev/random, а также в электронике и при создании потоковых шифров. Речь пойдёт об LFSR (Linear Feedback Shift Register).
Дело в том, что есть мнение, будто в случае использования плотных многочленов, состояния регистра LFSR очень медленно просчитываются. Но как мне видится, зачастую проблема не в самом алгоритме (хотя и он конечно не идеал), а в его реализации.
Дословно, LFSR — регистр сдвига с линейной обратной связью, состоящий из двух частей — регистра сдвига и функции обратной связи. Регистр состоит из битов, его длина — количество этих бит.
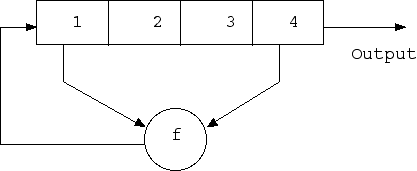
Когда извлекается бит, все биты регистра сдвигаются вправо на одну позицию. При этом новый крайний слева бит определяется функцией остальных битов до извлечения. На выходе регистра оказывается младший значащий бит.
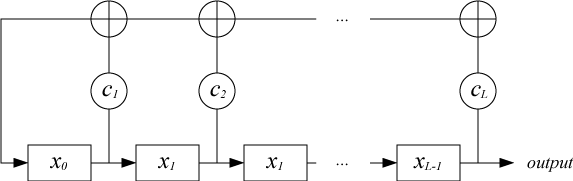
Как не трудно определить, свойства выдаваемой последовательности тесно связаны со свойствами ассоциированного многочлена: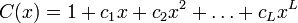
При этом его ненулевые коэффициенты называются отводами (taps), на основе которых определяются входящие значения для функции обратной связи.
Рекомендуемые индексы отводов в зависимости от длины битового поля регистра LFSR хорошо представлены в документе «Efficient Shift Registers, LFSR Counters, and Long PseudoRandom Sequence Generators».
Итак, реализация LFSR достаточно проста, но есть мнение, что в силу использования множества битовых операций для просчета плотных многочленов, таких как XOR, скорость работы зачастую оставляет желать лучшего, т.е. ему нужно некоторое время на «разогрев». В качестве альтернативы даже была предложена модификация LFSR со схемой Галуа, цикл из фиксированного числа вызовов функции LFSR в которой выполняется примерно в два раза быстрее.
Честно, не могу с этим согласится. Как я вижу, зачастую проблема не в самом алгоритме, а в его реализации. Обычно мы видим конструкцию следующего типа:
Жестоко. Здесь, как минимум, мы можем избавиться от нескольких XOR и сдвигов, воспользовавшись значением флага четности PF (Parity Flag) регистра флагов. Действительно, сложения по модулю 2 (XOR) определяют четность количества установленных битов. Единственное, флаг четности PF устанавливается, если младший значащий байт результата содержит чётное число единичных (ненулевых) битов, т.е. как минимум один арифметический сдвиг нам сделать все-таки придется:
В случае, использования плотных многочленов, когда отводы распределены по всему битовому полю 32-х битного регистра, то таких мы получим уже 4 операции сдвига и 3 операции XOR:
Отступление: в случае, когда кол-во сдвигов sar ebx,08h четное либо равно нулю, перед исполнением XOR необходимо инвертировать значение регистра AH, поскольку PF установлен когда кол-во ненулевых битов четное. А нам нужно наоборот.
Что всё же несколько кошернее чем:
Следующий шаг — использование регистра для аккумуляции результатов, вместо непосредственного сброса в память на каждом состоянии LFSR:
и так до 32 состояний (edx DWORD), только после чего и записываем в память.
И наконец, в случае, если нам очень необходимо реализовать шустрый 128-битный LFSR (внезапно) мы можем воспользоваться регистрами MMX, что позволит нам на 32-х битном процессоре семейства Pentium реализовать сдвиг без необходимости обращения к памяти (только лишь средствами регистров).
Исходный код
Исходный код на языке ассемблера (x86): pastebin.com/rwKfsYsN
Скомпилированный исполняемый код: www.sendspace.com/file/atg0cf
Update:
Оптимизированная версия кода: pastebin.com/B3kPEaew
Скомпилированный исполняемый код: www.sendspace.com/file/9bl5di
Наконец, о скорости работы — «разогрев» 128-битного LFSR через смену 2 097 120 (0FFFFh x 32) состояний при помощи MMX и регистра флагов с перерывом на кофе (вывод на экран) занял на моем PC порядка 5 секунд. В то же время исполнение программы на C++, написанная по аналогии с вышеприведенной, но для 128-битного варианта и также с выводом на экран, заняло порядка 2-3 минут.
При этом, основной цимес в том, что в варианте использования Parity Flag, плотность многочлена не оказывает сильного влияния на скорость рассчета обратной функции для нового состояния регистра LFSR. А соответственно высказывания в стиле: «Одна из главных проблем РСЛОС состоит в том, что их программная реализация крайне не эффективна. Вам приходиться избегать разреженных многочленов обратной связи так как они приводят к облегчению взлома корреляционным вскрытием. А плотные многочлены очень медленно просчитываются» (отсюда: ru.wikipedia.org/wiki/LFSR ) несколько… несостоятельны и требуют уточнения :)
p.s. И вот что интересно, а можно ли сделать реализацию программы на языке высокого уровня, без ассемлерных вставок, время исполнения которой при переборе 2 097 120 (0FFFFh x 32) состояний для 128-битного LFSR заняло бы… например, менее 0.5 секунды?
При этом от качества реализации самого генератора псевдослучайных чисел зависит и качество результирующей последовательности. Как говорится: «генерация случайных чисел слишком важна, чтобы оставлять её на волю случая».
Вариантов реализации генератора псевдослучайных чисел достаточно много: Yarrow, использующий традиционные криптопримитивы, такие как AES-256, SHA-1, MD5; интерфейс CryptoAPI от Microsoft; экзотичные Chaos и PRAND и другие.
Но цель этой заметки иная. Здесь я хочу рассмотреть особенность практической реализации одного весьма популярного генератора псевдослучайных чисел, широко используемого к примеру в Unix среде в псевдоустройстве /dev/random, а также в электронике и при создании потоковых шифров. Речь пойдёт об LFSR (Linear Feedback Shift Register).
Дело в том, что есть мнение, будто в случае использования плотных многочленов, состояния регистра LFSR очень медленно просчитываются. Но как мне видится, зачастую проблема не в самом алгоритме (хотя и он конечно не идеал), а в его реализации.
Немного об LFSR
Дословно, LFSR — регистр сдвига с линейной обратной связью, состоящий из двух частей — регистра сдвига и функции обратной связи. Регистр состоит из битов, его длина — количество этих бит.
Когда извлекается бит, все биты регистра сдвигаются вправо на одну позицию. При этом новый крайний слева бит определяется функцией остальных битов до извлечения. На выходе регистра оказывается младший значащий бит.
Как не трудно определить, свойства выдаваемой последовательности тесно связаны со свойствами ассоциированного многочлена:
При этом его ненулевые коэффициенты называются отводами (taps), на основе которых определяются входящие значения для функции обратной связи.
Рекомендуемые индексы отводов в зависимости от длины битового поля регистра LFSR хорошо представлены в документе «Efficient Shift Registers, LFSR Counters, and Long PseudoRandom Sequence Generators».
Практическая реализация
Итак, реализация LFSR достаточно проста, но есть мнение, что в силу использования множества битовых операций для просчета плотных многочленов, таких как XOR, скорость работы зачастую оставляет желать лучшего, т.е. ему нужно некоторое время на «разогрев». В качестве альтернативы даже была предложена модификация LFSR со схемой Галуа, цикл из фиксированного числа вызовов функции LFSR в которой выполняется примерно в два раза быстрее.
Честно, не могу с этим согласится. Как я вижу, зачастую проблема не в самом алгоритме, а в его реализации. Обычно мы видим конструкцию следующего типа:
int LFSR (void)
{
static unsigned long S = 0xFFFFFFFF;
/* taps: 32 31 30 28 26 1; charact. polynomial: x^32 + x^31 + x^30 + x^28 + x^26 + x^1 + 1 */
S = ((( (S>>0)^(S>>1)^(S>>2)^(S>>4)^(S>>6)^(S>>31) ) & 1 ) << 31 ) | (S>>1);
return S & 1;
}Жестоко. Здесь, как минимум, мы можем избавиться от нескольких XOR и сдвигов, воспользовавшись значением флага четности PF (Parity Flag) регистра флагов. Действительно, сложения по модулю 2 (XOR) определяют четность количества установленных битов. Единственное, флаг четности PF устанавливается, если младший значащий байт результата содержит чётное число единичных (ненулевых) битов, т.е. как минимум один арифметический сдвиг нам сделать все-таки придется:
xor ecx,ecx
mov ebx,0FFFFFFFFh ; S
mov eax,080000057h ; taps (32,31,30,28,26,1)
and ebx,eax
mov cl,ah
sar ebx,018h
lahf
xor cl,ah
sar cl,02h
and cl,01hВ случае, использования плотных многочленов, когда отводы распределены по всему битовому полю 32-х битного регистра, то таких мы получим уже 4 операции сдвига и 3 операции XOR:
xor ecx,ecx
mov ebx,0FFFFFFFFh ; S
mov eax,095324C57h ; taps (32,31,30,28,26,22,21,18,15,12,11,8,6,4,1)
and ebx,eax
lahf
mov cl,ah ; [0-7] bits
sar ebx,08h
lahf
xor cl,ah ; [8-15] bits
sar ebx,08h
lahf
xor cl,ah ; [16-23] bits
sar ebx,08h
lahf
xor cl,ah ; [24-31] bits
sar cl,02h
and cl,01hОтступление: в случае, когда кол-во сдвигов sar ebx,08h четное либо равно нулю, перед исполнением XOR необходимо инвертировать значение регистра AH, поскольку PF установлен когда кол-во ненулевых битов четное. А нам нужно наоборот.
Что всё же несколько кошернее чем:
int LFSR (void)
{
static unsigned long S = 0xFFFFFFFF;
S = ((( (S>>0)^(S>>1)^(S>>2)^(S>>4)^(S>>6)^(S>>10)^(S>>11)^
(S>>14)^(S>>17)^(S>>20)^(S>>21)^(S>>24)^(S>>26)^
(S>>28)^(S>>31) ) & 1 ) << 31 ) | (S>>1);
return S & 1;
}Следующий шаг — использование регистра для аккумуляции результатов, вместо непосредственного сброса в память на каждом состоянии LFSR:
sal edx,01h
or dl,clи так до 32 состояний (edx DWORD), только после чего и записываем в память.
И наконец, в случае, если нам очень необходимо реализовать шустрый 128-битный LFSR (внезапно) мы можем воспользоваться регистрами MMX, что позволит нам на 32-х битном процессоре семейства Pentium реализовать сдвиг без необходимости обращения к памяти (только лишь средствами регистров).
Исходный код
Исходный код на языке ассемблера (x86): pastebin.com/rwKfsYsN
Скомпилированный исполняемый код: www.sendspace.com/file/atg0cf
Update:
Оптимизированная версия кода: pastebin.com/B3kPEaew
Скомпилированный исполняемый код: www.sendspace.com/file/9bl5di
- 128-bit LFSR
- используются MMX-регистры
- архитектура x86
- смена 2097120 (0FFFFh x 32) состояний регистра LFSR
В итоге
Наконец, о скорости работы — «разогрев» 128-битного LFSR через смену 2 097 120 (0FFFFh x 32) состояний при помощи MMX и регистра флагов с перерывом на кофе (вывод на экран) занял на моем PC порядка 5 секунд. В то же время исполнение программы на C++, написанная по аналогии с вышеприведенной, но для 128-битного варианта и также с выводом на экран, заняло порядка 2-3 минут.
При этом, основной цимес в том, что в варианте использования Parity Flag, плотность многочлена не оказывает сильного влияния на скорость рассчета обратной функции для нового состояния регистра LFSR. А соответственно высказывания в стиле: «Одна из главных проблем РСЛОС состоит в том, что их программная реализация крайне не эффективна. Вам приходиться избегать разреженных многочленов обратной связи так как они приводят к облегчению взлома корреляционным вскрытием. А плотные многочлены очень медленно просчитываются» (отсюда: ru.wikipedia.org/wiki/LFSR ) несколько… несостоятельны и требуют уточнения :)
p.s. И вот что интересно, а можно ли сделать реализацию программы на языке высокого уровня, без ассемлерных вставок, время исполнения которой при переборе 2 097 120 (0FFFFh x 32) состояний для 128-битного LFSR заняло бы… например, менее 0.5 секунды?
