Современные системы мониторинга “из коробки” позволяют отслеживать практически все показатели отдельного узла системы, но обладают рядом существенных недостатков
На исходной у нашей площадки более 1.000.000 уников, ~100.000.000 http запросов на фронтенд в сутки и развесистый, в плане сопровождения, зоопарк проектов. Набор ключевых слов — nginx, apache, php (двух вариаций), oracle. С заядлой периодичностью возникают ситуации “у нас все работает” по отдельно взятым зонам ответственности либо, что тоже не редкость, “у вас ничего не работает”. На границах ответственности идет сплошная передача тикетов.
Мы не стали изобретать велосипед и решили сделать мониторинг по времени и корректности отклика пользователю с отслеживанием отклика бекендов, а также какие из них были задействованы при обработке конкретного запроса. Ну и плюс наши объемы — не сильно большие, но несколько граблей по ходу изложения можно продемонстрировать.
Что мы получили в итоге.
Если узлов в системе больше одного, то неплохо бы иметь способ отследить один запрос начиная с front сквозь всю систему. Если узлов десятки — IP клиента уже не поможет. Если внизу стоит база, то DBA порой будут бегать с паяльником и фразой “чей запрос???”. Ну и стандартный combined просто не содержит какой-либо информации о времени обработки на бекенд, попадании в кеш, выбранном upstream, времени отдачи данных пользователю. В стандартных модулях nginx есть практически все, что может нам понадобиться. Мы добавили только один модуль от HeadHunter
github.com/hhru/nginx_requestid, присваивающий уникальный идентификатор каждому запросу на nginx и позволяющему писать его в лог, а также пробрасывать его вверх и вниз в заголовках. Итоговый формат нашего nginx лога выглядит следующим образом.

Страшно? Веселее, что в полях типа upstream могут быть следующие вещи “upstream_1: upstream_2”, для всех бекендов, что обрабатывали данный запрос. Request_id уже описывался, два последних uid_got, uid_set — модуль ngx_http_userid, который позволяет отслеживать уже конкретного пользователя, установкой ему системных кук. Почему в качестве разделителя используются четыре пробела будет описано в разделе парсинга. На уровне Apache или php-fpm имеет смысл записывать в логи пришедший сверху request_id, а наверх отдавать имя хоста, если в качестве upstream указан балансировщик запросов. На уровне приложения стоит завести правило указывать request_id в сообщених об ошибках. Один из способов пробросить данные запроса в сессию Oracle я описывал в небольшой заметке. Его преимущество в том, что не приходится просить разработчиков делать то же самое их средствами и есть гарантия, что данные у Вас появятся по всем проектам сразу. Также есть смысл смотреть в сторону pinba или xhprof для отслеживания времени ожидания внешних ресурсов (базы, api сервисов, системных вызовов) для каждого запроса и в среднем по проекту/площадке. Наше адаптированное решение в этой области будет готово ближе к зиме.
Дальнейшее изложение посвящено наше попытке анализа логов на примере логов nginx — как самых информативных и объемных в нашей системе на данный момент.
Стандарт де-факто в аггрегации логов — различные форки и потомки syslog. В качестве транспорта используется UDP, чтобы избежать накладных расходов в виде поддержки соединения и гарантирования доставки. Потерять несколько процентов сообщений в штатном режиме можно себе позволить, более глобальные потери будут связаны уже с глобальными проблемами вашей инфраструктуры, о которых вы узнаете из других источников. Подробнее о подводных камнях на большом потоке сообщений можно узнать из доклада директора по эксплуатации hh.ru “Опыт перехода на SOA” www.slideshare.net/kuchinskaya/sivko, в нем рассмотрены несколько вариантов сбора логов в единое место. Помимо доставки по udp есть смысл собирать логи в единое файлохранилище на будущее.
На нашей площадке исходно была решена вторая часть задачи — все логи изначально пишутся на сетевое хранилище. Для упрощения в прототипе своего анализатора мы просто читаем логи по nfs. Чем это плохо в принципе — запись логов тратит ресурсы всей системы круглые сутки, доступность логов зависит от исправности сетевого хранилища (у Вас никогда не падал NetApp посреди рабочего дня?), буферизация записи усложняет алгоритм разбора логов. Также в лог файл пишется строка в текстовом формате, если пересылать данные о запросе в сериализованном виде — избежим затрат на парсинг на стороне приемника.
В нашем случае парсер написан на Perl, данные кладутся в MongoDB 2.2.0. Алгоритм прост до безобразия — помним последнюю обработанную позицию в файле, сравниваем текущий размер, если дельта больше отсечки — отправляем в парсинг файла, в парсинге проверяем корректность записи (про буферизацию записи все помним?). Из граблей
Всех этих прелестей можно избежать отсылая данные по udp.
Хранить все данные за много времени вместе с индексами можно, но ОЧЕНЬ дорого. В реальной жизни используется временное хранилище с возможностью строить аналитику с данными за последние несколько часов — сутки. Для оперативной диагностики больше данных не имеют смысла, глобально исторические отчеты всегда можно построить по сырым данным.
Мы используем MongoDB потому что … нам так захотелось. Грубо, но это так — Вы можете выбрать любой инструмент, в котором Вы будете готовы реализовывать подобную систему. Чем более удобно и быстро реализуется группировка записей и обновление данных в хранилище, тем лучше.
Из нерелигиозных плюсов Mongo
Грабли
Несмотря на вторую граблю относительно сложный запрос “выяснить top-50 IP по числу запросов, нагрузке на бекенд, трафику за последнюю минуту” вычисляется за 800-1200мс. В нашем случае одна железяка обслуживает запись данных и их вытеснение (master), на вторую идет реплика, чтобы обсчет аналитики не тормозил запись.
Есть также желание опробовать мейловский Tarantool (tarantool.org) — до исправления грабли в парсере с regexp он показывал не очень красивые цифры по скорости загрузки данных. После исправления не тестировалось, надеюсь на приятные неожиданности.
Из потенциальных плюсов Tarantool
На прошлых этапах мы получили массив записей из лог файлов узлов нашей системы, доступный для быстрого поиска и группировки по необходимым правилам. Наш тестовый скрипт на Perl подготавливает данные следующим куском
где поле gf
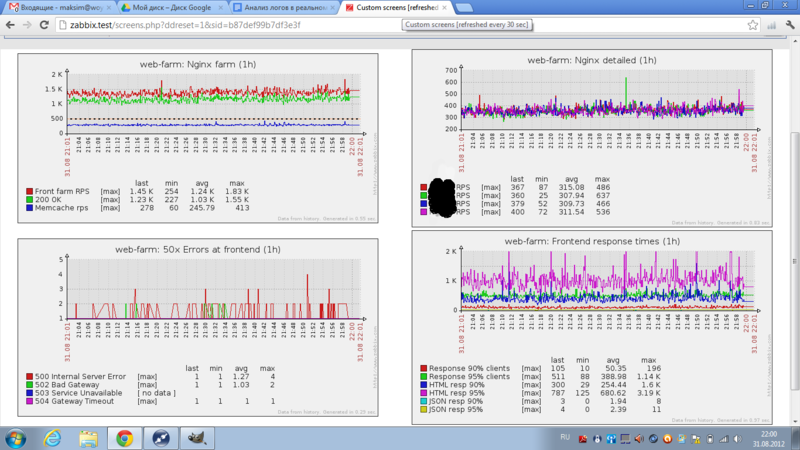
На выходе получаем ссылку на массив предварительно сгруппированных данных, которые в дальнейшем превращаем в конечные метрики. В нашем случае нас интересуют общие метрики крутости=нагруженности площадки, показатели времени ответа конечным пользователям в целом/по типам контента, эффективность наших кешей, число ошибок. Примерная картина по площадке в целом может выглядеть как на скрине в начале поста. Наборы попроектных/посистемных метрик формируются из пожеланий службы эксплуатации, администраторских групп (у нас например отдельный экран посвящен запросам к полнотекстовому индексу из разных проектов — чтобы видеть источник нагрузки на узел), разработчиков, владельцев сайтов и непосредственного руководства. После первой демонстрации у нас из пожеланий стали формироваться один-два экрана в неделю.
Ключевое требование к обсчету — время обсчета временного интервала и загрузки в системы мониторинга должно быть меньше этого интервала.
У нас это время порядка 100-200мс на секундный интервал. Секундный интервал выбран на этапе сборки конструктора, чтобы обкатать все в самых жестких условиях. В реальных условиях больше прав на жизнь имеют 5/10/30/60-секундные средние значения.
Сначала данные надо как-нибудь красиво отобразить. На этапе отладки предыдущих шагов использовалась библиотета highcharts, данные брались из MongoDB, куда складывались скриптом из пункта 4.

В дальнейшем оформились ключевые пожелания к системе мониторинга, куда мы грузили бы данные
Не так уж много, нам вполне подошел zabbix, который и показан на заглавном скрине. Здесь, как и с mongo, все зависит от личных предпочтений и конкретной ситуации. Свои метрики заводятся с типом zabbix trapper, а данные загружаются утилитой zabbix_sender в batch режиме, в качестве базы mysql. Загрузка сотни значений занимает 1-2мс.
После проделанной работы, которая отняла около человеко-месяца в фоновом режиме у нас появились
К путям развития
Если есть желание подробней окунуться в тему — на профи тусовках за последний год тема мониторинга и профайлинга поднималась неоднократно, если в комментах будут ссылки на подобные публикации — буду только рад.
В данной заметке очерчены основные контуры нашей системы, которая только начинает обрастать конкретикой. Начальные шаги самые важные и я буду рад услышать, что положено в основу Ваших систем — принципы и технологии.
- зная все об одном узле, о работе системы в целом они не имеют никакого представления — попробуйте из коробки выдать руководству “в данный момент у нас 1200RPS на фронте, 90% страниц отдается за 300мс, 95% за 650мc, системных ошибок и таймаутов происходит меньше 10 в секунду” (см картинку под катом)
- выход за рамки одного из системных показателей одного из узлов системы еще не значит, что стоит бить тревогу — возможно узел попал под повышенную нагрузку, или разработчики сменили алгоритм
- в рамках мониторинга отдельных узлов практически невозможно уследить постепенную деградацию сервиса — как правило он срабатывает только когда уже “ничего не работает”
- деградация производительности внешних сервисов не отслеживается в принципе (вас никогда не банил CDN?)
На исходной у нашей площадки более 1.000.000 уников, ~100.000.000 http запросов на фронтенд в сутки и развесистый, в плане сопровождения, зоопарк проектов. Набор ключевых слов — nginx, apache, php (двух вариаций), oracle. С заядлой периодичностью возникают ситуации “у нас все работает” по отдельно взятым зонам ответственности либо, что тоже не редкость, “у вас ничего не работает”. На границах ответственности идет сплошная передача тикетов.
Мы не стали изобретать велосипед и решили сделать мониторинг по времени и корректности отклика пользователю с отслеживанием отклика бекендов, а также какие из них были задействованы при обработке конкретного запроса. Ну и плюс наши объемы — не сильно большие, но несколько граблей по ходу изложения можно продемонстрировать.
Что мы получили в итоге.
1. Подготовка исходных данных.
Если узлов в системе больше одного, то неплохо бы иметь способ отследить один запрос начиная с front сквозь всю систему. Если узлов десятки — IP клиента уже не поможет. Если внизу стоит база, то DBA порой будут бегать с паяльником и фразой “чей запрос???”. Ну и стандартный combined просто не содержит какой-либо информации о времени обработки на бекенд, попадании в кеш, выбранном upstream, времени отдачи данных пользователю. В стандартных модулях nginx есть практически все, что может нам понадобиться. Мы добавили только один модуль от HeadHunter
github.com/hhru/nginx_requestid, присваивающий уникальный идентификатор каждому запросу на nginx и позволяющему писать его в лог, а также пробрасывать его вверх и вниз в заголовках. Итоговый формат нашего nginx лога выглядит следующим образом.
Страшно? Веселее, что в полях типа upstream могут быть следующие вещи “upstream_1: upstream_2”, для всех бекендов, что обрабатывали данный запрос. Request_id уже описывался, два последних uid_got, uid_set — модуль ngx_http_userid, который позволяет отслеживать уже конкретного пользователя, установкой ему системных кук. Почему в качестве разделителя используются четыре пробела будет описано в разделе парсинга. На уровне Apache или php-fpm имеет смысл записывать в логи пришедший сверху request_id, а наверх отдавать имя хоста, если в качестве upstream указан балансировщик запросов. На уровне приложения стоит завести правило указывать request_id в сообщених об ошибках. Один из способов пробросить данные запроса в сессию Oracle я описывал в небольшой заметке. Его преимущество в том, что не приходится просить разработчиков делать то же самое их средствами и есть гарантия, что данные у Вас появятся по всем проектам сразу. Также есть смысл смотреть в сторону pinba или xhprof для отслеживания времени ожидания внешних ресурсов (базы, api сервисов, системных вызовов) для каждого запроса и в среднем по проекту/площадке. Наше адаптированное решение в этой области будет готово ближе к зиме.
Дальнейшее изложение посвящено наше попытке анализа логов на примере логов nginx — как самых информативных и объемных в нашей системе на данный момент.
2. Сбор логов в единый центр.
Стандарт де-факто в аггрегации логов — различные форки и потомки syslog. В качестве транспорта используется UDP, чтобы избежать накладных расходов в виде поддержки соединения и гарантирования доставки. Потерять несколько процентов сообщений в штатном режиме можно себе позволить, более глобальные потери будут связаны уже с глобальными проблемами вашей инфраструктуры, о которых вы узнаете из других источников. Подробнее о подводных камнях на большом потоке сообщений можно узнать из доклада директора по эксплуатации hh.ru “Опыт перехода на SOA” www.slideshare.net/kuchinskaya/sivko, в нем рассмотрены несколько вариантов сбора логов в единое место. Помимо доставки по udp есть смысл собирать логи в единое файлохранилище на будущее.
На нашей площадке исходно была решена вторая часть задачи — все логи изначально пишутся на сетевое хранилище. Для упрощения в прототипе своего анализатора мы просто читаем логи по nfs. Чем это плохо в принципе — запись логов тратит ресурсы всей системы круглые сутки, доступность логов зависит от исправности сетевого хранилища (у Вас никогда не падал NetApp посреди рабочего дня?), буферизация записи усложняет алгоритм разбора логов. Также в лог файл пишется строка в текстовом формате, если пересылать данные о запросе в сериализованном виде — избежим затрат на парсинг на стороне приемника.
2.5 Парсинг логов.
В нашем случае парсер написан на Perl, данные кладутся в MongoDB 2.2.0. Алгоритм прост до безобразия — помним последнюю обработанную позицию в файле, сравниваем текущий размер, если дельта больше отсечки — отправляем в парсинг файла, в парсинге проверяем корректность записи (про буферизацию записи все помним?). Из граблей
- если файлов много — храните дескрипторы, вместо открытия файла всякий раз, не так много по времени, но хранилищу станет приятней
- reg exp по нашему формату обрабатывал 700 строк в секунду, после перехода на формат со стандартным разделителем и заменой регулярки на split скорость возросла до 10-20 тысяч строк в секунду. Здесь цифры говорят лучше внутренних убеждений
- если время итерации меньше двух-трех секунд — сделайте небольшой sleep, хранилищу станет еще приятней, что его не дергают на stat сотен файлов каждую секунду
- batch_insert сделает приятно базе, но у mongo есть ограничение в 16MB на один вызов insert (4MB до 2.2)
Всех этих прелестей можно избежать отсылая данные по udp.
3. Временное хранилище для обсчета аналитики и поиска.
Хранить все данные за много времени вместе с индексами можно, но ОЧЕНЬ дорого. В реальной жизни используется временное хранилище с возможностью строить аналитику с данными за последние несколько часов — сутки. Для оперативной диагностики больше данных не имеют смысла, глобально исторические отчеты всегда можно построить по сырым данным.
Мы используем MongoDB потому что … нам так захотелось. Грубо, но это так — Вы можете выбрать любой инструмент, в котором Вы будете готовы реализовывать подобную систему. Чем более удобно и быстро реализуется группировка записей и обновление данных в хранилище, тем лучше.
Из нерелигиозных плюсов Mongo
- capped collections — fifo коллекция записей, в нашем случае пока вполне хватает коллекции в 3GB, файлы которой лежат на ramdisk
- aggregation framework — новая фишка с версии 2.2, под наши задачи группирует посекундные 1.200-10.000 за 50-200мс
- ttl collections — коллекции, где можно указать время жизни записей (аналог expire в memcache), imho несколько сыро
- скорость записи в один поток — 5-6 тысяч записей в секунду, можно масштабировать несколькими потоками записи
Грабли
- в версии 2.2.0-rc0 в aggregation $project можно было передавать в оператор $add строки, таким образом формировался ключ группы из нескольких полей, в версии 2.2.0-rc1 и выше такой возможности нет, а оператор $concat обещается в 2.3.x без каких-либо сроков. Пришлось обходить на уровень выше, в парсере — записью группового ключа в каждую запись
- чем больше индексов будет создано, тем медленней будет вставка. Чем меньше индексов — тем меньше возможностей для поиска. У нас сейчас два индекса — системный идентификатор и timestamp из записи. Больше на тестовом стенде мы себе позволить не можем.
- capped collection не шардится встроенными средствами, это придется делать на уровне приложения.
Несмотря на вторую граблю относительно сложный запрос “выяснить top-50 IP по числу запросов, нагрузке на бекенд, трафику за последнюю минуту” вычисляется за 800-1200мс. В нашем случае одна железяка обслуживает запись данных и их вытеснение (master), на вторую идет реплика, чтобы обсчет аналитики не тормозил запись.
Есть также желание опробовать мейловский Tarantool (tarantool.org) — до исправления грабли в парсере с regexp он показывал не очень красивые цифры по скорости загрузки данных. После исправления не тестировалось, надеюсь на приятные неожиданности.
Из потенциальных плюсов Tarantool
- memory based база данных
- встроенный язык lua для хранимых процедур
- доступность автора на русском языке и high perfomance тусовках в Москве
4. Агрегаты, персентили …
На прошлых этапах мы получили массив записей из лог файлов узлов нашей системы, доступный для быстрого поиска и группировки по необходимым правилам. Наш тестовый скрипт на Perl подготавливает данные следующим куском
my $res3=$slave->logs2->run_command(
{
aggregate=>'lines',
pipeline=>[
{'$match'=>{'tstamp'=>{'$lt'=>$i,'$gte'=>$i-1}}},
{'$project'=>{
'gf'=>1,
'upstream_time'=>1
,'resp_time'=>1
,'size'=>1
}
},
{'$group'=>{'_id'=>'$gf',total=>{'$sum'=>1},traffic=>{'$sum'=>'$size'},'times'=>{'$push'=>'$upstream_time'},'response'=>{'$push'=>'$resp_time'}}}
]
}
);
где поле gf
$inf{gf}=join(' ',($inf{upstream},$inf{code},$inf{host},$inf{backend},$inf{frontend},$inf{cache_status},$inf{content_type},$inf{url},$inf{upstream_code}));
На выходе получаем ссылку на массив предварительно сгруппированных данных, которые в дальнейшем превращаем в конечные метрики. В нашем случае нас интересуют общие метрики крутости=нагруженности площадки, показатели времени ответа конечным пользователям в целом/по типам контента, эффективность наших кешей, число ошибок. Примерная картина по площадке в целом может выглядеть как на скрине в начале поста. Наборы попроектных/посистемных метрик формируются из пожеланий службы эксплуатации, администраторских групп (у нас например отдельный экран посвящен запросам к полнотекстовому индексу из разных проектов — чтобы видеть источник нагрузки на узел), разработчиков, владельцев сайтов и непосредственного руководства. После первой демонстрации у нас из пожеланий стали формироваться один-два экрана в неделю.
Ключевое требование к обсчету — время обсчета временного интервала и загрузки в системы мониторинга должно быть меньше этого интервала.
У нас это время порядка 100-200мс на секундный интервал. Секундный интервал выбран на этапе сборки конструктора, чтобы обкатать все в самых жестких условиях. В реальных условиях больше прав на жизнь имеют 5/10/30/60-секундные средние значения.
5. Посчитали мы и что дальше?
Сначала данные надо как-нибудь красиво отобразить. На этапе отладки предыдущих шагов использовалась библиотета highcharts, данные брались из MongoDB, куда складывались скриптом из пункта 4.
- не решает вопросов произвольного формирования набора графиков на страницу конечным пользователем
- не приспособлен для задач мониторинга в принципе (нет отслеживания граничных значений, подсчета доступности сервиса по SLA и т.д.)
- обеспечил WOW-эффект
В дальнейшем оформились ключевые пожелания к системе мониторинга, куда мы грузили бы данные
- возможность заводить свои метрики
- загружать их снаружи (api/софт для загрузки)
Не так уж много, нам вполне подошел zabbix, который и показан на заглавном скрине. Здесь, как и с mongo, все зависит от личных предпочтений и конкретной ситуации. Свои метрики заводятся с типом zabbix trapper, а данные загружаются утилитой zabbix_sender в batch режиме, в качестве базы mysql. Загрузка сотни значений занимает 1-2мс.
6. Итоги
После проделанной работы, которая отняла около человеко-месяца в фоновом режиме у нас появились
- актуальная информация по выбранным метрикам с задержкой в 90 секунд (время гарантированной записи сквозь буферы, парсинг, запись в монго, репликация на slave, обсчет)
- возможность отслеживать обработку запроса пользователя по всем узлам системы (ngx_request_id)
- понимание на самом нижнем уровне — db, чем ее грузят сверху (проброс host, request_uri, request_id внутрь информации о сессиях)
- статистика использования сервиса полнотекстового поиска проектами
- взгляд на площадку с позиции предоставляемого сервиса — генерации и раздачи контента множеством проектов
- метрики-маяки проблем, специфичные для отдельных проектов и площадки в целом
- красивые картинки для руководства
- платформа для реализации большинства возможных хотелок (должно стоять нулевым пунктом на нынешней стадии)
К путям развития
- отслеживать как пули долетают до конечного пользователя (время загрузки и отображения всех элементов страницы)
- сокращение окна с 90 до 30 секунд
- алгоритмы отслеживания постепенной деградации сервиса
- поиск по сырым данным — здесь нам собирают тестовый стенд со splunk и нашими данными за две недели
- адаптация xhprof под наши пожелания
Если есть желание подробней окунуться в тему — на профи тусовках за последний год тема мониторинга и профайлинга поднималась неоднократно, если в комментах будут ссылки на подобные публикации — буду только рад.
В данной заметке очерчены основные контуры нашей системы, которая только начинает обрастать конкретикой. Начальные шаги самые важные и я буду рад услышать, что положено в основу Ваших систем — принципы и технологии.
