Картинка, которая некоторых привыкших к IPv4 сетевиков может ввести в ступор:
Причём каждый из этих адресов может быть использован наравне с другими. Как так?
Теперь подробнее.
Конечно можно возразить, что в IPv4 тоже были различные методы, как назначить на интерфейс несколько адресов (secondary, alias и так далее). Но в IPv6 адреса сделали равными, и это открывает широкие возможности.
К примеру, узел может использовать один адрес для связи в своей локальной сети, другой адрес для связи в пределах организации и третий — для доступа в Интернет. Или сразу 10 для доступа в Интернет — на каждый сайт отправлять запросы с нового адреса.
Введён механизм предпочтения и старения адресов, с помощью которого можно делать плавную смену адресов в сети. На первом этапе все запросы начинают отправляться с новых адресов, но узлы продолжают откликаются и на старые тоже. Затем ещё через некоторое время старые адреса полностью списываются в утиль.
На первый взгляд может показаться «Ну и ладно», однако такие маленькие детали приведут к совсем другой логике назначения адресов.
Опять же, формально область действия была и у адресов в IPv4.
Есть link-local адреса. Они обычно известны под кодовым именем "$@#*!!! Опять DHCP не работает!" и выбираются из диапазона 169.254.0.0/16. Но вообще-то у них есть функции помимо «Дать админу понять, что его DHCP-сервер не выдаёт адреса».
Во-первых, такой адрес может быть автоматически сгенерирован самим устройством. Во-вторых, он вполне подходит для связи внутри сети. Ограничение: он вообще-то не должен маршрутизироваться, ибо link-local.
Кроме них, RFC 1918 задаёт три диапазона приватных адресов: всеми любимый 192.168.0.0/16, большой 10.0.0.0/8 и незаслуженно забываемый 172.16.0.0/12 (т.е. от 172.16.0.0 до 172.31.255.255). Они маршрутизируются, но только в пределах вашей внутренней сети. Для связи в Интернете их использовать нельзя.
Наконец, есть (недостаточно) много уникальных («публичных», «белых») адресов, которые выдаются в пользование организациям и провайдерам и подходят для связи в глобальном масштабе.
Существенное ограничение IPv4: нельзя использовать эти адреса одновременно. Либо link-local, и сиди без связи с другими сетями, либо приватные, но без NAT в Интернет не попасть, или публичные, которые подходят для всего, но нынче в страшном дефиците.
В IPv6 одновременно можно использовать адреса с разной областью действия. Надо постучаться к соседу по сети — используем link-local. Пошли в Интернет — берём глобально-уникальный.
Для узлов предусмотрены три варианта адресов:
Кроме общего понятия «область действия», у каждого конкретного адреса на конкретном интерфейсе возникает зона действия. Это часть топологии, на которую распространяется область действия данного адреса с данного интерфейса. Для программистов обычно предлагается такое объяснение: область действия — это абстрактный класс, а зона действия — экземпляр класса. Например, у link-local-адреса на интерфейсе Fa0/0 зоной действия будет сегмент сети, подключенный к интерфейсу Fa0/0.
Границы зон проходят по узлам. Отсюда link-local адреса на разных интерфейсах маршрутизатора будут лежать в разных зонах.
Визуализировать области действия и зоны действия поможет картинка:
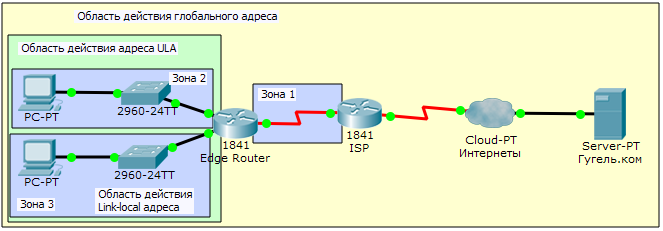
Побочный эффект: возникает двусмысленность. Если мы говорим «Отправь пакет на FE80::101», то встречный вопрос будет «На который из интерфейсов?», потому что данный адрес может быть на любом из интерфейсов. Поэтому для link-local адресов обязательно уточняется интерфейс, который будет использоваться. В Windows используется записи вида FE80::1%5, где после символа "%" идёт ID интерфейса. В Linux применяется название (FE80::1%eth0).
Возможность одновременно использовать адреса разных типов открывает очень интересные возможности.
Возьмём вот такую топологию:

Сколько подсетей нужно, чтобы у нас была связь по IP между компьютером и сервером?
В IPv4 понадобится 4 подсети, и даже если мы будем брать сети /31, это 8 адресов.
Сколько подсетей достаточно будет настроить в IPv6?
Как это возможно?
А очень просто. Маршрутизация работает хоп за хопом. На каждом этапе нам нужно знать только исходящий интерфейс и адрес следующего перехода, причём физический, а IP нам нужен постольку-поскольку.
Компьютер знает link-local адрес ближайшего роутера (Router0). Router0 знает link-local следующего в цепочке (Router1). Router1 знает адрес Router2. Router2 может доставить сообщение серверу. Обратно так же.
Уточнение: Как справедливо заметил в комментариях Alukardd, такая возможность есть и в IPv4. Поэтому в Интернете вы вполне можете увидеть приватные адреса в результатах трассировки.
Проверим.
Включим маршрутизацию IPv6:
Включим IPv6 на интерфейсах, адреса link-local создадутся автоматически:
Проверяем:
Настраиваем глобальные адреса:
Обратите внимание, что на компьютерах в общем случае ничего настраивать не нужно, адреса будут автоматически получены. Каким образом — тема отдельной статьи.
Наконец, понадобится маршрутизация. Настроим OSPFv3.
Повторяем процедуру на остальных роутерах (меняя router-id, само собой). После этого у нас установится соседство (по link-local адресам!), и в таблицу маршрутизации попадут нужные маршруты.
После чего можно убедиться, что всё работает.
Вывод: для транзита трафика достаточно использовать link-local адреса. Глобально-уникальные адреса и ULA нужны будут только в том случае, если вы хотите обратиться к самому устройству (к примеру, зайти на роутер по SSH).
Несомненный плюс маршрутизации по link-local адресам в том, что убирается привязка к конкретной адресации. Можно привести такую аналогию: в IPv4 маршрут записывался через названия улиц и домов — «По улице Ленина до дома 51 и направо». В IPv6 маршрут можно записать как «два светофора прямо, на третьем направо». В случае смены адресации («переименования улиц») маршруты IPv4 нужно перестраивать заново, а в IPv6 всё продолжит работать как обычно.
Про EUI-64 разъяснение было ранее, но сама тема в целом достойна отдельной статьи.
IPv6-адреса через EUI-64: Точки над i
Надеюсь, статья была полезна. Следующая на очереди тема — раздачаслонов адресов.
R6#sh ipv6 interface brief
FastEthernet0/0 [up/up]
FE80::218:18FF:FE45:F0E2
1::1
1::2
1::3
1::10
1::100:500
2::1
2::2
Причём каждый из этих адресов может быть использован наравне с другими. Как так?
Важные изменения в IPv6
- Адресов на интерфейсе может быть много.
- У адресов есть scope — область видимости или область действия.
- Активно используются адреса с областью действия в пределах сегмента — так называемые link-local.
- Адреса могут быть сгенерированы самостоятельно.
Теперь подробнее.
1. Много адресов на интерфейсе
Конечно можно возразить, что в IPv4 тоже были различные методы, как назначить на интерфейс несколько адресов (secondary, alias и так далее). Но в IPv6 адреса сделали равными, и это открывает широкие возможности.
К примеру, узел может использовать один адрес для связи в своей локальной сети, другой адрес для связи в пределах организации и третий — для доступа в Интернет. Или сразу 10 для доступа в Интернет — на каждый сайт отправлять запросы с нового адреса.
Введён механизм предпочтения и старения адресов, с помощью которого можно делать плавную смену адресов в сети. На первом этапе все запросы начинают отправляться с новых адресов, но узлы продолжают откликаются и на старые тоже. Затем ещё через некоторое время старые адреса полностью списываются в утиль.
На первый взгляд может показаться «Ну и ладно», однако такие маленькие детали приведут к совсем другой логике назначения адресов.
2. Scope
Опять же, формально область действия была и у адресов в IPv4.
Есть link-local адреса. Они обычно известны под кодовым именем "$@#*!!! Опять DHCP не работает!" и выбираются из диапазона 169.254.0.0/16. Но вообще-то у них есть функции помимо «Дать админу понять, что его DHCP-сервер не выдаёт адреса».
Во-первых, такой адрес может быть автоматически сгенерирован самим устройством. Во-вторых, он вполне подходит для связи внутри сети. Ограничение: он вообще-то не должен маршрутизироваться, ибо link-local.
Кроме них, RFC 1918 задаёт три диапазона приватных адресов: всеми любимый 192.168.0.0/16, большой 10.0.0.0/8 и незаслуженно забываемый 172.16.0.0/12 (т.е. от 172.16.0.0 до 172.31.255.255). Они маршрутизируются, но только в пределах вашей внутренней сети. Для связи в Интернете их использовать нельзя.
Наконец, есть (недостаточно) много уникальных («публичных», «белых») адресов, которые выдаются в пользование организациям и провайдерам и подходят для связи в глобальном масштабе.
Существенное ограничение IPv4: нельзя использовать эти адреса одновременно. Либо link-local, и сиди без связи с другими сетями, либо приватные, но без NAT в Интернет не попасть, или публичные, которые подходят для всего, но нынче в страшном дефиците.
В IPv6 одновременно можно использовать адреса с разной областью действия. Надо постучаться к соседу по сети — используем link-local. Пошли в Интернет — берём глобально-уникальный.
Для узлов предусмотрены три варианта адресов:
- Link-local. Диапазон FE80::/10. Обязан быть на всех узлах с IPv6. Создаётся узлом самостоятельно (например, по EUI-64), либо можем задать его ручками. Как следует из названия, действует в пределах сегмента, поэтому уникальность требуется только в пределах этого сегмента (как у MAC-адресов, например). Отсюда на разных интерфейсах может быть одинаковым.
- Unique-local address (ULA). Это аналог «приватных» адресов. Scope — вообще говоря, глобальный (RFC 4193), но в Интернете их маршрутизировать никто не обязан, поэтому в большинстве случаев будут срезаться провайдером, например. Назначать можно по аналогии с адресами 192.168..., только теперь их много больше, поэтому вероятность выбрать одинаковые гораздо ниже.
Примечание
В IPv4 есть одна неприятная ситуация с приватными адресами, когда фирма А покупает фирму Б, и в этих фирмах используется одинаковая сеть (в худшем случае 10.0.0.0/8). Сращивать их — головная боль. Хотя адреса ULA можно брать любые, рекомендуется их генерировать случайным образом и заносить в один из общественных каталогов (например сюда). Это гарантирует очень маленькую вероятность пересечения. Если же вы возьмёте «красивые» адреса ULA, и потом вам придётся сращивать одинаковые сети на пару с другим таким же неудачником админом — сами виноваты.
- Глобально уникальные адреса. Таких больше всего. Маршрутизируются, уникальны на всей планете, прямой аналог публичных IPv4 адресов.
Примечание
Ранее существовали т.н. site-local адреса со своей областью действия — одной площадкой (site). Но разработчики IPv6 пришли к выводу, что понятие площадки слишком мутное, и от site-local отказались в пользу ULA.
Кроме общего понятия «область действия», у каждого конкретного адреса на конкретном интерфейсе возникает зона действия. Это часть топологии, на которую распространяется область действия данного адреса с данного интерфейса. Для программистов обычно предлагается такое объяснение: область действия — это абстрактный класс, а зона действия — экземпляр класса. Например, у link-local-адреса на интерфейсе Fa0/0 зоной действия будет сегмент сети, подключенный к интерфейсу Fa0/0.
Границы зон проходят по узлам. Отсюда link-local адреса на разных интерфейсах маршрутизатора будут лежать в разных зонах.
Визуализировать области действия и зоны действия поможет картинка:
Побочный эффект: возникает двусмысленность. Если мы говорим «Отправь пакет на FE80::101», то встречный вопрос будет «На который из интерфейсов?», потому что данный адрес может быть на любом из интерфейсов. Поэтому для link-local адресов обязательно уточняется интерфейс, который будет использоваться. В Windows используется записи вида FE80::1%5, где после символа "%" идёт ID интерфейса. В Linux применяется название (FE80::1%eth0).
3. Польза от link-local адресов
Возможность одновременно использовать адреса разных типов открывает очень интересные возможности.
Возьмём вот такую топологию:
Сколько подсетей нужно, чтобы у нас была связь по IP между компьютером и сервером?
В IPv4 понадобится 4 подсети, и даже если мы будем брать сети /31, это 8 адресов.
Сколько подсетей достаточно будет настроить в IPv6?
Правильный ответ
Две, одна между компьютером и Router0, а другая между сервером и Router2. Остальные адреса могут быть link-local, их можно сгенерировать автоматически.
Как это возможно?
А очень просто. Маршрутизация работает хоп за хопом. На каждом этапе нам нужно знать только исходящий интерфейс и адрес следующего перехода, причём физический, а IP нам нужен постольку-поскольку.
Компьютер знает link-local адрес ближайшего роутера (Router0). Router0 знает link-local следующего в цепочке (Router1). Router1 знает адрес Router2. Router2 может доставить сообщение серверу. Обратно так же.
Уточнение: Как справедливо заметил в комментариях Alukardd, такая возможность есть и в IPv4. Поэтому в Интернете вы вполне можете увидеть приватные адреса в результатах трассировки.
Проверим.
Включим маршрутизацию IPv6:
Router#conf t
Router(config)#ipv6 unicast-routing
Включим IPv6 на интерфейсах, адреса link-local создадутся автоматически:
Router(config)#interface fa0/0
Router(config-if)#ipv6 enable
Router(config-if)#interface fa0/1
Router(config-if)#ipv6 enable
Router(config-if)#end
Router#
Проверяем:
Router#show ipv6 interface brief
FastEthernet0/0 [up/up]
FE80::201:C7FF:FE8D:B001
FastEthernet0/1 [up/up]
FE80::201:C7FF:FE8D:B002
Настраиваем глобальные адреса:
Router0#conf t
Router0(config)#interface fa0/0
Router0(config-if)#ipv6 address 1::1/64
Router2#conf t
Router2(config)#interface fa0/1
Router2(config-if)#ipv6 address 2::1/64
Обратите внимание, что на компьютерах в общем случае ничего настраивать не нужно, адреса будут автоматически получены. Каким образом — тема отдельной статьи.
Наконец, понадобится маршрутизация. Настроим OSPFv3.
Router0#conf t
Router0(config)#ipv6 router ospf 1
%OSPFv3-4-NORTRID: OSPFv3 process 1 could not pick a router-id,please configure manually
!Обратите внимание, нужно настроить router-id, для каждого из роутеров свой уникальный
Router0(config-rtr)#router-id 1.0.0.0
Router0(config-rtr)#exit
Router0(config)#interface fa0/0
Router0(config-if)#ipv6 ospf 1 area 0
Router0(config-if)#interface fa0/1
Router0(config-if)#ipv6 ospf 1 area 0
Повторяем процедуру на остальных роутерах (меняя router-id, само собой). После этого у нас установится соседство (по link-local адресам!), и в таблицу маршрутизации попадут нужные маршруты.
Router0#sh ipv6 route
IPv6 Routing Table - 4 entries
Codes: C - Connected, L - Local, S - Static, R - RIP, B - BGP
U - Per-user Static route, M - MIPv6
I1 - ISIS L1, I2 - ISIS L2, IA - ISIS interarea, IS - ISIS summary
O - OSPF intra, OI - OSPF inter, OE1 - OSPF ext 1, OE2 - OSPF ext 2
ON1 - OSPF NSSA ext 1, ON2 - OSPF NSSA ext 2
D - EIGRP, EX - EIGRP external
C 1::/64 [0/0]
via ::, FastEthernet0/0
L 1::1/128 [0/0]
via ::, FastEthernet0/0
O 2::/64 [110/3]
via FE80::201:63FF:FE59:4501, FastEthernet0/1
После чего можно убедиться, что всё работает.
На грани экстрима
Можно обойтись всего двумя глобальными адресами (на компьютер и на сервер). Однако в этом случае на Router0 и Router2 придётся создавать статические маршруты до компьютера и сервера, соответственно, поскольку самостоятельно роутеры об этих адресах не узнают. Затем можно сделать редистрибуцию в OSPF и проверить, что связь даже в таком странноватом случае будет.
Вывод: для транзита трафика достаточно использовать link-local адреса. Глобально-уникальные адреса и ULA нужны будут только в том случае, если вы хотите обратиться к самому устройству (к примеру, зайти на роутер по SSH).
Несомненный плюс маршрутизации по link-local адресам в том, что убирается привязка к конкретной адресации. Можно привести такую аналогию: в IPv4 маршрут записывался через названия улиц и домов — «По улице Ленина до дома 51 и направо». В IPv6 маршрут можно записать как «два светофора прямо, на третьем направо». В случае смены адресации («переименования улиц») маршруты IPv4 нужно перестраивать заново, а в IPv6 всё продолжит работать как обычно.
4. Автоматическое назначение адресов
Про EUI-64 разъяснение было ранее, но сама тема в целом достойна отдельной статьи.
IPv6-адреса через EUI-64: Точки над i
Надеюсь, статья была полезна. Следующая на очереди тема — раздача
