По работе я несколько раз сталкивался с мнением, что настраивать QoS в не перегруженной ethernet сети не нужно для успешного функционирования таких сервисов, как IPTV и VoIP. Это мнение стоило мне и моим коллегам многих нервных клеток и часов на диагностику фантомных проблем, поэтом постараюсь как можно проще рассказать о том, почему это мнение неверно.
Меня зовут Владимир и я работаю сетевым инженером в одном из небольших ISP в Санкт-Петербурге.
Одним из оказываемых нами сервисов является L2VPN под транспорт IPTV потоков. На примере этого сервиса я буду вести рассказ.
Начинается всё с обращения в техподдержку от клиента-оператора с жалобой на качество IPTV — картинка сыпется («артефакты»), пропадает звук, в общем стандартный набор. IPTV у нас в сети классифицируется в очередь assured forwarding, поэтому диагностика заключается в том, чтобы пробежаться по железкам на маршруте и проверить, что в AF очереди на egress нет потерь, а на ingress нет физических ошибок. После этого мы бодро рапортуем клиенту, что в нашей зоне ответственности потерь не обнаружено, рекомендуем клиенту искать проблему у себя или поставщика IPTV, и идём пить чай с печеньем.
Но клиент давит и продолжает настаивать, что виноваты мы, а у него всё отлично. Мы проверяем всё ещё раз, смотрим корректность классификаторов и маркировку пакетов от клиента, завязывается диалог и на каком-то этапе задаём вопрос «а как у вас сконфигурирован QoS на сети?», на что получаем ответ «никак, у нас интерфейсы даже на 50% не загружены поэтому нам QoS не нужен». Тяжёлый вздох и поехали.
Обычно график загрузки на который все смотрят имеет интервал в 5 минут. Если «real time» — то несколько секунд, начиная от 1. К сожалению и к счастью, современное сетевое оборудование оперирует периодами не в 5 минут и не в 1 секунду даже, а пикосекундами. То, что в течении секунды интерфейс не был загружен на 100%, не значит, что он точно так же не был загружен и в течении нескольких миллисекунд.
Здесь мы приходим к концептуальному понятию — микробёрст(microburst). Это такой очень короткий период времени, когда количество принимаемых устройством данных становится больше чем интерфейс способен отправить.
Обычно первая реакция — как так?! Мы же живём в эпоху скоростных интерфейсов! 10Gb/s уже обыденность, 40 и 100Gb/s внедряется повсеместно, а мы ждём уже 1Tb/s интерфейсы.
На самом деле, чем выше скорость интерфейсов, тем жёстче становятся микробёрсты и их эффект на сеть.
Механизм возникновения очень прост, я его рассмотрю на примере трёх 1Gb/s интерфейсов, где трафик из двух из них уходит через третий.
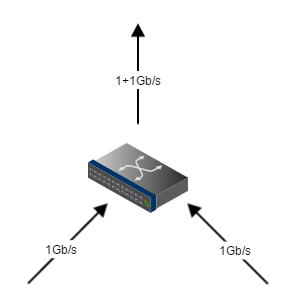
Это единственное необходимое условие для возникновения микробёрста — чтобы скорость входящих (ingress) интерфейсов превышала скорость исходящего (egress) интерфейса. Ничего не напоминает? Это же традиционная схема уровня агрегации в ethernet сети — множество портов (ingress) сливают трафик в один аплинк (egress). Так строят сети абсолютно все — от операторов связи до дата-центров.
У каждого egress интерфейса есть очередь отправки tx-ring, которая представляет из себя кольцевой буфер. Туда складываются пакеты для отправки в сеть и конечно же этот буфер имеет конечный размер. Но у ingress интерфейсов на отправляющей стороне тоже есть такие же кольцевые буферы, которые обеспечивают такой-же line-rate. Что произойдёт, если они начнут отправлять трафик одновременно? У нашего egress интерфейса не хватит места в его tx-ring, так как заполняться он будет в два раза быстрее, чем он способен отправлять пакеты. Оставшиеся пакеты нужно где-то хранить. В общем случае это другой буфер, который мы называем очередью (queue). Пока в tx-ring нет места, пакет хранится в очереди и ждёт свободного места в tx-ring. Но вот беда — у очереди память тоже конечна. Что произойдёт, если ingress интерфейсы работают на line-rate достаточно долго? Память в очереди тоже закончится. В этом случае новому пакету уже негде храниться, и он будет отброшен — такая ситуация называется tail drop.
Сколько времени нужно, чтобы такой сценарий стал реальностью? Давайте посчитаем.
Самое сложное — это найти ёмкость буфера интерфейса. Вендоры не очень активно публикуют такую информацию. Но возьмём, для примера, период в 200ms — дольше держать пакет в очереди обычно смысла не имеет, да и это уже очень много.
Для 1Gb/s интерфейса нам потребуется (1000000000 * 0.2) / 8 = 25MB памяти. Сколько времени нужно работать на line-rate двум 1Gb/s интерфейсам, чтобы полностью забить буфер? 200ms. Это время за которое передаются 25MB со скоростью 1Gb/s. Да, ingress интерфейсов то у нас два, но egress интерфейс то тоже без дела не сидит и отправляет данные с той же скоростью, поэтому 200ms.
Это сравнительно много. А 10Gb/s ingress интерфейсу сколько времени понадобится чтобы перегрузить 200ms буфер 1Gb/s интерфейса? ~22ms. Это уже ощутимо меньше.
А сколько нужно памяти, чтобы хранить 200ms для 10Gb/s интерфейса? Уже 250MB. Это не то чтобы много по современным меркам, но ветер дует именно в эту сторону — скорости растут, и чтобы сохранять глубину буфера требуется всё больше и больше памяти, что выливается в инженерные и экономические проблемы, а чем меньше буфер тем быстрее микробёрст забьёт его.
Получается вечный вопрос для инженеров вендоров — сколько памяти давать интерфейсу в железе? Много — дорого и каждая следующая миллисекунда становится бессмысленнее и бессмысленнее. Мало — микробёрсты будут приводить к большим потерям пакетов и жалобам от клиентов.
Для других сценариев можете посчитать сами, но итог всегда один и тот же — полностью забитая очередь и tail drops, а на графике полкой интерфейса и близко не пахнет, причём на любом периоде — что в 5 минут, что в 1 секунду.
Эта ситуация в пакетных сетях неизбежна — интерфейс проработает на line-rate меньше секунды, а потери уже будут. Единственный способ её избежать — строить сеть так, чтобы ingress скорость никогда не превышала egress скорость, а это непрактично и нереально.
Дальнейшая логика уже прослеживается и достаточно очевидна. Потери пакетов есть, а QoS не настроен — приоритетный трафик никак не классифицируется и не отличается от другого трафика, и попадает в одну общую очередь, где он имеет равные шансы быть дропнутым.
Что делать? Настраивать QoS. Обязательно классифицировать приоритетный трафик и помещать его в отдельную очередь которой выделять бОльший объём памяти. Конфигурировать алгоритмы отправки пакетов так, чтобы приоритетные пакеты попадали в tx-ring раньше других — таким образом их очередь будет очищаться быстрее.
Например, мы в своей практике используем следующий подход к очередям:
Assured forwarding(AF) — «подержи но доставь». В AF очередь классифицируется трафик, который требует гарантированной доставки, но не чувствителен к задержкам. Этой очереди выделен большой объём памяти, но даётся сравнительно мало места в tx-ring, и пакеты туда попадают позже других. Яркий пример такого трафика это IPTV — он буферизиуется на клиенте(VLC или STB), поэтому его можно задержать, но потеря превратится в артефакт изображения.
Expedited forwarding(EF) — «доставь мгновенно или выброси». Этой очереди выделятся минимум(или вообще никакой) памяти для очереди, но выставляется высший приоритет для попадания в tx-ring, чтобы пакет был отправлен как можно быстрее. Пример трафика — VoIP. Голос нельзя доставить поздно, иначе и кодек телефонии не сможет его корректно собрать — абонент услышит кваканье. В то же время потери отдельных пакетов на общем качестве голоса сильно не сказываются — он у людей итак не идеальный.
Есть ещё network control(NC) и best effort(BE), для управления сетью и всего остального соответственно, а трафик бывает ещё, например, телеконференции, который представляет из себя гибрид между VoIP и IPTV, но это уже совершенно отдельная тема, и настраивать QoS для них следует отдельно в каждой сети, в зависимости от топологии и прочих факторов. Всё вместе в целом это выглядит примерно так(картинка с сайта Cisco):

Надеюсь теперь вы будете настраивать QoS в своей сети?
Меня зовут Владимир и я работаю сетевым инженером в одном из небольших ISP в Санкт-Петербурге.
Одним из оказываемых нами сервисов является L2VPN под транспорт IPTV потоков. На примере этого сервиса я буду вести рассказ.
Начинается всё с обращения в техподдержку от клиента-оператора с жалобой на качество IPTV — картинка сыпется («артефакты»), пропадает звук, в общем стандартный набор. IPTV у нас в сети классифицируется в очередь assured forwarding, поэтому диагностика заключается в том, чтобы пробежаться по железкам на маршруте и проверить, что в AF очереди на egress нет потерь, а на ingress нет физических ошибок. После этого мы бодро рапортуем клиенту, что в нашей зоне ответственности потерь не обнаружено, рекомендуем клиенту искать проблему у себя или поставщика IPTV, и идём пить чай с печеньем.
Но клиент давит и продолжает настаивать, что виноваты мы, а у него всё отлично. Мы проверяем всё ещё раз, смотрим корректность классификаторов и маркировку пакетов от клиента, завязывается диалог и на каком-то этапе задаём вопрос «а как у вас сконфигурирован QoS на сети?», на что получаем ответ «никак, у нас интерфейсы даже на 50% не загружены поэтому нам QoS не нужен». Тяжёлый вздох и поехали.
Обычно график загрузки на который все смотрят имеет интервал в 5 минут. Если «real time» — то несколько секунд, начиная от 1. К сожалению и к счастью, современное сетевое оборудование оперирует периодами не в 5 минут и не в 1 секунду даже, а пикосекундами. То, что в течении секунды интерфейс не был загружен на 100%, не значит, что он точно так же не был загружен и в течении нескольких миллисекунд.
Здесь мы приходим к концептуальному понятию — микробёрст(microburst). Это такой очень короткий период времени, когда количество принимаемых устройством данных становится больше чем интерфейс способен отправить.
Обычно первая реакция — как так?! Мы же живём в эпоху скоростных интерфейсов! 10Gb/s уже обыденность, 40 и 100Gb/s внедряется повсеместно, а мы ждём уже 1Tb/s интерфейсы.
На самом деле, чем выше скорость интерфейсов, тем жёстче становятся микробёрсты и их эффект на сеть.
Механизм возникновения очень прост, я его рассмотрю на примере трёх 1Gb/s интерфейсов, где трафик из двух из них уходит через третий.
Это единственное необходимое условие для возникновения микробёрста — чтобы скорость входящих (ingress) интерфейсов превышала скорость исходящего (egress) интерфейса. Ничего не напоминает? Это же традиционная схема уровня агрегации в ethernet сети — множество портов (ingress) сливают трафик в один аплинк (egress). Так строят сети абсолютно все — от операторов связи до дата-центров.
У каждого egress интерфейса есть очередь отправки tx-ring, которая представляет из себя кольцевой буфер. Туда складываются пакеты для отправки в сеть и конечно же этот буфер имеет конечный размер. Но у ingress интерфейсов на отправляющей стороне тоже есть такие же кольцевые буферы, которые обеспечивают такой-же line-rate. Что произойдёт, если они начнут отправлять трафик одновременно? У нашего egress интерфейса не хватит места в его tx-ring, так как заполняться он будет в два раза быстрее, чем он способен отправлять пакеты. Оставшиеся пакеты нужно где-то хранить. В общем случае это другой буфер, который мы называем очередью (queue). Пока в tx-ring нет места, пакет хранится в очереди и ждёт свободного места в tx-ring. Но вот беда — у очереди память тоже конечна. Что произойдёт, если ingress интерфейсы работают на line-rate достаточно долго? Память в очереди тоже закончится. В этом случае новому пакету уже негде храниться, и он будет отброшен — такая ситуация называется tail drop.
Сколько времени нужно, чтобы такой сценарий стал реальностью? Давайте посчитаем.
Самое сложное — это найти ёмкость буфера интерфейса. Вендоры не очень активно публикуют такую информацию. Но возьмём, для примера, период в 200ms — дольше держать пакет в очереди обычно смысла не имеет, да и это уже очень много.
Для 1Gb/s интерфейса нам потребуется (1000000000 * 0.2) / 8 = 25MB памяти. Сколько времени нужно работать на line-rate двум 1Gb/s интерфейсам, чтобы полностью забить буфер? 200ms. Это время за которое передаются 25MB со скоростью 1Gb/s. Да, ingress интерфейсов то у нас два, но egress интерфейс то тоже без дела не сидит и отправляет данные с той же скоростью, поэтому 200ms.
Это сравнительно много. А 10Gb/s ingress интерфейсу сколько времени понадобится чтобы перегрузить 200ms буфер 1Gb/s интерфейса? ~22ms. Это уже ощутимо меньше.
А сколько нужно памяти, чтобы хранить 200ms для 10Gb/s интерфейса? Уже 250MB. Это не то чтобы много по современным меркам, но ветер дует именно в эту сторону — скорости растут, и чтобы сохранять глубину буфера требуется всё больше и больше памяти, что выливается в инженерные и экономические проблемы, а чем меньше буфер тем быстрее микробёрст забьёт его.
Получается вечный вопрос для инженеров вендоров — сколько памяти давать интерфейсу в железе? Много — дорого и каждая следующая миллисекунда становится бессмысленнее и бессмысленнее. Мало — микробёрсты будут приводить к большим потерям пакетов и жалобам от клиентов.
Для других сценариев можете посчитать сами, но итог всегда один и тот же — полностью забитая очередь и tail drops, а на графике полкой интерфейса и близко не пахнет, причём на любом периоде — что в 5 минут, что в 1 секунду.
Эта ситуация в пакетных сетях неизбежна — интерфейс проработает на line-rate меньше секунды, а потери уже будут. Единственный способ её избежать — строить сеть так, чтобы ingress скорость никогда не превышала egress скорость, а это непрактично и нереально.
Дальнейшая логика уже прослеживается и достаточно очевидна. Потери пакетов есть, а QoS не настроен — приоритетный трафик никак не классифицируется и не отличается от другого трафика, и попадает в одну общую очередь, где он имеет равные шансы быть дропнутым.
Что делать? Настраивать QoS. Обязательно классифицировать приоритетный трафик и помещать его в отдельную очередь которой выделять бОльший объём памяти. Конфигурировать алгоритмы отправки пакетов так, чтобы приоритетные пакеты попадали в tx-ring раньше других — таким образом их очередь будет очищаться быстрее.
Например, мы в своей практике используем следующий подход к очередям:
Assured forwarding(AF) — «подержи но доставь». В AF очередь классифицируется трафик, который требует гарантированной доставки, но не чувствителен к задержкам. Этой очереди выделен большой объём памяти, но даётся сравнительно мало места в tx-ring, и пакеты туда попадают позже других. Яркий пример такого трафика это IPTV — он буферизиуется на клиенте(VLC или STB), поэтому его можно задержать, но потеря превратится в артефакт изображения.
Expedited forwarding(EF) — «доставь мгновенно или выброси». Этой очереди выделятся минимум(или вообще никакой) памяти для очереди, но выставляется высший приоритет для попадания в tx-ring, чтобы пакет был отправлен как можно быстрее. Пример трафика — VoIP. Голос нельзя доставить поздно, иначе и кодек телефонии не сможет его корректно собрать — абонент услышит кваканье. В то же время потери отдельных пакетов на общем качестве голоса сильно не сказываются — он у людей итак не идеальный.
Есть ещё network control(NC) и best effort(BE), для управления сетью и всего остального соответственно, а трафик бывает ещё, например, телеконференции, который представляет из себя гибрид между VoIP и IPTV, но это уже совершенно отдельная тема, и настраивать QoS для них следует отдельно в каждой сети, в зависимости от топологии и прочих факторов. Всё вместе в целом это выглядит примерно так(картинка с сайта Cisco):
Надеюсь теперь вы будете настраивать QoS в своей сети?
