Metacritic — англоязычный сайт-агрегатор, собирающий отзывы о музыкальных альбомах, играх, фильмах, телевизионных шоу и DVD-дисках. (с википедии).
Использованные библиотеки: lxml, asyncio, aiohttp (lxml — библиотека разбора HTML страниц с помощью Python, asyncio и aiohttp будем использовать для асинхронности и быстрого извлечения данных). Также будем активно использовать XPath. Кто не знает, что это такое, отличный туториал.
Сперва придется немного поработать ручками. Идем на www.metacritic.com/browse/games/genre/metascore/action/all?view=detailed и собираем все
URL-ы из этого списка:
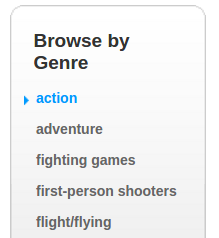
И сохраняем их в .json файл с именем genres.json. Мы будем применять эти ссылки, чтобы парсить все игры с сайта по жанрам.
Немного подумав, я решил собрать все ссылки на игры в .csv файлы, разделенные на жанры. Каждый файл будет иметь имя соответствующее жанру. Заходим по вышеупомянутой ссылке и сразу видим страницу жанра Action. Замечаем, что присутствует пагинация.
Смотрим в html-страницы:

И видим, что искомый элемент а, который содержит максимальное число страниц — наследник элемента li с уникальным аттрибутом class = page last_page, также замечаем, что url-ы всех страниц, кроме первой, имеют вид <url 1-ой страницы> + <&page=page_number>, и что вторая страница в параметре запроса имеет номер 1.
Собираем XPath для получения номера максимальной страницы:
//li[@class='page last_page']/a/text()
Теперь нужно получить каждую ссылку на каждую игру из этого листа.
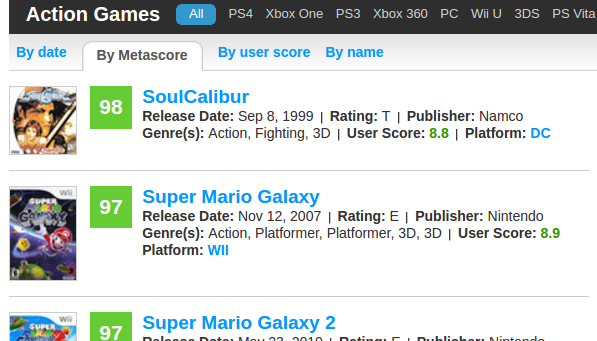
Заглядываем в разметку листа и изучаем html.
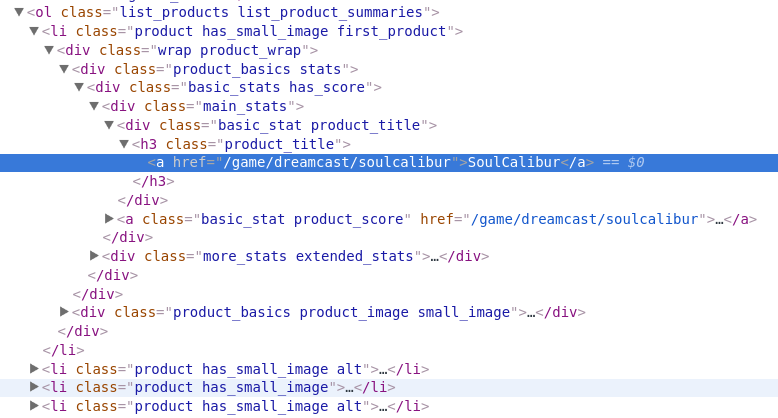
Во первых нам в качестве корневого элемента для поиска нужно получить сам список (ol). У него есть уникальный для html-кода страницы аттрибут class = list_products list_product_summaries. Затем видим, что li имеет дочерний элемент h3 с дочерним элементом a, в аттрибуте href которого и находится искомая ссылка на игру.
Собираем всё воедино:
//ol[@class='list_products list_product_summaries']//h3[@class='product_title']/a/@href
Отлично! Полдела сделано, теперь нужно программно организовать цикл по страницам, сбор ссылок и сохранение их в файлы. Для ускорения распараллелим операцию на все ядра нашего PC.
Сливаем все файлы со ссылками в один файл. Если вы под линуксом, то просто используем cat и перенаправляем STDOUT в новый файл. Под виндой напишем небольшой скрипт и запустим его в папке с файлами жанров.
Теперь у нас есть один большой .csv файл со ссылками на все игры на Metacritic. Достаточно большой, 25 тысяч записей. Плюс есть дупликаты, так как одна игра может иметь несколько жанров.
Каков наш план дальше? Пройтись по каждой ссылке и извлечь информацию о каждой игре.
Заходим, например, на страницу Portal 2.
Будем извлекать:
Чтобы сократить пост, сразу приведу xpath-ы, которыми извлекал данную информацию.
Название игры:
//h1[@class='product_title']//span[@itemprop='name']//text()
Платформ у нас может быть несколько, поэтому понадобятся два запроса:
//span[@itemprop='device']//text()
//li[@class='summary_detail product_platforms']//a//text()
Описание у нас находится в Summary:
//span[@itemprop='description']//text()
Metascore:
//span[@itemprop='ratingValue']//text()
Жанр:
//span[@itemprop='description']//text()
Дата выпуска:
//span[@itemprop='datePublished']//text()
Вспоминаем, что у нас 25 тысяч страниц и хватаемся за голову. Что делать? Даже с несколькими потоками будет долговато. Выход есть — асинхронность и неблокирующие корутины. Вот отличное видео от PyCon. Async-await упрощают асинхронное программирование в python 3.5.2. Туториал на Хабре.
Пишем код для нашего парсера.
Получаеся очень даже неплохо, на моем компьютере Intel i5 6600K, 16 GB RAM, lan 10 mb/s получалось где-то 10 игр/сек. Можно подправить код и адаптировать скрипт под музыку\фильмы.
Использованные библиотеки: lxml, asyncio, aiohttp (lxml — библиотека разбора HTML страниц с помощью Python, asyncio и aiohttp будем использовать для асинхронности и быстрого извлечения данных). Также будем активно использовать XPath. Кто не знает, что это такое, отличный туториал.
Получение ссылок на страницы всех игр
Сперва придется немного поработать ручками. Идем на www.metacritic.com/browse/games/genre/metascore/action/all?view=detailed и собираем все
URL-ы из этого списка:
И сохраняем их в .json файл с именем genres.json. Мы будем применять эти ссылки, чтобы парсить все игры с сайта по жанрам.
Немного подумав, я решил собрать все ссылки на игры в .csv файлы, разделенные на жанры. Каждый файл будет иметь имя соответствующее жанру. Заходим по вышеупомянутой ссылке и сразу видим страницу жанра Action. Замечаем, что присутствует пагинация.
Смотрим в html-страницы:
И видим, что искомый элемент а, который содержит максимальное число страниц — наследник элемента li с уникальным аттрибутом class = page last_page, также замечаем, что url-ы всех страниц, кроме первой, имеют вид <url 1-ой страницы> + <&page=page_number>, и что вторая страница в параметре запроса имеет номер 1.
Собираем XPath для получения номера максимальной страницы:
//li[@class='page last_page']/a/text()
Теперь нужно получить каждую ссылку на каждую игру из этого листа.
Заглядываем в разметку листа и изучаем html.
Во первых нам в качестве корневого элемента для поиска нужно получить сам список (ol). У него есть уникальный для html-кода страницы аттрибут class = list_products list_product_summaries. Затем видим, что li имеет дочерний элемент h3 с дочерним элементом a, в аттрибуте href которого и находится искомая ссылка на игру.
Собираем всё воедино:
//ol[@class='list_products list_product_summaries']//h3[@class='product_title']/a/@href
Отлично! Полдела сделано, теперь нужно программно организовать цикл по страницам, сбор ссылок и сохранение их в файлы. Для ускорения распараллелим операцию на все ядра нашего PC.
# get_games.py
import csv
import requests
import json
from multiprocessing import Pool
from time import sleep
from lxml import html
# Базовый домен.
root = 'http://www.metacritic.com/'
# При большом количестве запросов Metacritic выдает ошибку 429 с описанием 'Slow down'
# будем избегать её, останавливая поток на определенное количество времени.
SLOW_DOWN = False
def get_html(url):
# Metacritic запрещает запросы без заголовка User-Agent.
headers = {"User-Agent": "Mozilla/5.001 (windows; U; NT4.0; en-US; rv:1.0) Gecko/25250101"}
global SLOW_DOWN
try:
# Если у нас в каком-либо потоке появилась ошибка 429, то приостанавливаем все потоки
# на 15 секунд.
if SLOW_DOWN:
sleep(15)
SLOW_DOWN = False
# Получаем html контент страницы стандартным модулем requests
html = requests.get(url, headers=headers).content.decode('utf-8')
# Если ошибка в html контенте, то присваеваем флагу SLOW_DOWN true.
if '429 Slow down' in html:
SLOW_DOWN = True
print(' - - - SLOW DOWN')
raise TimeoutError
return html
except TimeoutError:
return get_html(url)
def get_pages(genre):
# Сложим все жанры в папку Games
with open('Games/' + genre.split('/')[-2] + '.csv', 'w') as file:
writer = csv.writer(file, delimiter=',',
quotechar='"', quoting=csv.QUOTE_MINIMAL)
# Структура url страниц > 1
genre_page_sceleton = genre + '&page=%s'
def scrape():
page_content = get_html(genre)
# Получаем корневой lxml элемент из html страницы.
document = html.fromstring(page_content)
try:
# Извлекаем номер последней страницы и кастим в int.
lpn_text = document.xpath("//li[@class='page last_page']/a/text()"
last_page_number = int(lpn_text)[0])
pages = [genre_page_sceleton % str(i) for i in range(1, last_page_number)]
# Не забываем про первую страницу.
pages += [genre]
# Для каждой страницы собираем и сохраняем ссылки на игры в файл жанра.
for page in pages:
document = html.fromstring(get_html(page))
urls_xpath = "//ol[@class='list_products list_product_summaries']//h3[@class='product_title']/a/@href"
# К ссылке каждой игры прибавляем url корня сайта.
games = [root + url for url in document.xpath(urls_xpath)]
print('Page: ' + page + " - - - Games: " + str(len(games)))
for game in games:
writer.writerow([game])
except:
# Скорее всего опять 429 ошибка. Парсим страницу заново.
scrape()
scrape()
def main():
# Загружаем ссылки на страницы жанров из нашего .json файла.
dict = json.load(open('genres.json', 'r'))
p = Pool(4)
# Простой пул. Функцией map отдаем каждому потоку его порцию жанров для парсинга.
p.map(get_pages, [dict[key] for key in dict.keys()])
print('Over')
if __name__ == "__main__":
main()
Сливаем все файлы со ссылками в один файл. Если вы под линуксом, то просто используем cat и перенаправляем STDOUT в новый файл. Под виндой напишем небольшой скрипт и запустим его в папке с файлами жанров.
from os import listdir
from os.path import isfile, join
onlyfiles = [f for f in listdir('.') if isfile(join(mypath, f))]
fout=open("all_games.csv","a")
for path in onlyfiles:
f = open(path)
f.next()
for line in f:
fout.write(line)
f.close()
fout.close()Теперь у нас есть один большой .csv файл со ссылками на все игры на Metacritic. Достаточно большой, 25 тысяч записей. Плюс есть дупликаты, так как одна игра может иметь несколько жанров.
Извлечение информации о всех играх
Каков наш план дальше? Пройтись по каждой ссылке и извлечь информацию о каждой игре.
Заходим, например, на страницу Portal 2.
Будем извлекать:
- Название игры
- Платформы
- Описание
- Metascore
- Жанр
- Дата выпуска
Чтобы сократить пост, сразу приведу xpath-ы, которыми извлекал данную информацию.
Название игры:
//h1[@class='product_title']//span[@itemprop='name']//text()
Платформ у нас может быть несколько, поэтому понадобятся два запроса:
//span[@itemprop='device']//text()
//li[@class='summary_detail product_platforms']//a//text()
Описание у нас находится в Summary:
//span[@itemprop='description']//text()
Metascore:
//span[@itemprop='ratingValue']//text()
Жанр:
//span[@itemprop='description']//text()
Дата выпуска:
//span[@itemprop='datePublished']//text()
Вспоминаем, что у нас 25 тысяч страниц и хватаемся за голову. Что делать? Даже с несколькими потоками будет долговато. Выход есть — асинхронность и неблокирующие корутины. Вот отличное видео от PyCon. Async-await упрощают асинхронное программирование в python 3.5.2. Туториал на Хабре.
Пишем код для нашего парсера.
from time import sleep
import asyncio
from aiohttp import ClientSession
from lxml import html
# Считываем ссылки на все игры из нашего файла, убираем дупликаты.
games_urls = list(set([line for line in open('Games/all_games.csv', 'r')]))
# Сюда будем складывать результат.
result = []
# Сколько всего страниц наша программа запарсила на данный момент.
total_checked = 0
async def get_one(url, session):
global total_checked
async with session.get(url) as response:
# Ожидаем ответа и блокируем таск.
page_content = await response.read()
# Получаем информацию об игре и сохраняем в лист.
item = get_item(page_content, url)
result.append(item)
total_checked += 1
print('Inserted: ' + url + ' - - - Total checked: ' + str(total_checked))
async def bound_fetch(sm, url, session):
try:
async with sm:
await get_one(url, session)
except Exception as e:
print(e)
# Блокируем все таски на 30 секунд в случае ошибки 429.
sleep(30)
async def run(urls):
tasks = []
# Выбрал лок от балды. Можете поиграться.
sm = asyncio.Semaphore(50)
headers = {"User-Agent": "Mozilla/5.001 (windows; U; NT4.0; en-US; rv:1.0) Gecko/25250101"}
# Опять же оставляем User-Agent, чтобы не получить ошибку от Metacritic
async with ClientSession(
headers=headers) as session:
for url in urls:
# Собираем таски и добавляем в лист для дальнейшего ожидания.
task = asyncio.ensure_future(bound_fetch(sm, url, session))
tasks.append(task)
# Ожидаем завершения всех наших задач.
await asyncio.gather(*tasks)
def get_item(page_content, url):
# Получаем корневой lxml элемент из html страницы.
document = html.fromstring(page_content)
def get(xpath):
item = document.xpath(xpath)
if item:
return item[-1]
# Если вдруг какая-либо часть информации на странице не найдена, то возвращаем None
return None
name = get("//h1[@class='product_title']//span[@itemprop='name']//text()")
if name:
name = name.replace('\n', '').strip()
genre = get("//span[@itemprop='genre']//text()")
date = get("//span[@itemprop='datePublished']//text()")
main_platform = get("//span[@itemprop='device']//text()")
if main_platform:
main_platform = main_platform.replace('\n', '').strip()
else:
main_platform = ''
other_platforms = document.xpath("//li[@class='summary_detail product_platforms']//a//text()")
other_platforms = '/'.join(other_platforms)
platforms = main_platform + '/' + other_platforms
score = get("//span[@itemprop='ratingValue']//text()")
desc = get("//span[@itemprop='description']//text()")
#Возвращаем словарь с информацией об игре.
return {'url': url,
'name': name,
'genre': genre,
'date': date,
'platforms': platforms,
'score': score,
'desc': desc}
def main():
#Запускаем наш парсер.
loop = asyncio.get_event_loop()
future = asyncio.ensure_future(run(games_urls))
loop.run_until_complete(future)
# Выводим результат. Можете сохранить его куда-нибудь в файл.
print(result)
print('Over')
if __name__ == "__main__":
main()Получаеся очень даже неплохо, на моем компьютере Intel i5 6600K, 16 GB RAM, lan 10 mb/s получалось где-то 10 игр/сек. Можно подправить код и адаптировать скрипт под музыку\фильмы.
