FCOS: полностью сверточное одноступенчатое обнаружение объектов - это детектор объектов без привязки. Он решает проблемы обнаружения объектов с помощью метода прогнозирования по пикселям, аналогичного сегментации. Большинство последних детекторов объектов без привязки или без привязки на основе глубокого обучения используют FCOS в качестве основы.
В этой статье мы обсудим следующее:
Основы FCOS: архитектура модели, кодирование истинности, декодирование предсказания и функция потерь.
Интуитивное объяснение всех фундаментальных понятий.
Где FCOS стоит по сравнению с другими моделями обнаружения объектов.
Мы также представим вывод FCOS с использованием PyTorch и TorchVision на изображениях и видео.
Кому будет полезна статья:
Те, кто хочет понять конвейер классификации глубокого обучения и хочет интуитивно изучить обнаружение объектов на основе глубокого обучения.
У вас есть опыт в обнаружении объектов на основе привязки, и вы хотите изучить обнаружение объектов без привязки.
Хотите глубже изучить FCOS – полностью сверточное одноступенчатое обнаружение объектов.
Хотел создать приложение с использованием предварительно обученной модели обнаружения объектов.
Оглавление
Основы обнаружения объектов
Обнаружение объектов на основе глубокого обучения в целом делится на два типа:
Обнаружение объектов на основе привязки и
Обнаружение объектов без привязки
Центральная сеть – объекты в виде точек объясните основы обнаружения объектов на основе глубокого обучения. Если вы не знакомы с основами обнаружения объектов, прочитайте следующие разделы:
Что такое обнаружение объектов в машинном обучении / глубоком обучении?
Что такое привязка при обнаружении объектов?
Что такое обнаружение объектов на основе привязки?
Что такое обнаружение объектов без привязки?
Является ли обнаружение объектов без привязки лучше, чем обнаружение объектов на основе привязки?
Компоненты обнаружения объектов на основе глубокого обучения.
Модель обнаружения объектов содержит следующие компоненты в конвейере:
Модель обнаружения объектов,
Кодирование достоверности,
Функция потери и
Декодирование прогнозирования модели.
Предполагая, что вы понимаете эти компоненты, мы объясним FCOS: полностью сверточное одноступенчатое обнаружение объектов в этой структуре.
Архитектура модели FCOS
FCOS означает Полностью сверточное одноступенчатое обнаружение объектов. Это мотивировано FCN: полностью сверточные сети для семантической сегментации. Он использует аналогичное пиксельное предсказание для обнаружения объектов. Давайте посмотрим, как это происходит.

Приведенный выше рисунок (рис. 1) описывает сетевую архитектуру FCOS. Он состоит из трех частей:
Магистраль,
Пирамида функций, и
Head
Три карты объектов из магистрали, C3, C4, и C5, ввод в сеть пирамиды объектов (FPN) в P3, P4, и P5 соответственно. Кроме того, выходные данные P5 поступают в P6, и вывод P6 подается в P7.
Вывод с P3 на P7 поступает в head сеть.
Если мы увеличим масштаб head сети, можно увидеть, что она имеет две ветви:
Для классификации: Он состоит из двух частей: одна для прогнозирования достоверности класса, а другая для прогнозирования центра объекта. Вы уже узнали, что такое уверенность в классе в контексте обнаружения объектов. Мы подробно рассмотрим центрированность позже в статье.
Для регрессии: Ветвь регрессии отвечает за прогнозирование ограничения.
Форма выходного объекта, показанная на изображении, соответствует размеру входного изображения 800 x 1024.
Выходные шаги (отношение дискретизации к размеру входного изображения) при C3 / P3, C4 / P4, C5 / P5, P6, и P7 являются 8, 16, 32, 64, и 128 соответственно. По мере увеличения разрешение вывода уменьшается; например, ширина и высота вывода на уровне C3 /P3 это 100 x 128 и уровень C4 / P4 это 50 x 64.
Ширина и высота выходного сигнала head зависят от их уровня. Например, ширина и высота на уровне P7 равны 7 x 8 и на уровне P6, они 13 x 16 соответственно. Однако на всех уровнях глубина одинакова и выглядит следующим образом:
Глубина классификации равна C, где C - количество классов объектов.
Глубина центра равна один. Следовательно, он предсказывает качество централизации ограничения; одного скаляра достаточно для представления качества.
Глубина регрессии равна четыре поскольку для представления ограничивающей рамки в 2-D самолет.
Кодирование основной истины в FCOS
Важно понимать кодирование истинности, поскольку последние детекторы объектов без привязки используют аналогичное кодирование, например, Детектор объектов YOLOx и Обнаружение объектов YOLOv6.
Давайте теперь углубимся в FCOS кодирование.
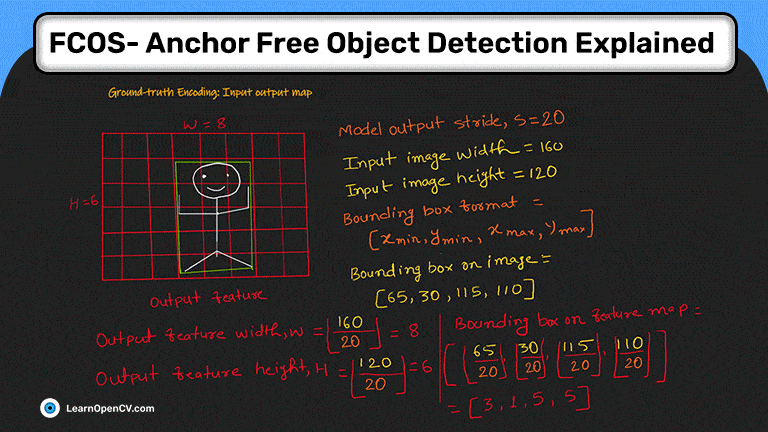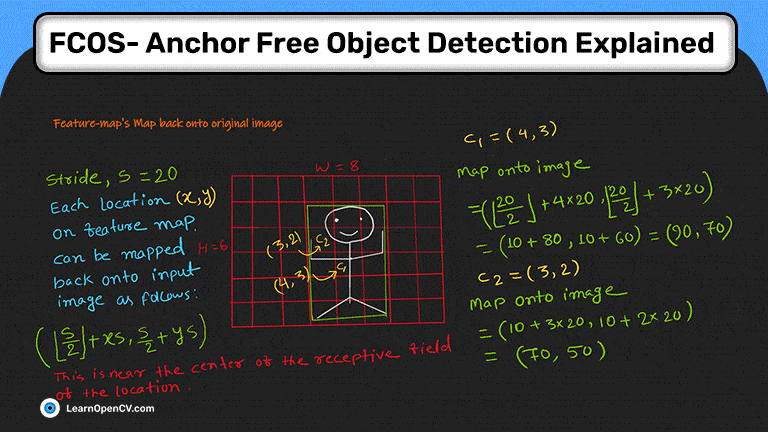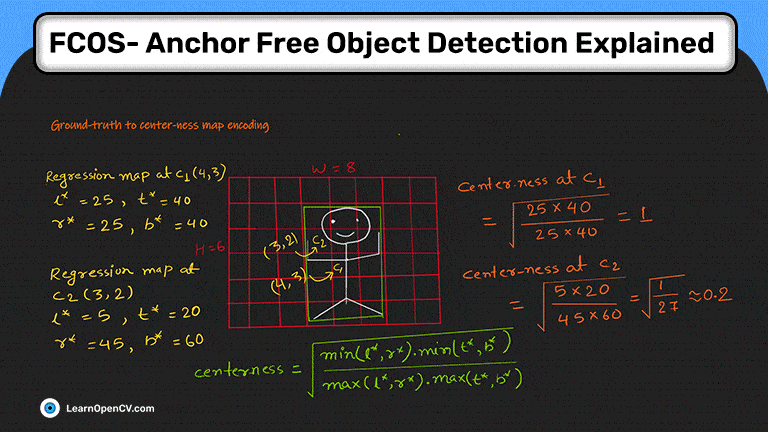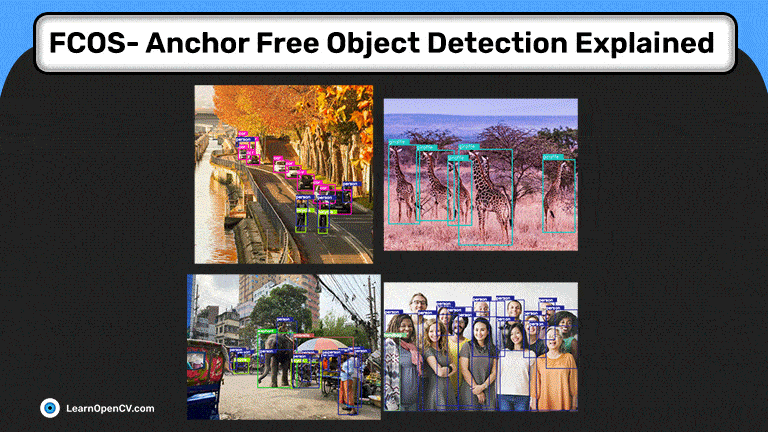
Для иллюстрации кодирования предположим, что модель имеет только один уровень вывода и шаг модели, s это 20.
Входное изображение 160 x120, поэтому функция вывода будет 8 x 6, как показано ниже (рис. 2).

Формат ограничивающей рамки
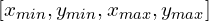
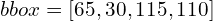
Ограничивающий прямоугольник на карте объектов (объяснение на рис. 2):
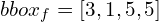
Для каждой выходной функции требуется соответствующая метка. Ярлык должен исходить из основной истины. Это означает, что нам нужно закодировать основную истину, чтобы ее структура соответствовала структуре выходных объектов.
Следовательно, основная истина должна быть сопоставлена с тремя моделями:
Классификация
Центрированность, и
Регрессия
Обоснование истинности кодирования классификационной карты
Давайте рассмотрим три класса (человек, собака, и мяч) без включения фонового класса. В этом случае карта классификации FCOS будет иметь три выходных канала, по одному для каждого класса.
Маркировка канала зависит только от ограничивающих рамок, принадлежащих классу, за который отвечает канал. Например, посмотрите на изображение ниже (рис. 3).
")
Для канал класса person, значения внутри ограничивающей рамки являются один, а другие значения являются ноль. Все значения для других каналов класса ноль потому что нет экземпляра для собака и мяч.
Что делать, если две ограничивающие рамки перекрываются?
Если две ограничивающие рамки перекрываются, метка меньшей ограничивающей рамки будет меткой для классификации. Таким образом, ограничивающий прямоугольник также регрессирует для метки, которая имеет меньший ограничивающий прямоугольник. Например, посмотрите на изображение ниже (рис. 4).
")
Меньшая ограничивающая рамка имеет меньшее количество представлений на карте классификации. Поэтому имеет смысл расставить приоритеты.
Как он заботится о фоновом режиме (без класса объекта)?
Для данного x и y координата, если все значения по глубине (каналам) равны ноль, тогда ячейка является фоновой меткой. Другими словами, если ячейка не имеет значения 1 для любого канала ячейка принадлежит фоновой.
Как влияет местоположение (x, y) на карте объектов обратно на входное изображение?
Посмотрите на изображение ниже (рис. 5). Здесь сопоставление для два пункта, c1 и c2 , показан.

Обратите внимание, что отображенная точка на исходном изображении находится недалеко от центра местоположения воспринимающего поля.
Прежде чем обсуждать FCOS центрированность давайте поговорим о кодировании карты регрессия.
Основа-истина для кодирования карты регрессии
Модель предсказывает ограничивающую рамку для точки, в которой метка класса равна единице.
Он имеет четыре канала для прогнозирования четырех чисел для ограничивающей рамки.
Кодировка карты регрессии имеет следующие четыре числа:
расстояние до левого края, l*,
расстояние до верхнего края, t*,
расстояние до правого края, r*, и
расстояние до нижнего края, b*
Изображение ниже (рис. 6) демонстрирует вычисление кодирования карты регрессии FCOS.

Мы знаем, что в случае перекрытия ограничивающей рамки мы выберем наименьшую ограничивающую рамку для регрессии. Однако в случае многоуровневых выходных данных перекрытие на одной и той же карте объектов будет редким.
Кодирование карты от истины к центру
Существует один канал для централизации. Как следует из названия, если точка находится в центре ограничивающей рамки, ее значение должно быть равно единице, и по мере удаления точки от центра ее значение должно уменьшаться.
Изображение ниже (рис. 7) содержит уравнение для централизации и демонстрирует вычисление кодирования карты централизации.

Вот пример тепловой карты центра FCOS на изображении ниже (рис. 8).

Кодирование истинности для многоуровневого (FPN) прогнозирования в FCOS
Шаги кодирования остаются неизменными для многоуровневых. Однако выходы разных уровней имеют разные шаги. Следовательно, следует использовать шаги кодирования для соответствующего уровня.
Все ограничивающие рамки не обязательно кодировать на всех уровнях. Грубо говоря, меньшие ограничивающие рамки будут кодироваться на больших картах объектов и наоборот.
Изображение ниже (рис. 9) демонстрирует ограничивающую рамку и критерии сопоставления уровня объектов.

В чем преимущество многоуровневой системы (FPN) в FCOS?
Начальные функции (начиная с ввода) имеют больше локализации и меньше информации об объекте. Однако более поздние слои имеют больше объектности и меньше информации о локализации. Например, на приведенном выше изображении (рис. 9) C3 - это начальный объект, а C5 - более поздний объект. Здесь, в пирамиде объектов, P5 переходит в P4, а P4 - в P3. Здесь соединение предоставляет больше информации об объекте для начальных слоев.
Еще одним важным преимуществом является высокий BPR (наилучший возможный отзыв).
Что такое BPR (наилучший возможный отзыв) при обнаружении объектов?
Верхняя граница скорости отзыва, которую может достичь детектор, называется BPR (наилучший возможный отзыв). Это не вызов прогноза модели; вместо этого это вызов основного кодирования истины.
Как правило, отзыв используется в контексте прогнозирования. Итак, что такое отзыв в кодировании?
Когда мы кодируем основную истину, возможно, что несколько основных истин могут иметь закодированное представление в обучающей выборке из-за ограничений алгоритма кодирования.
Это дает понять, что такое BPR и почему это важно.
Как FPN (многоуровневый вывод) в FCOS помогает при высоком BPR?
Предположим, что есть две ограничивающие рамки. Одна немного меньше и полностью внутри, другая больше.
Для одного вывода для заданного шага оба блока могут иметь одну и ту же классификационную карту. В этом случае для данного алгоритма меньшее ограничение будет иметь закодированные карты, а большее - нет. Следовательно, для большего ограничивающего прямоугольника нет сопоставления.
Однако в случае многоуровневых выходных данных могут быть другие слои, которые могут вместить большую ограничительную рамку.
Ниже приведена таблица из документа, в которой сравнивается BPR RetinaNet и FCOS.

Здесь вы можете видеть, что даже при использовании FPN BPR не равен 100%.
Декодирование прогнозирования модели в FCOS
Декодирование предсказания означает преобразование предсказания модели в стандартный формат достоверности.
Этапы декодирования вывода модели заключаются в следующем:
Из выходных данных классификационной head сети получаем точное местоположение. Например, местоположения с оценкой более 0,5 могут считаться надежными местоположениями, если существует три класса объектов.
Для определения надежных местоположений получите выходные данные регрессии из заголовка регрессии.
Вычислите ширину (l + r) и высоту (t + b) из выходных данных регрессии.
Сопоставьте достоверные местоположения с входным изображением.
Получите значение центрирования для уверенных местоположений из head центрирования.
Обновите показатель достоверности, умножив его на значение централизации.
Затем используйте NMS для фильтрации декодированных ограничивающих рамок.
Функции потери в FCOS
Существует три функции потерь для выходного слоя (рис. 10).:
Потеря классификации: используется потеря фокуса.
Потеря регрессии: это потеря векселей.
Потеря централизации: это потеря BCE (двоичная кросс-энтропийная ошибка).

рис. 10: Функции потери FCOS
Важно отметить, что для одиночных ограничивающих рамок существует несколько положительных выборок. Таким образом, положительный и отрицательный образец менее искажены. Это делает обучение стабильным.
Теперь, когда мы изучили основы FCOS, давайте подведем итоги в следующем разделе.
Как работает FCOS?
FCOS использует архитектуру Resnet-FPN. Таким образом, он выводит разные разрешения. Архитектура FPN обеспечивает высокий BPR (наилучший возможный отзыв) и лучший прогнозируемый отзыв.
Для обучения модели основные истины, ограничивающие рамки, должны быть закодированы определенным образом; это также благородство FCOS. Этот уникальный способ помогает модели иметь менее искаженную обучающую выборку.
Он использует три функции потерь – потеря фокуса для классификации, потеря BCE для централизации и потеря IoU для регрессии.
Для получения стандартного формата наземной истины требуется декодирование предсказания модели.
Результаты FCOS
Вот таблица, в которой сравнивается карта RetinaNet и FCOS.

Вы можете видеть, что FCOS превосходит RetinaNet.
В следующей таблице карта FCOS сравнивается с другими современными моделями обнаружения объектов.

Вы можете видеть, что FCOS превосходит другие современные модели.
Вывод модели FCOS с использованием PyTorch
Модель FCOS доступна в torchvision. Давайте воспользуемся предварительно обученной моделью для вывода изображений и видео.
import torch
import numpy as np
import cv2
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import glob
import os
import time
import requests
import zipfileУтилиты
Давайте напишем различные функции utils, которые необходимы для вывода и визуализации.
Создайте каталог для сохранения результатов вывода.
# Create result directory.
result_dir = 'results'
os.makedirs(result_dir, exist_ok=True)Давайте использовать графический процессор (Cuda), если он доступен.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print('Using {}.'.format(device))Using cuda.Предварительно обученная модель обучается на наборе данных COCO. Модель предсказывает индекс класса. Чтобы сопоставить его с именем класса, давайте определим список имен классов COCO.
COCO_CLASSES = [
'__background__', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A', 'stop sign',
'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack', 'umbrella', 'N/A', 'N/A',
'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket',
'bottle', 'N/A', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl',
'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table',
'N/A', 'N/A', 'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'N/A', 'book',
'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush'
]После вывода модели нам нужно построить прогнозируемую ограничивающую рамку. Предлагается использовать разные цвета для разных классов.
# Create different colors for each class.
np.random.seed(42)
COLORS = np.random.uniform(0, 255, size=(len(COCO_CLASSES), 3))Вот функция, которая загружает вес модели FCOS (fcos_resnet50_fpn) с помощью torchvision, загружает его и возвращает в режиме оценки.
# Function to load the model.
def get_model(device):
# Load the model.
model = torchvision.models.detection.fcos_resnet50_fpn(
weights='DEFAULT'
)
# Load the model onto the computation device.
model = model.eval().to(device)
return modelПеред выводом входные изображения должны иметь некоторое стандартное преобразование. Мы используем самые простые для преобразования в тензор.
# Define the torchvision image transforms.
transform = transforms.Compose([
transforms.ToTensor()
])Вот функция для визуализации четырех изображений в сетке 2 x 2.
# Plot and visualize images in a 2x2 grid.
def visualize(result_dir):
"""
Function accepts a list of images and plots
them in a 2x2 grid.
"""
plt.figure(figsize=(20, 18))
image_names = glob.glob(os.path.join(result_dir, '*.jpg'))
for i, image_name in enumerate(image_names):
image = plt.imread(image_name)
plt.subplot(2, 2, i+1)
plt.imshow(image)
plt.axis('off')
plt.tight_layout()
plt.show()Загрузка данных
Следующие функции предназначены для загрузки и распаковки данных.
def download_file(url, save_name):
url = url
if not os.path.exists(save_name):
file = requests.get(url)
open(save_name, 'wb').write(file.content)
download_file(
'https://www.dropbox.com/s/ukc7wocsn7xrm2r/data.zip?dl=1',
'data.zip'
)# Unzip the data file
def unzip(zip_file=None):
try:
with zipfile.ZipFile(zip_file) as z:
z.extractall("./")
print("Extracted all")
except:
print("Invalid file")
unzip('data.zip')Extracted allФункция прогнозирования
Давайте напишем функцию для вывода. Он принимает изображения, модель, какое устройство использовать (GPU или CPU) и пороговое значение ограничивающей рамки. И он возвращает координаты ограничивающих прямоугольников, имена классов и индекс класса.
def predict(image, model, device, detection_threshold):
"""
Predict the output of an image after forward pass through
the model and return the bounding boxes, class names, and
class labels.
"""
# Transform the image to tensor.
image = transform(image).to(device)
# Add a batch dimension.
image = image.unsqueeze(0)
# Get the predictions on the image.
with torch.no_grad():
outputs = model(image)
# Get score for all the predicted objects.
pred_scores = outputs[0]['scores'].detach().cpu().numpy()
# Get all the predicted bounding boxes.
pred_bboxes = outputs[0]['boxes'].detach().cpu().numpy()
# Get boxes above the threshold score.
boxes = pred_bboxes[pred_scores >= detection_threshold].astype(np.int32)
labels = outputs[0]['labels'][pred_scores >= detection_threshold]
# Get all the predicited class names.
pred_classes = [COCO_CLASSES[i] for i in labels.cpu().numpy()]
return boxes, pred_classes, labelsФункции аннотации
Вот функция, которая принимает ограничивающие рамки, их имя класса, индекс класса и выведенное изображение и возвращает аннотированное изображение.
def draw_boxes(boxes, classes, labels, image):
"""
Draws the bounding box around a detected object.
"""
lw = max(round(sum(image.shape) / 2 * 0.003), 2) # Line width.
tf = max(lw - 1, 1) # Font thickness.
for i, box in enumerate(boxes):
p1, p2 = (int(box[0]), int(box[1])), (int(box[2]), int(box[3]))
color = COLORS[labels[i]]
class_name = classes[i]
cv2.rectangle(
image,
p1,
p2,
color[::-1],
thickness=lw,
lineType=cv2.LINE_AA
)
# For filled rectangle.
w, h = cv2.getTextSize(
class_name,
0,
fontScale=lw / 3,
thickness=tf
)[0] # Text width, height
outside = p1[1] - h >= 3
p2 = p1[0] + w, p1[1] - h - 3 if outside else p1[1] + h + 3
cv2.rectangle(
image,
p1,
p2,
color=color[::-1],
thickness=-1,
lineType=cv2.LINE_AA
)
cv2.putText(
image,
class_name,
(p1[0], p1[1] - 5 if outside else p1[1] + h + 2),
cv2.FONT_HERSHEY_SIMPLEX,
fontScale=lw / 3.8,
color=(255, 255, 255),
thickness=tf,
lineType=cv2.LINE_AA
)
return imageВывод на изображениях
Теперь, когда у нас есть необходимые утилиты,
давайте сделаем выводы.
Получите модель.
model = get_model(device)Downloading: "https://download.pytorch.org/models/fcos_resnet50_fpn_coco-99b0c9b7.pth" to /root/.cache/torch/hub/checkpoints/fcos_resnet50_fpn_coco-99b0c9b7.pth
100%
124M/124M [00:08<00:00, 19.0MB/s]Сделайте выводы и нанесите ограничивающие рамки и их название класса на изображение.
# Get all the image paths.
image_paths = glob.glob(os.path.join('data', '*.jpg'))
# Run inference on all images.
for image_path in image_paths:
# Read the image.
image = cv2.imread(image_path)
# Create a BGR copy of the image for annotation.
image_bgr = cv2.cvtColor(np.array(image), cv2.COLOR_RGB2BGR)
# Detect outputs.
boxes, classes, labels = predict(
image,
model,
device,
detection_threshold=0.5
)
# Draw bounding boxes.
image = draw_boxes(boxes, classes, labels, image_bgr)
save_name = image_path.split(os.path.sep)[-1]
cv2.imwrite(os.path.join(result_dir, save_name), image[:, :, ::-1])Наконец, визуализируйте результаты.
# Visualize
visualize(result_dir)
Вывод на видео
Давайте сделаем выводы из модели на видео.
Он загрузит видео, сделает выводы по каждому кадру, добавит обнаружение и сохранит его обратно в видео.
# Get all the video paths.
video_paths = glob.glob(os.path.join('data', '*.mp4'))for video_path in video_paths:
print(f"Running inference on video: {video_path}")
cap = cv2.VideoCapture(video_path)
if (cap.isOpened() == False):
print('Error while trying to read video. Please check path again')
# Get the frame width and height.
frame_width = int(cap.get(3))
frame_height = int(cap.get(4))
save_name = video_path.split(os.path.sep)[-1]
# Define codec and create VideoWriter object .
out = cv2.VideoWriter(os.path.join(result_dir, save_name),
cv2.VideoWriter_fourcc(*'mp4v'),
30,
(frame_width, frame_height))
frame_count = 0 # To count total frames.
total_fps = 0 # To get the final frames per second.
# Read until end of video.
while(cap.isOpened):
# Capture each frame of the video.
ret, frame = cap.read()
if ret:
frame_copy = frame.copy()
frame_copy = cv2.cvtColor(frame_copy, cv2.COLOR_BGR2RGB)
# Get the start time.
start_time = time.time()
# Get predictions for the current frame.
boxes, classes, labels = predict(
frame,
model,
device,
detection_threshold=0.5
)
# Draw boxes and show current frame on screen.
image = draw_boxes(boxes, classes, labels, frame)
# Get the end time.
end_time = time.time()
# Get the fps.
fps = 1 / (end_time - start_time)
# Add fps to total fps.
total_fps += fps
# Increment frame count.
frame_count += 1
if frame_count % 100 == 0:
print(f"Frame: {frame_count} :: FPS: {fps:.1f}")
# Write the FPS on the current frame.
cv2.putText(image, f"{fps:.3f} FPS", (15, 30), cv2.FONT_HERSHEY_SIMPLEX,
1, (0, 255, 0), 2)
# Convert from BGR to RGB color format.
# cv2.imshow('image', image)
out.write(image)
# Press `q` to exit.
# if cv2.waitKey(1) & 0xFF == ord('q'):
# break
else:
break
# Release VideoCapture().
cap.release()
# Close all frames and video windows.
cv2.destroyAllWindows()
# Calculate and print the average FPS.
avg_fps = total_fps / frame_count
print(f"Average FPS: {avg_fps:.3f}\n\n")Running inference on video: data/soccer.mp4
Frame: 100 :: FPS: 8.8
Frame: 200 :: FPS: 8.4
Frame: 300 :: FPS: 8.8
Average FPS: 8.929
Running inference on video: data/horses_video.mp4
Frame: 100 :: FPS: 8.8
Frame: 200 :: FPS: 9.3
Average FPS: 8.748
Running inference on video: data/traffic_video.mp4
Frame: 100 :: FPS: 7.6
Frame: 200 :: FPS: 7.3
Frame: 300 :: FPS: 7.3
Frame: 400 :: FPS: 7.2
Frame: 500 :: FPS: 7.4
Frame: 600 :: FPS: 7.4
Frame: 700 :: FPS: 7.4
Frame: 800 :: FPS: 7.5
Frame: 900 :: FPS: 7.5
Frame: 1000 :: FPS: 7.3
Frame: 1100 :: FPS: 7.3
Frame: 1200 :: FPS: 7.4
Average FPS: 7.433
Running inference on video: data/cowboy.mp4
Frame: 100 :: FPS: 7.3
Frame: 200 :: FPS: 7.3
Frame: 300 :: FPS: 7.5
Frame: 400 :: FPS: 7.2
Frame: 500 :: FPS: 7.3
Frame: 600 :: FPS: 7.4
Frame: 700 :: FPS: 7.5
Average FPS: 7.393
Примеры видеовыходов
Резюме
Давайте обобщим все моменты, которые мы изучили о FCOS до сих пор
FCOS мотивируется полностью сверточными сетями FCN.
Он использует архитектуру на основе FPN, которая обеспечивает высокий BPR, наилучший отзыв и лучший прогнозируемый отзыв.
Мы также видели, как кодируется основная истина и декодируются предсказания модели в FCOS. Его метод кодирования помогает получать больше объектных (положительных) выборок во время обучения, что приводит к стабильному обучению.
FCOS использует три функции потери: потеря фокуса, потеря BCE и потеря IoU.
Мы видели, как его производительность сравнивается с другими моделями.
Мы также увидели, как предварительно обученные модели можно использовать для вывода изображений и видео.
Код на GitHub
