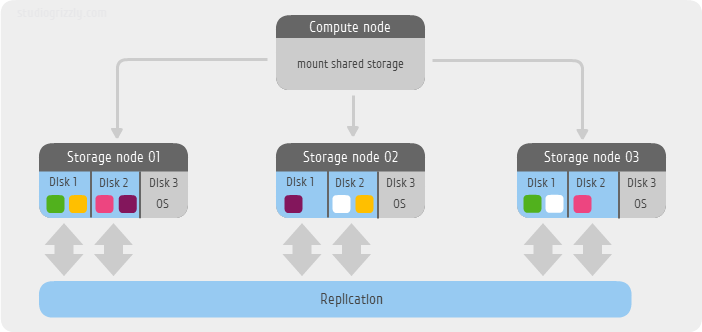
Нам понадобится всего лишь несколько минут для того что бы поднять распределенную файловую систему Ceph FS
User


 В настоящей заметке я расскажу о том, как можно построить систему оптического распознавания структурной информации, опираясь на алгоритмы, применяющиеся в обработке изображений и их реализации в рамках библиотеки OpenCV. За описанием системы стоит активно развивающийся open source проект Imago OCR, который может быть непосредственно полезен в распознавании химических структур, однако в заметке я не буду говорить о химии, а затрону более общие вопросы, решение которых поможет в распознавании структурированной информации различного рода, например таблицы или графики.
В настоящей заметке я расскажу о том, как можно построить систему оптического распознавания структурной информации, опираясь на алгоритмы, применяющиеся в обработке изображений и их реализации в рамках библиотеки OpenCV. За описанием системы стоит активно развивающийся open source проект Imago OCR, который может быть непосредственно полезен в распознавании химических структур, однако в заметке я не буду говорить о химии, а затрону более общие вопросы, решение которых поможет в распознавании структурированной информации различного рода, например таблицы или графики.
 От переводчика:
От переводчика:ffmpeg -i video.avi
ffmpeg -f image2 -i image%d.jpg video.mpg
ffmpeg -r 12 -y -i "image_%010d.png" output.mpg


После составления карты запутанных социальных сетей Николас Кристакис и его коллега Джеймс Фаулер исследовали возможности использования этой информации во благо. И сейчас Николас Кристакис обнародует свое последнее открытие: социальные сети можно использовать как самый быстрый метод для обнаружения распространения любых эпидемий: от новаторских идей до социально опасного поведения или вирусов.

 Краткое содержание прошлых серий:
Краткое содержание прошлых серий: Студенческие лаборатории ABBYY ABBYY Labs – what's new? ABBYY Labs: Проект «FromWord» — играем словами на Android ABBYY Labs. Проект «Q&A»: начало
Студенческие лаборатории ABBYY ABBYY Labs – what's new? ABBYY Labs: Проект «FromWord» — играем словами на Android ABBYY Labs. Проект «Q&A»: начало
 Это продолжение поста про оффлайн алгоритмы упаковки.
Это продолжение поста про оффлайн алгоритмы упаковки.