Последние пять лет Рекурсивный Кактус трудился фулстек-разработчиком в топовой технологической компании, но сейчас решил сменить работу.
За последние полгода Рекурсивный Кактус (так он представился при регистрации на нашем сайте) готовился к будущим собеседованиям, выделяя каждую неделю минимум 20-30 часов на упражнения LeetCode, учебники по алгоритмам и, конечно, практику интервью на нашей платформе для оценки своего прогресса.
За последние полгода Рекурсивный Кактус (так он представился при регистрации на нашем сайте) готовился к будущим собеседованиям, выделяя каждую неделю минимум 20-30 часов на упражнения LeetCode, учебники по алгоритмам и, конечно, практику интервью на нашей платформе для оценки своего прогресса.
Типичный рабочий день Рекурсивного Кактуса:
| Время | Занятие |
| 6:30 – 7:00 | Подъём |
| 7:00 – 7:30 | Медитация |
| 7:30 – 9:30 | Решение задач по алгоритмам |
| 9:30 – 10:00 | Путь на работу |
| 10:00 – 18:30 | Работа |
| 18:30 – 19:00 | Путь с работы |
| 19:00 – 19:30 | Общение с женой |
| 19:30 – 20:00 | Медитация |
| 20:00 – 22:00 | Решение задач по алгоритмам |
 Предлагаемая иерархия инструментов (здесь и далее изображения из оригинальной статьи)
Предлагаемая иерархия инструментов (здесь и далее изображения из оригинальной статьи)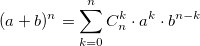 также использует биномиальные коэффициенты. Для их расчета можно использовать формулу, выражающую биномиальный коэффициент через факториалы:
также использует биномиальные коэффициенты. Для их расчета можно использовать формулу, выражающую биномиальный коэффициент через факториалы: 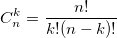 или использовать рекуррентную формулу:
или использовать рекуррентную формулу: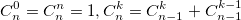 Из бинома Ньютона и рекуррентной формулы ясно, что биномиальные коэффициенты — целые числа. На данном примере хотелось показать, что даже при решении несложной задачи можно наступить на грабли.
Из бинома Ньютона и рекуррентной формулы ясно, что биномиальные коэффициенты — целые числа. На данном примере хотелось показать, что даже при решении несложной задачи можно наступить на грабли.