Сегодня мир штурмом захватывает ИИ, основанный на глубоком обучении и нейронных сетях. Однако многие алгоритмы, управляющие поиском в вебе и построением автомобильных маршрутов, гораздо старше, они уходят корнями в так называемый «старый добрый ИИ», также известный как «символический» искусственный интеллект, являвшийся основным видом ИИ с 1950-х до конца 1990-х. Затмевание символического ИИ глубинным обучением иллюстрируется двумя важнейшими вехами в истории искусственного интеллекта, каждая из которых связана с победой ИИ-системы над лучшим игроком-человеком.

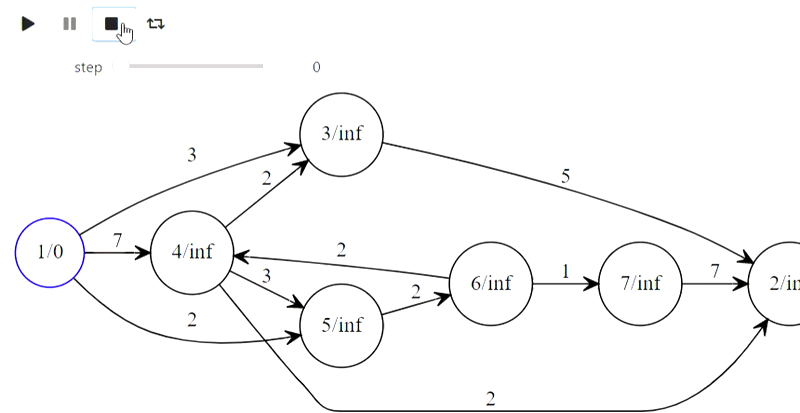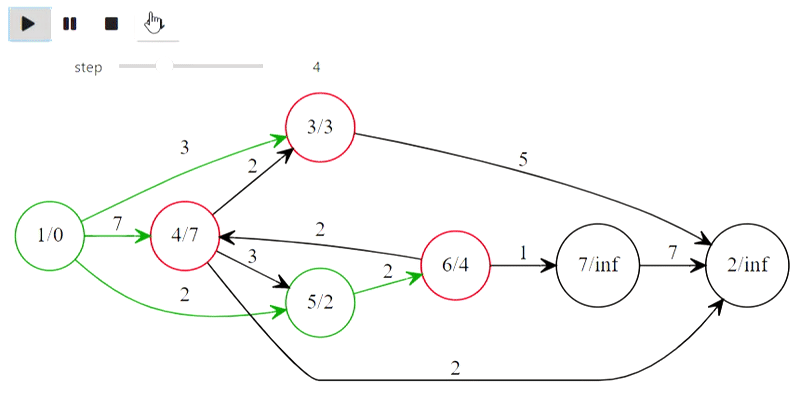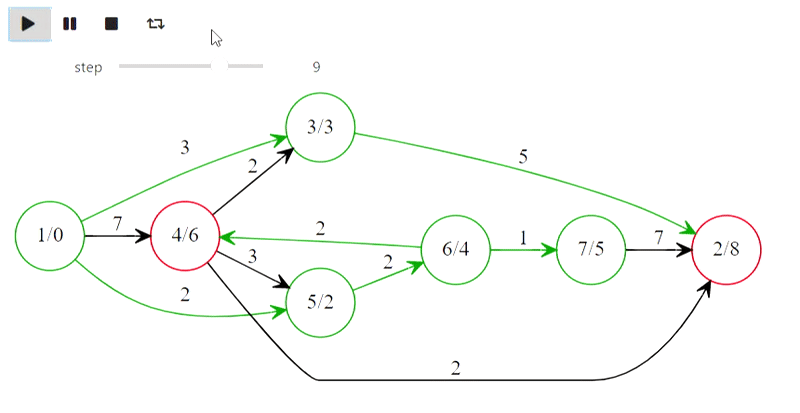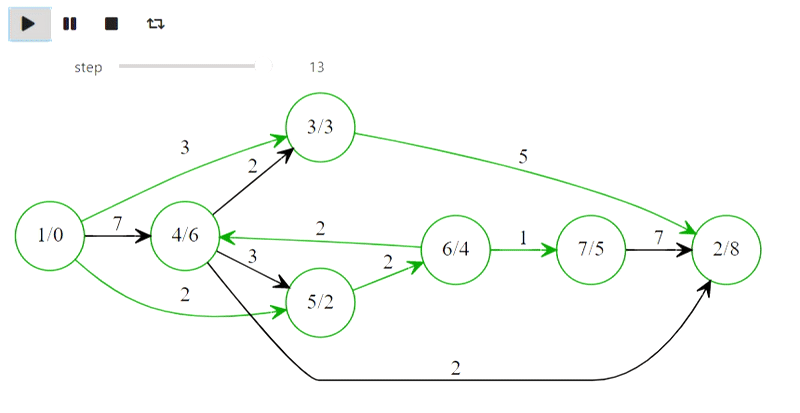
Чемпион мира Гарри Каспаров победил компьютер IBM Deep Blue в 1996 году, но потерпел поражение в 1997 году, проиграв со счётом 4:2.
Чемпион мира Гарри Каспаров победил компьютер IBM Deep Blue в 1996 году, но потерпел поражение в 1997 году, проиграв со счётом 4:2.