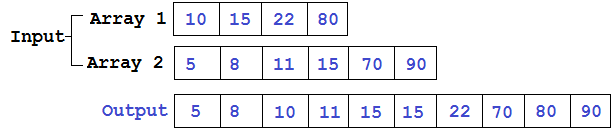
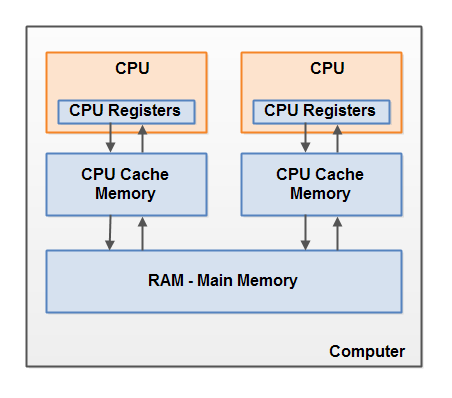
Развитие вычислительной техники движется по различным направлениям, не ограничиваясь явлениями классической физики, электроники, оптики и теперь уже квантовой механики.
Ознакомление с проблемой квантовой криптологии и смежными, близкими к ней (не только по публикациям), показало, что имеют место определенные недостатки и пробелы в ее описании и представлении. Описывая конкретику того или иного физического явления, объекта, автор игнорирует его окружение даже ближайшее, оказывающее на объект непосредственное воздействие (часто возмущающее влияние). Это не упрек авторам, их право излагать так как они излагают. Это скорее мой мотив включиться в общий поток сознания. Материальная вещественная сторона квантовых явлений так или иначе проявляет себя и неучет ее, может сказаться существенным негативом. Что имеется ввиду? Материальная реализация квантовых компьютеров (КК), регистров, отдельных кубитов — всего того из чего КК сделаны. Обмен пользователей полученными результатами через сети связи и, наконец, защита, целостность и доступность таких результатов от нарушителя — тоже проблемы.