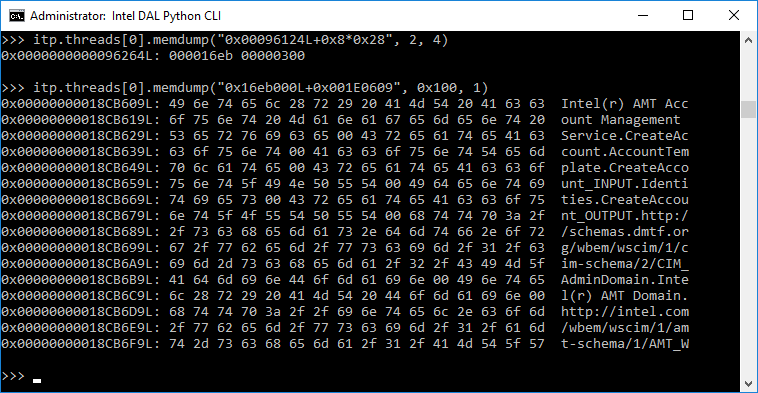
Diablo 1 — это классический roguelike 1996 года в жанре hack and slash. Это была одна из первых успешных попыток познакомить широкие массы с roguelike, которые до этого имели нишевую графику в виде ASCII-арта. Игра породила несколько сиквелов и множество имитаций. Она известна своей тёмной, мрачной атмосферой, сгущающейся по мере спуска игрока в подземелья, располагающиеся под городом Тристрам. Это была одна из первых для меня игр с процедурной генерацией карт, и возможность генерации столь правдоподобных уровней просто потрясла меня.
Недавно я узнал, что благодаря обнаружению различных файлов с символами отладки несколько фанатов игры взяли на себя задачу по реверс-инжинирингу исходного кода, чтобы подчистить его и разобраться, как же выглядел код, написанный разработчиками. Так начался мой недельный экскурс в изучение того, как ведущий разработчик Дэвид Бревик создавал эти уровни. Возможно, из-за этого магия игры для меня частично разрушилась, но я научился многим техникам, которые будут полезны для разработчиков похожих игр, поэтому в этой статье я ими поделюсь.
Благодарю Дэвида Бревика и команду Blizard North за создание такой потрясающей игры, а также galaxyhaxz и команду Devilution за их удивительную работу по восстановлению читаемого исходного кода проекта.



 В википедии написано, что ZooKeeper — распределенный сервис конфигурирования и синхронизации, не знаю как вам, но мне данное определение мало что раскрывает. Оглядываясь на свой опыт, могу дать альтернативное определение ZooKeeper, это распределенное key/value хранилище со следующими свойствами:
В википедии написано, что ZooKeeper — распределенный сервис конфигурирования и синхронизации, не знаю как вам, но мне данное определение мало что раскрывает. Оглядываясь на свой опыт, могу дать альтернативное определение ZooKeeper, это распределенное key/value хранилище со следующими свойствами: