В прошлый раз мы подробно рассмотрели многообразие линейных моделей. Теперь перейдем от теории к практике и построим самую простую, но все же полезную модель, которую вы легко сможете адаптировать к своим задачам. Модель будет проиллюстрирована кодом на R и Python, причем сразу в трех ароматах: scikit-learn, statsmodels и Patsy.

Денис @DirectX
Пользователь
Чему нас не научил профессор Ng
6 min
 Как видно по дискуссиям на хабре, несколько десятков хабровчан прослушали курс ml-class.org Стэнфордского университета, который провел обаятельнейший профессор Andrew Ng. Я тоже с удовольствием прослушал этот курс. К сожалению, из лекций выпала очень интересная тема, заявленная в плане: комбинирование обучения с учителем и обучения без учителя. Как оказалось, профессор Ng опубликовал отличный курс по этой теме — Unsupervised Feature Learning and Deep Learning (спонтанное выделение признаков и глубокое обучение). Предлагаю краткий конспект этого курса, без строгого изложения и обилия формул. В оригинале все это есть.
Как видно по дискуссиям на хабре, несколько десятков хабровчан прослушали курс ml-class.org Стэнфордского университета, который провел обаятельнейший профессор Andrew Ng. Я тоже с удовольствием прослушал этот курс. К сожалению, из лекций выпала очень интересная тема, заявленная в плане: комбинирование обучения с учителем и обучения без учителя. Как оказалось, профессор Ng опубликовал отличный курс по этой теме — Unsupervised Feature Learning and Deep Learning (спонтанное выделение признаков и глубокое обучение). Предлагаю краткий конспект этого курса, без строгого изложения и обилия формул. В оригинале все это есть.Android runtime permissions. Почему, зачем и как
12 min
Часто при установке приложения на Android нам приходилось видеть, что оно запрашивает какое-то немыслимое количество разрешений. Например:

Хорошо, если вы устанавливаете приложение от какого-то известного разработчика, которому можете доверять. Но весьма подозрительно, если вы устанавливаете новый музыкальный плеер, а ему для работы требуется, например, получать ваше местоположение. Или, тем более, фонарик, требующий доступ к смс и звонкам.
Некоторые разработчики, чтобы уменьшить недоверие, добавляют в описание приложения на Google Play информацию о том, зачем нужно то или иное разрешение.
К шестой версии Android ситуация поменялась. Теперь разрешения нужно запрашивать в процессе работы. О том, как этой новой возможностью пользоваться и ее некоторых подводных камнях будет рассказано далее.
Хорошо, если вы устанавливаете приложение от какого-то известного разработчика, которому можете доверять. Но весьма подозрительно, если вы устанавливаете новый музыкальный плеер, а ему для работы требуется, например, получать ваше местоположение. Или, тем более, фонарик, требующий доступ к смс и звонкам.
Некоторые разработчики, чтобы уменьшить недоверие, добавляют в описание приложения на Google Play информацию о том, зачем нужно то или иное разрешение.
К шестой версии Android ситуация поменялась. Теперь разрешения нужно запрашивать в процессе работы. О том, как этой новой возможностью пользоваться и ее некоторых подводных камнях будет рассказано далее.
Порог вхождения в Angular 2 — теория и практика
16 min
Tutorial
Добрый день, дорогие хабра: жители, читатели, писатели, негативно-комментаторы.
В качестве вводной части и чтобы снять некоторые вопросы немного расскажу о себе. Меня зовут Тамара. Оужас, я девушка! Кого это пугает — закрывайте статью и не читайте.
Для остальных: у меня за плечам незаконченный лет 10 назад МИРЭА, факультет кибернетики. Но все эти 10 лет практики сложились таким образом, что по большей части я занималась рекламой и в перерывах случалось работать в различных стартапах, связанных с интернетом и не только.

В общем, если коротко, то чукча не программист, чукча просто душой и сердцем уважает тех, кто из непонятных строчек кода делает офигенные вещи, которые хорошо работают.
В качестве вводной части и чтобы снять некоторые вопросы немного расскажу о себе. Меня зовут Тамара. Оужас, я девушка! Кого это пугает — закрывайте статью и не читайте.
Для остальных: у меня за плечам незаконченный лет 10 назад МИРЭА, факультет кибернетики. Но все эти 10 лет практики сложились таким образом, что по большей части я занималась рекламой и в перерывах случалось работать в различных стартапах, связанных с интернетом и не только.
В общем, если коротко, то чукча не программист, чукча просто душой и сердцем уважает тех, кто из непонятных строчек кода делает офигенные вещи, которые хорошо работают.
Разбираемся с войной нейронных сетей (GAN)
7 min
Generative adversarial networks (GAN) пользуются все большей популярностью. Многие говорят о них, кто-то даже уже использует… но, как выясняется, пока мало кто (даже из тех кто пользуется) понимает и может объяснить. ;-)
Давайте разберем на самом простом примере, как же они работают, чему учатся и что на самом деле порождают.
Давайте разберем на самом простом примере, как же они работают, чему учатся и что на самом деле порождают.
Как покрасить вкладку Chrome
1 min
Tutorial
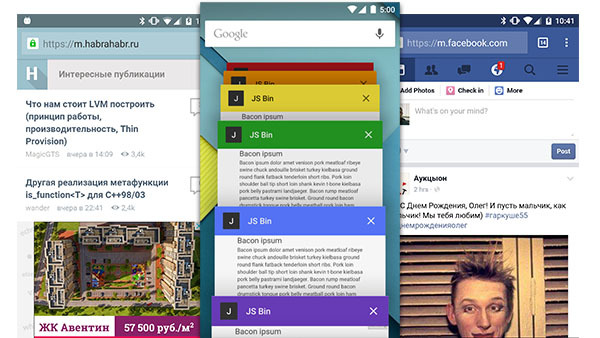
Если вы заходили с мобильного хрома в фейсбук, то наверняка видели, что интерфейс браузера красится в фирменный синий цвет соцсети. Но зачем и как?
Аутентифицируем запросы в микросервисном приложении с помощью nginx и JWT
4 min
Recovery Mode
Стараясь оставаться в тренде и следуя веяниям моды веб разработки, последнее веб приложение я решил реализовать как набор микросервисов на ruby плюс “толстый” клиент на ember. Одна из первых проблем, вставших перед мной была связана с аутентификацией запросов. Если в классическом, монолитном, приложении все просто, используем куки, сессии, подключаем какой-нибудь devise, то тут все как в первый раз.
За базу я выбрал JWT — Json Web Token. Это открытый стандарт RFC 7519 для представления заявок (claims) между двумя участниками. Он представляет из себя структуру вида: Header.Payload.Signature, где заголовок и payload это запакованые в base64 json хэши. Здесь стоит обратить внимание на payload. Он может содержать в себе все что угодно, в принципе это может быть и просто client_id и какая-то другая информация о пользователе, но это не очень хорошая идея, лучше передавать там только ключ идентификатор, а сами данные хранить где-то в другом месте. В качестве хранилища данных можно использовать что угодно, но мне показалось, что redis будет оптимальным, тем более что он пригодится и для других задач. Еще один важный момент — каким ключем мы будем подписывать наш токен. Самый простой вариант использовать один shared key, но это явно не самый безопасный вариант. Коль скоро мы храним данные сессии в redis, ничто не мешает нам генерировать уникальный ключ для каждого токена и хранить его там же.
Понятно, что генерировать токены будет сервис отвечающий за авторизацию, но кто и как будет их проверять? В принципе можно проверку затолкать в каждый микросервис, но это противоречит идеи их максимального разделения. Каждый сервис должен будет содержать логику обработки и проверки токенов да еще и иметь доступ к redis. Нет, наш цель получить архитектуру в которой все запросы приходящие в конечные сервисы уже авторизованы и несут в себе данные о пользователе (например в каком-нибудь специальном заголовке).
Архитектура
За базу я выбрал JWT — Json Web Token. Это открытый стандарт RFC 7519 для представления заявок (claims) между двумя участниками. Он представляет из себя структуру вида: Header.Payload.Signature, где заголовок и payload это запакованые в base64 json хэши. Здесь стоит обратить внимание на payload. Он может содержать в себе все что угодно, в принципе это может быть и просто client_id и какая-то другая информация о пользователе, но это не очень хорошая идея, лучше передавать там только ключ идентификатор, а сами данные хранить где-то в другом месте. В качестве хранилища данных можно использовать что угодно, но мне показалось, что redis будет оптимальным, тем более что он пригодится и для других задач. Еще один важный момент — каким ключем мы будем подписывать наш токен. Самый простой вариант использовать один shared key, но это явно не самый безопасный вариант. Коль скоро мы храним данные сессии в redis, ничто не мешает нам генерировать уникальный ключ для каждого токена и хранить его там же.
Понятно, что генерировать токены будет сервис отвечающий за авторизацию, но кто и как будет их проверять? В принципе можно проверку затолкать в каждый микросервис, но это противоречит идеи их максимального разделения. Каждый сервис должен будет содержать логику обработки и проверки токенов да еще и иметь доступ к redis. Нет, наш цель получить архитектуру в которой все запросы приходящие в конечные сервисы уже авторизованы и несут в себе данные о пользователе (например в каком-нибудь специальном заголовке).

Vision-based SLAM: монокулярный SLAM
8 min
Tutorial
Продолжаем серию статей-уроков по визуальному SLAM уроком о работе с его монокулярными вариантами. Мы уже рассказывали об установке и настройке окружения, а также проводили общий обзор в статье о навигации квадрокоптера. Сегодня попробуем разобраться, как работают разные алгоритмы SLAM, использующие единственную камеру, рассмотрим их различия для пользователя и дадим рекомендации по применению.

Vision-based SLAM: tutorial
7 min
Tutorial
После опубликования статьи об опыте использования монокулярного SLAM мы получили несколько комментариев с вопросами о подробной настройке. Мы решили ответить песней серией статей-уроков о SLAM. Сегодня предлагаем ознакомиться с первой из них, в которой поставим все необходимые пакеты и подготовим окружение для дальнейшей работы.

О пользе технологий больших данных в повседневной жизни
4 min
Среди многих исследователей и разработчиков бытует мнение, что инструменты обработки больших данных в области машинного обучения часто избыточны – всегда можно сделать сэмпл, загнать в память и использовать любимые R, Python и Matlab. Но на практике встречаются задачи, когда даже относительно небольшой объем данных, размером в пару гигабайт, обработать в таком стиле затруднительно – и тут-то и могут помочь те самые технологии «больших данных».
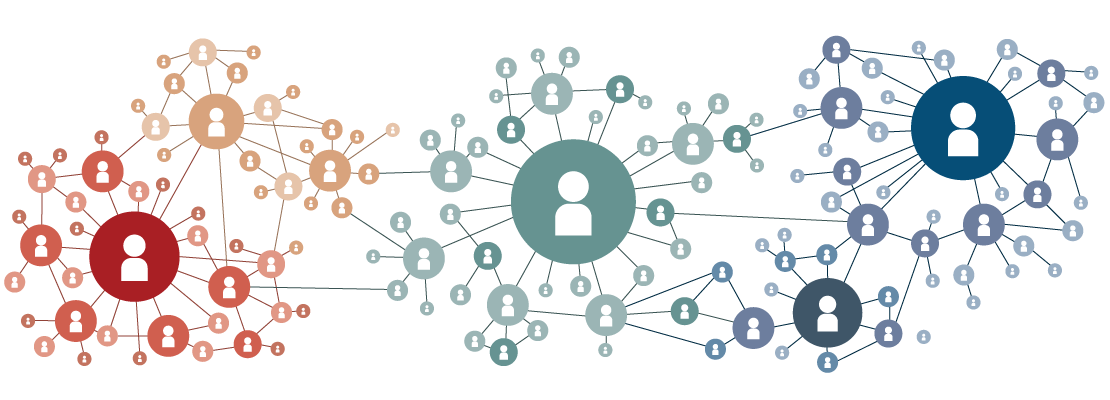
Хорошим наглядным примером такой задачи является задача нашего конкурса SNA Hakathon 2016: дан социальный граф одного миллиона пользователей и их демография. Задача — найти скрытые связи в этом графе. Размер предоставленного графа всего два гигабайта в GZip и, казалось бы, применение технологий больших данных здесь не оправданно, но это только на первый взгляд.
Одной из самых важных «фич» в задаче поиска скрытых связей в социальном графе является количество общих друзей. И в расчетном плане это очень тяжелая «фича» — количество узлов, между которыми существуют пути длины 2, на несколько порядков больше, чем количество прямых связей в графе. В результате при расчете граф «взрывается» и из разрежённой матрицы на два гигабайта превращается в плотную терабайтную матрицу.
Казалось бы, для решение этой задачи впору поднимать небольшой кластер, но спешить не стоит: взяв на вооружение принципы обработки больших данных и соответствующие технологии, задачу можно решить и на обычном ноутбуке. Из принципов мы возьмем «разделяй и властвуй» и «руби хвосты сразу», а в качестве инструмента — Apache Spark.
Материал по работе с Apache Lucene и созданию простейшего нечёткого поиска
4 min
Tutorial
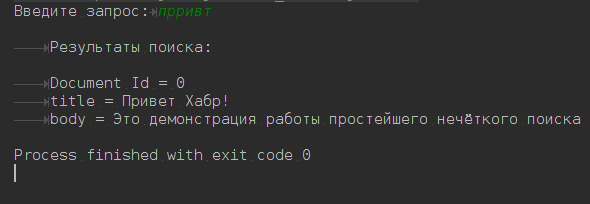 Пост расcчитан на начинающих, на людей незнакомых с технологией Apache Lucene. В нем нет материала о том, как устроен Apache Lucene внутри, какие алгоритмы, структуры данных и методы использовались для создания фреймворка. Пост является обучающим материалом-тизером, написанным для того, чтобы показать, как организовать простейший нечёткий поиск по тексту.
Пост расcчитан на начинающих, на людей незнакомых с технологией Apache Lucene. В нем нет материала о том, как устроен Apache Lucene внутри, какие алгоритмы, структуры данных и методы использовались для создания фреймворка. Пост является обучающим материалом-тизером, написанным для того, чтобы показать, как организовать простейший нечёткий поиск по тексту. В качестве материала для обучения предоставлен код на github, сам пост в качестве документации и немного данных для тестирования поисковых запросов.
Несколько неочевидных frontend-хитростей
4 min
Tutorial
Под катом вы узнаете о том, как быстро и легко оформить взаимодействие с SVG-иконками, добавить плавный скролл с помощью одного CSS-правила, анимировать появление новых элементов на странице, переносить текст на новую строку с помощью CSS и о новых способах оформления декоративной линии текста.

Построение Android приложений шаг за шагом, часть первая
8 min

В этой статье мы поговорим о проектировании архитектуры и создании мобильного приложения на основе паттерна MVP с использованием RxJava и Retrofit. Тема получилась довольно большой, поэтому подаваться будет отдельными порциями: в первой мы проектируем и создаем приложение, во второй занимаемся DI с помощью Dagger 2 и пишем тесты unit тесты, в третьей дописываем интеграционные и функциональные тесты, а также размышляем о TDD в реалиях Android разработки.
Создание онтологии в Protégé 5.0
3 min
Tutorial
 Protégé является свободным программным средством с открытым исходным кодом для редактирования онтологий и систем управления знаниями 1 . Версия 5.0 на сегодня является актуальной (о ней подробнее). Поэтому я подумала, что простой тьюториал, как небольшое введение в работу с этой программой, не будет лишним на Хабре.
Protégé является свободным программным средством с открытым исходным кодом для редактирования онтологий и систем управления знаниями 1 . Версия 5.0 на сегодня является актуальной (о ней подробнее). Поэтому я подумала, что простой тьюториал, как небольшое введение в работу с этой программой, не будет лишним на Хабре.Создание новой онтологии
Для создания онтологии открываем редактор Protégé 5.0 (загрузить можно с официального сайта или воспользоваться онлайн версией) и вводим ее название — например, NQF_FQF, и версию — /1.0.

Алгоритм извлечения информации в ABBYY Compreno. Часть 1
7 min
Привет, Хабр!
Меня зовут Илья Булгаков, я программист отдела извлечения информации в ABBYY. В серии из двух постов я расскажу вам наш главный секрет – как работает технология Извлечения Информации в ABBYY Compreno.
Ранее мой коллега Даня Скоринкин DSkorinkin успел рассказать про взгляд на систему со стороны онтоинженера, затронув следующие темы:
В этот раз мы опустимся глубже в недра технологии ABBYY Compreno, поговорим про архитектуру системы в целом, основные принципы ее работы и алгоритм извлечения информации!

Меня зовут Илья Булгаков, я программист отдела извлечения информации в ABBYY. В серии из двух постов я расскажу вам наш главный секрет – как работает технология Извлечения Информации в ABBYY Compreno.
Ранее мой коллега Даня Скоринкин DSkorinkin успел рассказать про взгляд на систему со стороны онтоинженера, затронув следующие темы:
- Деревья семантико-синтаксического разбора и создание онтологий
- Написание правил извлечения информации
В этот раз мы опустимся глубже в недра технологии ABBYY Compreno, поговорим про архитектуру системы в целом, основные принципы ее работы и алгоритм извлечения информации!
Реализация семантического новостного агрегатора с широкими поисковыми возможностями
10 min
 Цель этой статьи — поделиться опытом и идеями реализации проекта, основанного на полном преобразовании текстов в семантическое представление и организации семантического (смыслового) поиска по полученной базе знаний. Речь пойдет об основных принципах функционирования этой системы, используемых технологиях, и проблемах, возникающих при ее реализации.
Цель этой статьи — поделиться опытом и идеями реализации проекта, основанного на полном преобразовании текстов в семантическое представление и организации семантического (смыслового) поиска по полученной базе знаний. Речь пойдет об основных принципах функционирования этой системы, используемых технологиях, и проблемах, возникающих при ее реализации.Зачем это нужно?
В идеале, семантическая система «понимает» содержание обрабатываемых статей в виде системы смысловых понятий и выделяет из них главные («о чем» текст). Это дает огромные возможности по более точной кластеризации, автоматическому реферированию и семантическому поиску, когда система ищет не по словам запроса, а по смыслу, который стоит за этими словами.
Семантический поиск – это не только ответ по смыслу на набранную в поисковой строке фразу, а в целом способ взаимодействия пользователя с системой. Семантическим запросом может быть не только простое понятие или фраза, но и документ — система при этом выдает семантически связанные документы. Профиль интересов пользователя – это тоже семантический запрос и может действовать в «фоновом режиме» параллельно с другими запросами.
Математика на пальцах: методы наименьших квадратов
8 min
Tutorial
Введение

Я математик-программист. Самый большой скачок в своей карьере я совершил, когда научился говорить:«Я ничего не понимаю!» Сейчас мне не стыдно сказать светилу науки, что мне читает лекцию, что я не понимаю, о чём оно, светило, мне говорит. И это очень сложно. Да, признаться в своём неведении сложно и стыдно. Кому понравится признаваться в том, что он не знает азов чего-то-там. В силу своей профессии я должен присутствовать на большом количестве презентаций и лекций, где, признаюсь, в подавляющем большинстве случаев мне хочется спать, потому что я ничего не понимаю. А не понимаю я потому, что огромная проблема текущей ситуации в науке кроется в математике. Она предполагает, что все слушатели знакомы с абсолютно всеми областями математики (что абсурдно). Признаться в том, что вы не знаете, что такое производная (о том, что это — чуть позже) — стыдно.
Но я научился говорить, что я не знаю, что такое умножение. Да, я не знаю, что такое подалгебра над алгеброй Ли. Да, я не знаю, зачем нужны в жизни квадратные уравнения. К слову, если вы уверены, что вы знаете, то нам есть над чем поговорить! Математика — это серия фокусов. Математики стараются запутать и запугать публику; там, где нет замешательства, нет репутации, нет авторитета. Да, это престижно говорить как можно более абстрактным языком, что есть по себе полная чушь.
Angular 1.5: Компоненты
16 min

Не так давно увидел свет релиз Angular 1.5, который привносит множество интересных нововведений. Важной особенностью
данной версии является то, что это первый из череды релизов, который должен сгладить концептуальный разрыв между Angular1.x и Angular2.x. Для людей, у которых есть необходимость вести проекты на Angular сейчас, но в будущем планируется постепенная миграция на Angular2, это очень радостная новость.
В данной статье я постараюсь осветить основные нововведения:
- Компоненты!
- Односторонние биндинги!
- Мульти-слот трансклюды!
Полный список изменений доступен в репозитории ангуляра. Так же нас ждет небольшой примерчик использования перечисленных фич.
Go и Protocol Buffers, ускорение
4 min
Tutorial
Некое продолжение статьи Go и Protocol Buffers толика практики (или быстрый старт, для тех кто ещё не знаком). Процессы кодирования/декодирования в определённые форматы в Go тесно связяны с рефлексией. А как мы с Вами, дорогой читатель, знаем — рефлексия — это долго. О том какие методы борьбы существуют эта статья. Думаю что, искушённые вряд ли найдут в ней, что-либо новое.