То, что не поддаётся измерению, не поддаётся и улучшению.
— Лорд Кельвин
Чтобы ускорить игры, написанные при помощи HTML5, для начала нужно определить их узкие места. Подсчёт FPS – это неплохой метод, но чтобы увидеть полную информацию, необходимо разобраться в нюансах поведения Chrome.
Инструмент about:tracing позволяет избежать лишней работы, связанной с увеличением быстродействия, и основанной большей частью на догадках. Вы сэкономите энергию и деньги, если чётко проследите работу браузера при помощи этого инструмента.
Он показывает вам всё, что делает Chrome, причём настолько детально, что сперва это даже может ошеломить. Многие функции Chrome изначально предназначены для трассировки, поэтому прямо из коробки для оценки производительности можно использовать about:tracing.
Для этого просто напишите about:tracing в адресной строке.

Инструмент трассировки позволяет включить запись, запустить игру на несколько секунд и посмотреть данные трассировки. Пример того, как они могут выглядеть:
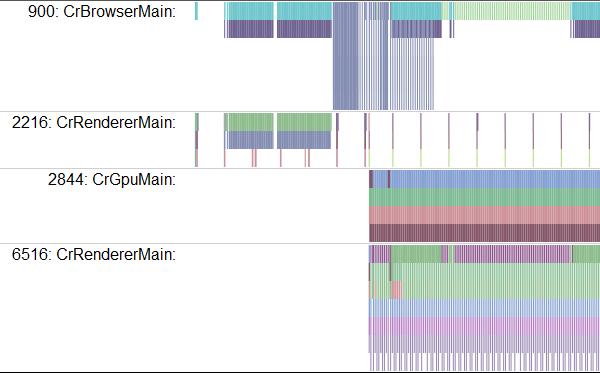
Да, сначала выглядит запутанно.