Победители первого этапа конкурса MOBI Grand Challenge применяют блокчейн к автоиндустрии и рынку транспорта новыми способами, начиная от колонн беспилотных автомобилей и заканчивая автоматизированной V2X-связью.
Блокчейн все еще имеет некоторые проблемы на своем пути, но его потенциальное влияние на автомобильную промышленность неоспоримо. Вокруг этого специфического применения блокчейна возникла целая экосистема стартапов и новых предприятий.
Mobility Open Blockchain Initiative (MOBI), некоммерческая инициатива, направленная на ускоренное внедрение стандартов, связанных с блокчейном, в автомобильной и транспортной промышленности, провела первую фазу своего проекта MOBI Grand Challenge (MGC), рассчитанного на три года и направленного на выявление инновационных способов применения блокчейна в формирующейся экосистеме подключенных к сети и автономных автомобилей.
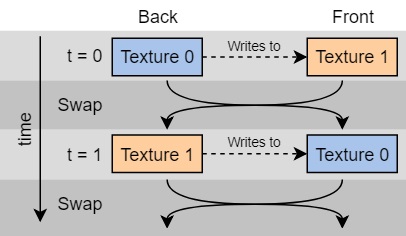
Согласно заявлению MOBI: «Целью MGC является создание жизнеспособной, децентрализованной, специальной сети связанных между собой автомобилей на распределенной бухгалтерии (distributed ledger technology) и инфраструктуры, которая может надежно обмениваться данными, координировать поведение и, в конечном счете, улучшать городскую мобильность».