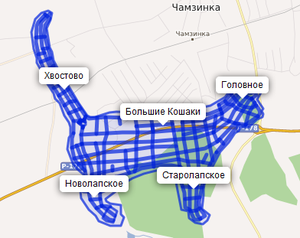
 Программисты — редкие люди. Мы можем сделать абсолютно всё, но интернет отвечает на это зияющей пустотой, где нужно делать абсолютно всё. Особенно если живёшь в непрофильных сообществах. Запросы со всех сторон, тут нужно подлатать, там плагинчик дописать, и никто, кроме тебя. Эта история — про один из таких пробелов, который я надеялся закрыть за неделю, и та неделя всё продолжается. В программе: дорожное строительство и велосипедисты, сайт для обмена картами лучше яндекса, осмеры без осма, архитектура плагинов в форумных движках и интерактивные карты прямо в хабре.
Программисты — редкие люди. Мы можем сделать абсолютно всё, но интернет отвечает на это зияющей пустотой, где нужно делать абсолютно всё. Особенно если живёшь в непрофильных сообществах. Запросы со всех сторон, тут нужно подлатать, там плагинчик дописать, и никто, кроме тебя. Эта история — про один из таких пробелов, который я надеялся закрыть за неделю, и та неделя всё продолжается. В программе: дорожное строительство и велосипедисты, сайт для обмена картами лучше яндекса, осмеры без осма, архитектура плагинов в форумных движках и интерактивные карты прямо в хабре.Карты для всех, даром
9 min
Программисты — редкие люди. Мы можем сделать абсолютно всё, но интернет отвечает на это зияющей пустотой, где нужно делать абсолютно всё. Особенно если живёшь в непрофильных сообществах. Запросы со всех сторон, тут нужно подлатать, там плагинчик дописать, и никто, кроме тебя. Эта история — про один из таких пробелов, который я надеялся закрыть за неделю, и та неделя всё продолжается. В программе: дорожное строительство и велосипедисты, сайт для обмена картами лучше яндекса, осмеры без осма, архитектура плагинов в форумных движках и интерактивные карты прямо в хабре.






![[плакат со шрифтом Imperial]](https://habrastorage.org/getpro/habr/post_images/0d2/002/5b3/0d20025b348f3bb48fcd797e6377ace8.jpg)