Весной 2006 года Кевин Систром стоял за кофемашиной в кафе Caffé del Doge в Пало-Альто, когда к стойке подошел основатель Facebook Марк Цукерберг. Годом ранее Цукерберг уже ужинал с Систромом — он предложил ему уйти с последнего курса Стэнфорда, чтобы разработать фотосервис для Facebook. Кевин тогда отказался. Оставшись в Стэнфорде, Систром разработал приложение Instagram, которое Цукерберг недавно приобрел за $1 млрд. (Сумма поражает, особенно если знать, что у стартапа нет не только выручки, но и модели ее получения. В компании Instagram, возраст которой еще не достиг двух лет, по-прежнему лишь 14 сотрудников.) В итоге Цукерберг все же захватил Кевина в ряды армии Facebook, с чем его и поздравляем.
Если в истории с Систромом Цукерберг сделал ставки и не прогадал, то с сооснователем WhatsApp Брайаном Актоном все сложилось иначе. В 2009 году его не взяли на работу в Facebook, а в 2014 компания покупает WhatsApp за $16 млрд. Как же так получается, что большие и инновационные компании отказываются от перспективных сотрудников (будем называть их гуру или «звездами»), за которых в будущем будут гоняться с утроенной скоростью, предлагая просто сумасшедшие деньги? Ориентация на метрики, а не на результат.
Если в истории с Систромом Цукерберг сделал ставки и не прогадал, то с сооснователем WhatsApp Брайаном Актоном все сложилось иначе. В 2009 году его не взяли на работу в Facebook, а в 2014 компания покупает WhatsApp за $16 млрд. Как же так получается, что большие и инновационные компании отказываются от перспективных сотрудников (будем называть их гуру или «звездами»), за которых в будущем будут гоняться с утроенной скоростью, предлагая просто сумасшедшие деньги? Ориентация на метрики, а не на результат.

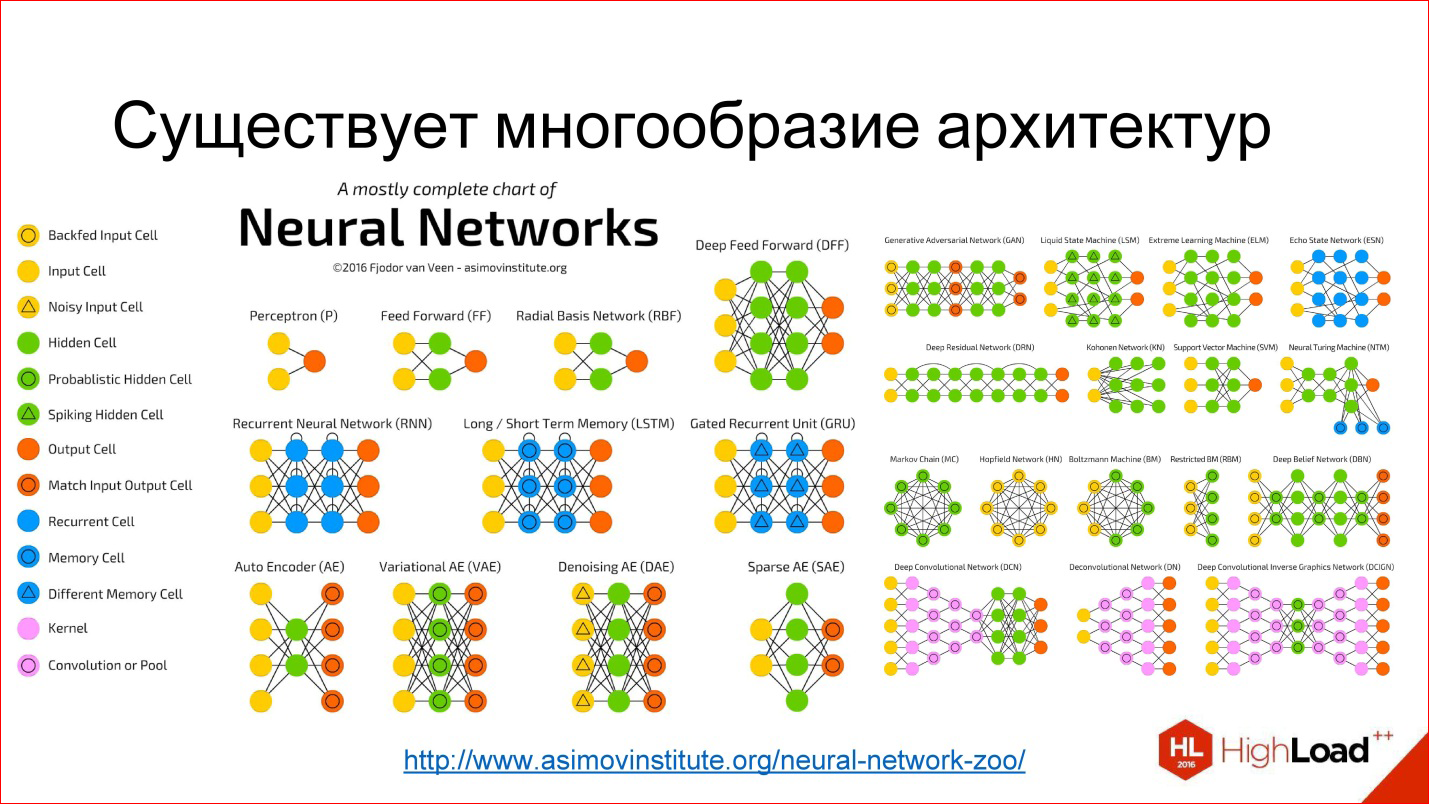
 Доводилось ли вам сталкиваться с системами искусственного интеллекта? Полагаем, ответ большинства хабравчан будет положительным. Ведь ИИ уже перестал быть «чем-то за гранью фантастики». Системы распознавания речи Siri, IBM Watson, ViaVoice, виртуальные игроки Deep Blue, AlphaGo и даже такие ранние системы, как MYCIN, разработанная в 1970-х годах в Стэнфордском университете и предназначенная для диагностирования бактерий, вызывающих тяжелые инфекции, а также для рекомендации необходимого количества антибиотиков — все это вариации на тему ИИ. Но, несмотря на то, что технологии стремительно набирают ход, современные системы все еще весьма «угловаты», и главная проблема, с которой сталкиваются исследователи, — это языковое обучение. Заставить систему говорить не сложно, но объяснить ей «физику» окружающего мира — то, что человек понимает на интуитивном уровне — пока не удавалось никому.
Доводилось ли вам сталкиваться с системами искусственного интеллекта? Полагаем, ответ большинства хабравчан будет положительным. Ведь ИИ уже перестал быть «чем-то за гранью фантастики». Системы распознавания речи Siri, IBM Watson, ViaVoice, виртуальные игроки Deep Blue, AlphaGo и даже такие ранние системы, как MYCIN, разработанная в 1970-х годах в Стэнфордском университете и предназначенная для диагностирования бактерий, вызывающих тяжелые инфекции, а также для рекомендации необходимого количества антибиотиков — все это вариации на тему ИИ. Но, несмотря на то, что технологии стремительно набирают ход, современные системы все еще весьма «угловаты», и главная проблема, с которой сталкиваются исследователи, — это языковое обучение. Заставить систему говорить не сложно, но объяснить ей «физику» окружающего мира — то, что человек понимает на интуитивном уровне — пока не удавалось никому. В этом посте я хочу подробно рассказать о моём опыте переезда на работу PHP-разработчиком в Германию — от момента, когда есть просто желание переехать, но не знаешь что и как делать, до момента, когда уже переехал, вселился в квартиру и получил вид на жительство. Кроме того, в конце поста я приведу немного полезной информации и ссылок по переезду в некоторые другие страны.
В этом посте я хочу подробно рассказать о моём опыте переезда на работу PHP-разработчиком в Германию — от момента, когда есть просто желание переехать, но не знаешь что и как делать, до момента, когда уже переехал, вселился в квартиру и получил вид на жительство. Кроме того, в конце поста я приведу немного полезной информации и ссылок по переезду в некоторые другие страны.


 Вопрос о столах поднимался несколько раз (
Вопрос о столах поднимался несколько раз (




")