Представляем вторую статью в серии, задуманной, чтобы помочь быстро разобраться в технологии глубокого обучения; мы будем двигаться от базовых принципов к нетривиальным особенностям с целью получить достойную производительность на двух наборах данных: MNIST (классификация рукописных цифр) и CIFAR-10 (классификация небольших изображений по десяти классам: самолет, автомобиль, птица, кошка, олень, собака, лягушка, лошадь, корабль и грузовик).
Представляем первую статью в серии, задуманной, чтобы помочь быстро разобраться в технологии глубокого обучения; мы будем двигаться от базовых принципов к нетривиальным особенностям с целью получить достойную производительность на двух наборах данных: MNIST (классификация рукописных цифр) и CIFAR-10 (классификация небольших изображений по десяти классам: самолет, автомобиль, птица, кошка, олень, собака, лягушка, лошадь, корабль и грузовик).
Это будет длиннопост. Я давно хотел написать этот обзор, но sim0nsays меня опередил, и я решил выждать момент, например как появятся результаты ImageNet’а. Вот момент настал, но имаджнет не преподнес никаких сюрпризов, кроме того, что на первом месте по классификации находятся китайские эфэсбэшники. Их модель в лучших традициях кэгла является ансамблем нескольких моделей (Inception, ResNet, Inception ResNet) и обгоняет победителей прошлого всего на полпроцента (кстати, публикации еще нет, и есть мизерный шанс, что там реально что-то новое). Кстати, как видите из результатов имаджнета, что-то пошло не так с добавлением слоев, о чем свидетельствует рост в ширину архитектуры итоговой модели. Может, из нейросетей уже выжали все что можно? Или NVidia слишком задрала цены на GPU и тем самым тормозит развитие ИИ? Зима близко? В общем, на эти вопросы я тут не отвечу. Зато под катом вас ждет много картинок, слоев и танцев с бубном. Подразумевается, что вы уже знакомы с алгоритмом обратного распространения ошибки и понимаете, как работают основные строительные блоки сверточных нейронных сетей: свертки и пулинг.
Александр Ханьевич — автор многих популярных книг по математике и программированию. Многие его книги и брошюры можно бесплатно скачать с сайта издательства МЦНМО: например, «Программирование: теоремы и задачи» (Шень, 2004), «Лекции по математической логике и теории алгоритмов» (Верещагин, Шень, 2012), «Классические и квантовые вычисления» (Китаев, Шень, Вялый, 1999). Под его редакцией вышел перевод первого издания классического учебника «Алгоритмы: построение и анализ» (Кормен, Лейзерсон, Ривеста, 1990), а также недавнего учебника «Алгоритмы» (Дасгупта, Пападимитриу, Вазирани, 2006).
В общем, у Александра Ханьевича огромный опыт чтения лекций как школьникам, так и студентам и аспирантам. Рассказывает он очень увлекательно и понятно. В онлайн-курсе он даст обзор различных направлений Theoretical Computer Science: криптография, инварианты циклов, вычислимость, переборные задачи, игры, коды, интерактивные доказательства и многое другое (всего в курсе восемнадцать глав!). В курсе будет много задач — как простых (закрепляющих изученный материал), так и более сложных, над которыми придётся поломать голову и тем, кто уже был знаком с теорией.
Будем рады видеть вас среди слушателей онлайн-курса! stepic.org/104
2015 год был очень богат на события, связанные с нейросетевыми технологиями и машинным обучением. Особенно заметный прогресс показали сверточные и рекуррентные сети, подходящие для решения задач в области компьютерного зрения и распознавания речи. Многие крупные компании опубликовали на Github свои разработки, Google выпустил в свет TensorFlow, Baidu — warp-ctc. Группа ученых из Microsoft Research тоже решила присоединиться к этой инициативе, выпустив Computational Network Toolkit, набор инструментов для проектирования и тренировки сетей различного типа, которые можно использовать для распознавания образов, понимания речи, анализа текстов и многого другого. Интригующим при этом является то, что эта сеть победила в конкурсе ImageNetLSVR 2015 и является самой быстрой среди существующих конкурентов.
Этот бенчмарк проект начался со статьи “Serializers in .NET v.2” на GeeksWithBlogs.net. В статье было рассмотрено довольно много имеющихся под .NET сериализаторов. Но, чтобы превратить эту статью и соответствующий код в настоящий бенчмарк, надо было сделать несколько улучшений.
Во-первых, сериализаторы надо было тестировать на нескольких типах данных. Есть универсальные сериализаторы, а есть специализированные. Специализированные очень хорошо работают только с несколькими типами данных, на других данных они работают намного хуже или совсем не работают. В чем мы в дальнейшем и убедились.
Во-вторых, сериализаторы сильно отличаются по интерфейсам. Наш бенчмарк не должен заставлять сериализатор следовать нашему выбору интерфейса. Наоборот, бенчмарк должен быть настолько гибким, чтобы каждый сериализатор мог бы использовать наиболее подходящий для него интерфейс. То есть надо передавать в бенчмарк дополнительные параметры конкретного сериализатора.
Сегодня пятница, а пятница на хабре — это отличный день для чего-то необычного. Сегодня я предлагаю вашему вниманию интервью с Дмитрием yole Жемеровым, человеком, который приложил руку и к IntelliJ IDEA, PyCharm, Kotlin и многим другим продуктам компании JetBrains.
О чем мы поговорили:
как развивается IDEA, куда она движется
в чем разница между IntelliJ и JetBrains
зачем в компании два CEO
что происходит в Kotlin'e
с какими трудностями столкнулась команда Kotlin в процессе разработке языка
Утром в службу поддержки обратился один из разработчиков корпоративного приложения. Он не мог сделать копию с базы данных MS SQL Server, и просил выяснить причину ошибки.
Первое с чего стоит начать — проверить ошибку на воспроизводимость.
Попробуем снять копию командой:
BACKUP DATABASE [SDB] TO DISK=N'\\FS1\Backup\sdb_full.bak' WITH COPY_ONLY




 Это будет длиннопост. Я давно хотел написать этот обзор, но
Это будет длиннопост. Я давно хотел написать этот обзор, но 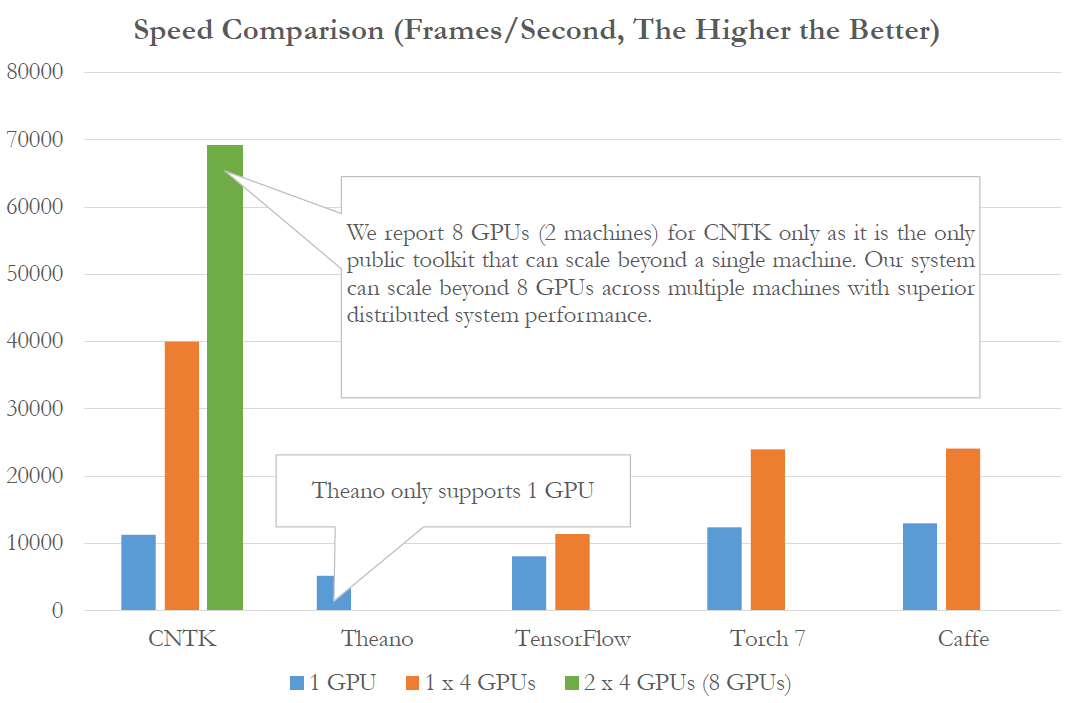
 Утром в службу поддержки обратился один из разработчиков корпоративного приложения. Он не мог сделать копию с базы данных MS SQL Server, и просил выяснить причину ошибки.
Утром в службу поддержки обратился один из разработчиков корпоративного приложения. Он не мог сделать копию с базы данных MS SQL Server, и просил выяснить причину ошибки.