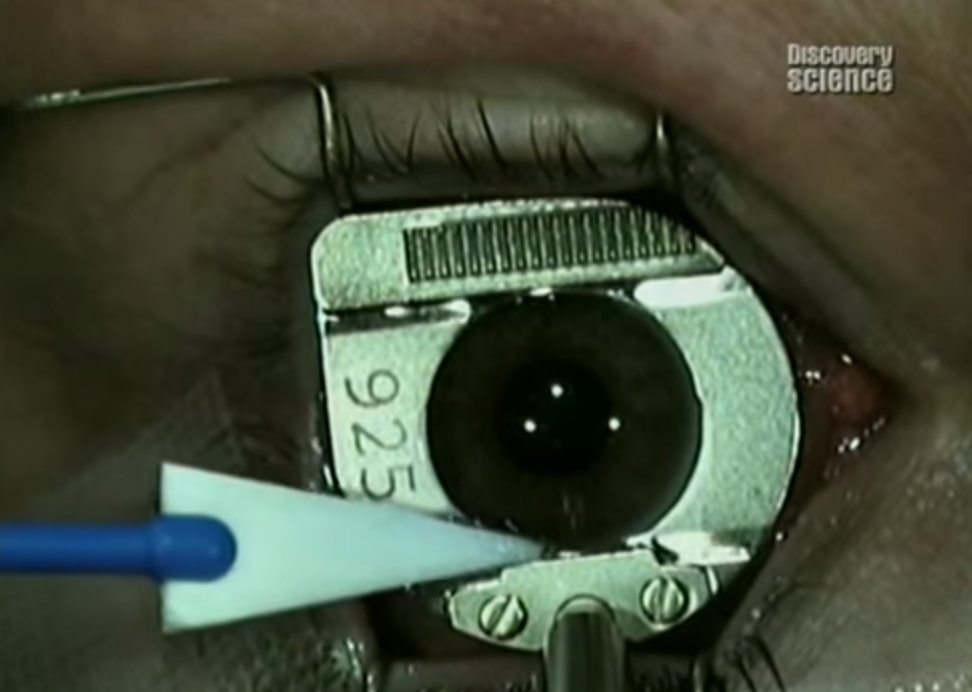
— Делают ли в России малоинвазивные операции по лазерной коррекции зрения методом извлечения лентикулы (Small Incision Lenticule Extraction)?
— Делают ли в России малоинвазивные операции по лазерной коррекции зрения методом извлечения лентикулы (Small Incision Lenticule Extraction)?
Да, примерно уже 5 лет. С каждым годом всё больше и больше на конференциях офтальмологов возникают вопросы не уровня «Что это?», а конкретные практические по нюансам технологии. Лазеры VisuMax есть в нескольких клиниках России, но именно под ReLEx SMILE используются значительно меньше, чем под femtoLASIK. Исторически так сложилось в России, что эта технология мало используется в центральной части и активно используется за Уралом.
— Что за история с лицензиями на конкретные операции?
Цейс продаёт конусы вместе с лицензиями. Конус — сменная деталь, прилегающая к глазу, покупается вместе с лицензией на использование лазерной процедуры, обычно пакетами по 10 или 100 операций. Поступает, например, 10 конусов и 10 лицензий. Лицензии вбиваются через меню лазера, и он позволяет по разу использовать соответствующие конусы для соответствующих типов программы. Лицензии на SMILE отдельно, на femtoLASIK отдельно, на FLEX, кольца и докоррекции также отдельные лицензии. У большинства производителей фемтосекундных и некоторых эксимерных лазеров похожая ситуация. Не нужны лицензии на эксимерные операции, пожалуй, разве на моделях примерно 5-летней давности и старше.
— И можно не получить такую лицензию на SMILE?
Запросто. Во-первых, этот модуль в лазере стоит как дорогостоящая опция, так что сам прибор без опции SMILE стоит дешевле. Во-вторых, если эта опция имеется, то лицензии на проведение операции ReLEx SMILE возможно приобрести только после проведения 5–10 тестовых прогонов на свиных глазах, затем проведения минимум 10 операций femtoLASIK на пациентах, затем 50 операций FLEX, и только после этого можно будет купить лицензию на SMILE для конкретного хирурга.







 Данное занятие мы посвятим методам обучения без учителя (unsupervised learning), в частности методу главных компонент (PCA — principal component analysis) и кластеризации. Вы узнаете, зачем снижать размерность в данных, как это делать и какие есть способы группирования схожих наблюдений в данных.
Данное занятие мы посвятим методам обучения без учителя (unsupervised learning), в частности методу главных компонент (PCA — principal component analysis) и кластеризации. Вы узнаете, зачем снижать размерность в данных, как это делать и какие есть способы группирования схожих наблюдений в данных.