Этим постом я хочу привлечь внимание к интересной области прикладного программирования, бурно развивающейся в последние годы — компьютерной лингвистике. А именно — системам, способным к разбору и пониманию текста на русском языке. Но основной фокус внимания я хочу сместить с академических и промышленных систем, в которые вложены десятки и тысячи человеко-часов, к описанию тех способов, какими успехов на этом поприще могут добиться любители.

Михаил Борисов @MichaelBorisov
User
Structure from Motion — классическая реализация
5 min

Есть такая интересная задача — построение 3D структуры по набору изображений (фотографий) — Structure from Motion. Как её можно решить? После некоторых размышлений приходит на ум такой алгоритм. Найдём на всех изображениях характерные особенности (точки), сопоставим их друг с другом и триангуляцией найдём их трёхмерные координаты. Тут правда есть проблема — неизвестно положение камер при съёмке. Можно ли их найти? Вроде можно. Действительно, пусть у нас N точек на кадре и M кадров. Тогда неизвестных будет 3 * N (трёхмерные координаты точек) + 6 * (M — 1) (координаты камер (вместо 6 может стоять другое число, но сути это не меняет)). Уравнений же у нас 2 * M * N (у каждой точки на каждом изображении есть две координаты). Выходит, что уже для двух изображений и 6 точек задачка разрешима. Под катом описание принципиальной схемы решения задачи SfM (по возможности без формул — но со ссылками для вдумчивого изучения).
Для новичков про stdafx.h
11 min
Статья рассчитана на людей, которые знакомятся со средой Visual Studio и пытаются компилировать в ней свои Си++-проекты. В незнакомой среде всё кажется странным и непонятным. Особенно новичков раздражает файл stdafx.h, из-за которого возникают странные ошибки во время компиляции. Очень часто всё заканчивается тем, что новичок долгое время везде старательно отключает Precompiled Headers. Чтобы помочь людям разобраться что к чему, и была написана эта статья.
Как я возил робота, чуть не поседел и залил кровью серверную
13 min
Это история одного из самых запомнившихся случаев в моей инженерной практике. По понятным причинам я поменял имена, места и некоторые узнаваемые детали, чтобы нельзя было точно определить заказчика и других участников истории.

Вот так выглядит ленточное хранилище (наше было поменьше) и библиотечный робот (наш такой же). Китаец в комплект не входит.
Помню, стояли последние дни ноября. Уже думая об окончании рабочего дня, я планировал свой вечер, когда вдруг мне сообщили, что в славном сибирском городе N у нашего заказчика сломалась ленточная библиотека. Запчасть сразу же отправили транспортной компанией, но вот уже 3 дня, как она все еще была в пути. Транспортная компания невнятно объяснялась и хмыкала в телефон, а заказчик стал не в шутку нервничать. Прогнозы были неопределенные, поэтому было принято решение везти еще одну запчасть своими силами на самолете. Сотрудник склада вручил мне габаритную коробку весом килограмм десять, обклеенную штрих-кодами и стикерами, и радостно хлопнул меня по плечу со словами: «Только не вздумай в багаж сдавать — помнут».
Коробка меня, безусловно, беспокоила, но не меньшее беспокойство мне внушал пакет с сухим молоком, который в последний момент мне вручил менеджер проекта. «У них там какие-то траблы с молочкой сейчас… из-за непогоды что ли… ребята местные просили 2 кг им привезти. Тебе ж не сложно?» — сказал он. По выражению его лица и характерному жесту ладони, как бы прикрывавшей мне рот, было ясно, как он сейчас хотел, чтобы я оказался сговорчивым или даже немым.
Вот так выглядит ленточное хранилище (наше было поменьше) и библиотечный робот (наш такой же). Китаец в комплект не входит.
Часть 1. Коробка
Помню, стояли последние дни ноября. Уже думая об окончании рабочего дня, я планировал свой вечер, когда вдруг мне сообщили, что в славном сибирском городе N у нашего заказчика сломалась ленточная библиотека. Запчасть сразу же отправили транспортной компанией, но вот уже 3 дня, как она все еще была в пути. Транспортная компания невнятно объяснялась и хмыкала в телефон, а заказчик стал не в шутку нервничать. Прогнозы были неопределенные, поэтому было принято решение везти еще одну запчасть своими силами на самолете. Сотрудник склада вручил мне габаритную коробку весом килограмм десять, обклеенную штрих-кодами и стикерами, и радостно хлопнул меня по плечу со словами: «Только не вздумай в багаж сдавать — помнут».
Коробка меня, безусловно, беспокоила, но не меньшее беспокойство мне внушал пакет с сухим молоком, который в последний момент мне вручил менеджер проекта. «У них там какие-то траблы с молочкой сейчас… из-за непогоды что ли… ребята местные просили 2 кг им привезти. Тебе ж не сложно?» — сказал он. По выражению его лица и характерному жесту ладони, как бы прикрывавшей мне рот, было ясно, как он сейчас хотел, чтобы я оказался сговорчивым или даже немым.
Решение задачи линейной регрессии с помощью быстрого преобразования Хафа
7 min
Введение
Друзья, рассмотрим нынче же задачу линейной регрессии в присутствии выбросового (некоррелированного с сигналом) шума. Эта задача часто возникает при обработке изображений (напр., при цветовой сегментации [1]), в том числе — акустических [2]. В случаях, когда координаты случайных величин можно грубо дискретизовать, а размерность задачи низка (2-3), кроме стандартных методов робастной регрессии можно воспользоваться быстрым преобразованием Хафа (БПХ) [3]. Попробуем сравнить этот последний метод по точности и устойчивости с «классическими».
Использование БПХ для линейной регрессии
Задача линейной регрессии на плоскости состоит в восстановлении линейной зависимости между двумя переменными, заданными в виде множества пар (x, y). Задавшись некоторым уровнем дискретизации координат, можно отобразить это множество на однобитном или целочисленном изображении (в первом случае мы отмечаем только факт наличия в исходных данных точки с примерно такими координатами, во втором — еще и их число). Фактически, речь идет о двумерной гистограмме исходных данных. Таким образом, неформально задача может быть сведена к поиску на изображении прямой, которая наилучшим образом описывает изображенное распределение точек.В обработке изображений в подобных случаях используется преобразование Хафа.
Преобразование Хафа является дискретным аналогом преобразования Радона и ставит в соответствие каждой прямой на изображении сумму яркостей пикселей вдоль нее (то есть одновременно вычисляет всевозможные суммы вдоль дискретных прямых). Можно ввести разумную дискретизацию прямых по сдвигам и наклонам так, чтобы параллельные дискретные прямые плотно упаковывали плоскость, а выходящие из одной точки на одном крае изображения прямые расходились по наклону на противоположном крае на целое число пикселей. Тогда таких дискретных прямых на квадрате n2 будет примерно 4 * n2. Для этой дискретизации существует алгоритм быстрого вычисления преобразования Хафа с ассимптотикой O(n2 * log n). Этот алгоритм является близким аналогом алгоритма быстрого преобразования Фурье, хорошо параллелизуется и не требует никаких операций, кроме сложения. В работе [3] можно прочитать об этом чуть больше, кроме того, там объясняется, почему преобразование Хафа от сглаженного гауссовским фильтром изображения вообще можно применять в задаче линейной регресии. Здесь же мы продемонстрируем устойчивость этого метода.
Катушка Тесла из хозмага
5 min
Имея патологическую тягу к сантехнической фурнитуре никак не могу приучить себя использовать ее по прямому назначению. Всегда в голову лезут идеи, что сделать из труб, фитингов и переходников так, чтобы уже никогда не использовать их в сантехнике. Так получилось и в этот раз. Делаем высоковольтный генератор Тесла на сантехнической фурнитуре.
Мультиклеточный процессор — это что?
18 min
Многие слышали о мультиклеточной архитектуре, процессорах и даже первых устройствах на них. Особенно продвинутые пользователи опробовали свои алгоритмы. Были проведены первые простые тесты производительности, а также пользователь Barsmonster, вытравил кристалл процессора Р1. Сейчас уже проходит первые проверки процессор R1 и скоро будет доступен всем. Но ответ на вопрос о том, как работает мультиклеточная архитектура и в чём её отличие, знают не все. Попытаемся сейчас ввести в курс дела.
Создание аудиоплагинов, часть 7
10 min
Tutorial
Все посты серии:
Часть 1. Введение и настройка
Часть 2. Изучение кода
Часть 3. VST и AU
Часть 4. Цифровой дисторшн
Часть 5. Пресеты и GUI
Часть 6. Синтез сигналов
Часть 7. Получение MIDI сообщений
Часть 8. Виртуальная клавиатура
Часть 9. Огибающие
Часть 10. Доработка GUI
Часть 11. Фильтр
Часть 12. Низкочастотный осциллятор
Часть 13. Редизайн
Часть 14. Полифония 1
Часть 15. Полифония 2
Часть 16. Антиалиасинг
Пока что мы генерировали только постоянную звуковую волну, которая просто звучала на заданной частоте. Давайте посмотрим, как можно реагировать на MIDI сообщения, включать и выключать генерацию волны на нужной частоте в зависимости от получаемой ноты.
Часть 1. Введение и настройка
Часть 2. Изучение кода
Часть 3. VST и AU
Часть 4. Цифровой дисторшн
Часть 5. Пресеты и GUI
Часть 6. Синтез сигналов
Часть 7. Получение MIDI сообщений
Часть 8. Виртуальная клавиатура
Часть 9. Огибающие
Часть 10. Доработка GUI
Часть 11. Фильтр
Часть 12. Низкочастотный осциллятор
Часть 13. Редизайн
Часть 14. Полифония 1
Часть 15. Полифония 2
Часть 16. Антиалиасинг
Пока что мы генерировали только постоянную звуковую волну, которая просто звучала на заданной частоте. Давайте посмотрим, как можно реагировать на MIDI сообщения, включать и выключать генерацию волны на нужной частоте в зависимости от получаемой ноты.
Простой способ сделать из обычного текста продающий
3 min

Чтобы клиент оценил все прелести вашего предложения, он должен прочитать об этом на вашем сайте. Проблема в том, что тексты в вебе пользователи игнорируют все чаще — избалованный графикой взгляд предпочитает цепляться за красивые картинки и пиктограммы, все большее значение приобретает форма подачи. Если посетитель сайта дочитал текст, вероятность заказа возрастает в несколько раз. Как привлечь посетителя к тексту и помочь прочитать? Нужно сконцентрироваться на самом важном, правильно расставить акценты, красиво оформить и пригласить к действию. Почему если это все понимают, никто (или почти никто) не уделяет этому внимания?
Многим сложно сформировать у себя в голове четкую и красивую структуру текста и воплотить ее на сайте средствами панели управления. Именно для них мы сформировали простой шаблон. Вставляете его в WYSIWYG-редактор, заменяете текст, картинки — и вуаля!
Защита подъезда методом организации разумного видеонаблюдения без консьержа
13 min
 Так получилось, что какой бы ни был аккуратный микрорайон, он всегда с чем-нибудь соседствует, плюс всегда есть праздношатающиеся, непраздношатающиеся и «этождети». Это если забыть про наркоманов, целенаправленных воров и разбойников. Твой дом — твоя крепость. Подъезд твоего дома — тоже твой дом. (Да, этот пункт многие не понимают, но учиться никогда не поздно). Классические методы защиты подъезда — установка укреплённых дверей; установка домофона; инсталляция консьержки; организация видеонаблюдения над входами.
Так получилось, что какой бы ни был аккуратный микрорайон, он всегда с чем-нибудь соседствует, плюс всегда есть праздношатающиеся, непраздношатающиеся и «этождети». Это если забыть про наркоманов, целенаправленных воров и разбойников. Твой дом — твоя крепость. Подъезд твоего дома — тоже твой дом. (Да, этот пункт многие не понимают, но учиться никогда не поздно). Классические методы защиты подъезда — установка укреплённых дверей; установка домофона; инсталляция консьержки; организация видеонаблюдения над входами.Вот только двери легко открываются при малейшей ошибке их производства, многие домофоны подвержены ключам-«вездеходам», консьержки часто спят и ничего не делают, а видеонаблюдение за которым никто не наблюдает превращается в бесполезную трату денег. В результате, почти все попытки улучшить общественную ситуацию зарезаются соседями методом слонёнка: «а нафига они нам нужны».
Однако, если включить мозги и подумать, на самом деле можно весьма небольшими вложениями получить очень эффективный результат.
Распознавание речи для чайников
9 min
Tutorial

В этой статье я хочу рассмотреть основы такой интереснейшей области разработки ПО как Распознавание Речи. Экспертом в данной теме я, естественно, не являюсь, поэтому мой рассказ будет изобиловать неточностями, ошибками и разочарованиями. Тем не менее, главной целью моего «труда», как можно понять из названия, является не профессиональный разбор проблемы, а описание базовых понятий, проблем и их решений. В общем, прошу всех заинтересовавшихся пожаловать под кат!
Эксплуатация концептуальных недостатков беспроводных сетей
3 min

Беспроводные сети окружают нас повсеместно, вокруг миллионы гаджетов, постоянно обменивающихся информацией с Всемирной Паутиной. Как известно — информация правит миром, а значит рядом всегда может оказаться кто-то очень сильно интересующийся данными, что передают ваши беспроводные устройства.
Это может быть как криминальный интерес, так и вполне законное исследование безопасности компании со всеми предварительными условиями. Для таких исследователей и написана эта коротенькая статья, потому как лишняя точка сбора информации во время пентеста не помешает.
Бутлоадер с AES-128 и EAX на AVR Assembler в 1024 байта
23 min
Или как я перестал бояться и полюбил ассемблер
Однажды летом, я устроился в родном университете программистом микроконтроллеров. В процессе общения с нашим главным инженером (здравствуйте, Алексей!), я узнал, что чипы спиливают, проекты воруют, заказчики кидают и появление китайского клона наших программаторов для автомобильной электроники — лишь вопрос времени, задавить их можно только высоким качеством. При всем этом, в паранойю впадать нельзя, пользователи вряд ли захотят работать с нашими железками в ошейниках со взрывчаткой.
Хорошая мера защиты — обновления программного обеспечения. Китайские клоны автоматически отмирают после каждой новой прошивки, а лояльные пользователи получают нашу любовь, заботу и новые возможности. Робин Гуды при таком раскладе, естественно, достанут свои логические анализаторы, HEX-редакторы и начнут ковырять процесс прошивки с целью ублажения русско-китайского сообщества.
Хоть у нас и не было проектов, которые требуют подобных мер защиты, было понятно: заняться этим надо, когда-то это пригодится. Погуглено — не найдено, придумано — сделано. В этой статье, я расскажу, как уместить полноценное шифрование в 1 килобайт и почему ассемблер — это прекрасно. Много текста, кода и небольшой сюрприз для любителей старого железа.
Возможно ли создать сильный искусственный интеллект, не копируя человеческий мозг?
6 min
Translation
 Необходимым условием наступления технологической сингулярности является создание «сильного искусственного интеллекта» (artificial superintelligence, ASI), способного самостоятельно модифицировать себя. Важно понимать, должен ли этот ИИ работать как человеческий разум, или хотя бы его платформа быть сконструированной аналогично мозгу?
Необходимым условием наступления технологической сингулярности является создание «сильного искусственного интеллекта» (artificial superintelligence, ASI), способного самостоятельно модифицировать себя. Важно понимать, должен ли этот ИИ работать как человеческий разум, или хотя бы его платформа быть сконструированной аналогично мозгу?Мозг животного (включая человека) и компьютер работают по-разному. Мозг является трехмерной сетью, «заточенной» под параллельную обработку огромных массивов данных, в то время как нынешние компьютеры обрабатывают информацию линейно, хотя и в миллионы раз быстрее, чем мозги. Микропроцессоры могут выполнять потрясающие расчеты со скоростью и эффективностью, значительно превышающими возможности человеческого мозга, но они используют совершенно другие подходы к обработке информации. Зато традиционные процессоры не очень хорошо справляются с параллельной обработкой больших объемов данных, которая необходима для решения сложных многофакторных задач или, например, распознавания образов.
Превращение обычного электрического конвектора в беспроводной
7 min
Предыстория
Мой частный дом отапливается при помощи электрических конвекторов. Всё в них хорошо: и лёгкость монтажа и автоматическое управление температурой и режим день/ночь и режим 50% мощности. Но есть и минус — датчик температуры воздуха закреплён прямо на корпусе конвектора, поэтому нагревается и остывает вместе с ним. Из-за этого конвектор включается/выключается гораздо чаще, чем хотелось бы, невозможно установить желаемую температуру воздуха в комнате, т.к. реальная будет ниже градусов на 5, да и на надёжности постоянные переключения реле сказываются негативно. Можно было, конечно, удлинить датчик температуры и отнести его подальше, но это не наш метод. Т.к. я давно занимаюсь беспроводными технологиями и есть наработки, то решил оснастить конвектор беспроводным датчиком температуры. Это позволит разместить его в любом месте комнаты, не тянуть провода, а если нужно, использовать не один, а несколько датчиков и рассчитывать среднюю по комнате температуру. (Под катом картинки)
Создание робота балансера на arduino
7 min
Мне давно не давало покоя желание рассчитать какой-нибудь достаточно сложный механизм и воплотить его жизнь.
Выбор пал на задачу об обратном маятнике. Итог на видео:
Выбор пал на задачу об обратном маятнике. Итог на видео:
Что такое Томита-парсер, как Яндекс с его помощью понимает естественный язык, и как вы с его помощью сможете извлекать факты из текстов
6 min
Мечта о том, чтобы машина понимала человеческий язык, завладела умами еще когда компьютеры были большими, а их производительность – маленькой. Главная проблема на пути к этому заключается в том, что грамматика и семантика естественных языков слабо поддаются формализации. Кроме того, от языков программирования их отличает присутствие многозначности.
Конечно, мечта о полноценной коммуникации с компьютером на естественном языке пока еще далека от полноценной реализации примерно настолько же, как и мечта об искусственном интеллекте. Однако некоторые результаты есть уже сейчас: машину можно научить находить нужные объекты в тексте на естественном языке, находить между ними связи и представлять необходимые данные в формализованном виде для дальнейшей обработки. В Яндексе уже достаточно давно применяется такая технология. Например, если вам придет письмо с предложением о встрече в определенном месте и в определенное время, специальный алгоритм самостоятельно извлечет нужные данные и предложит внести ее в календарь.
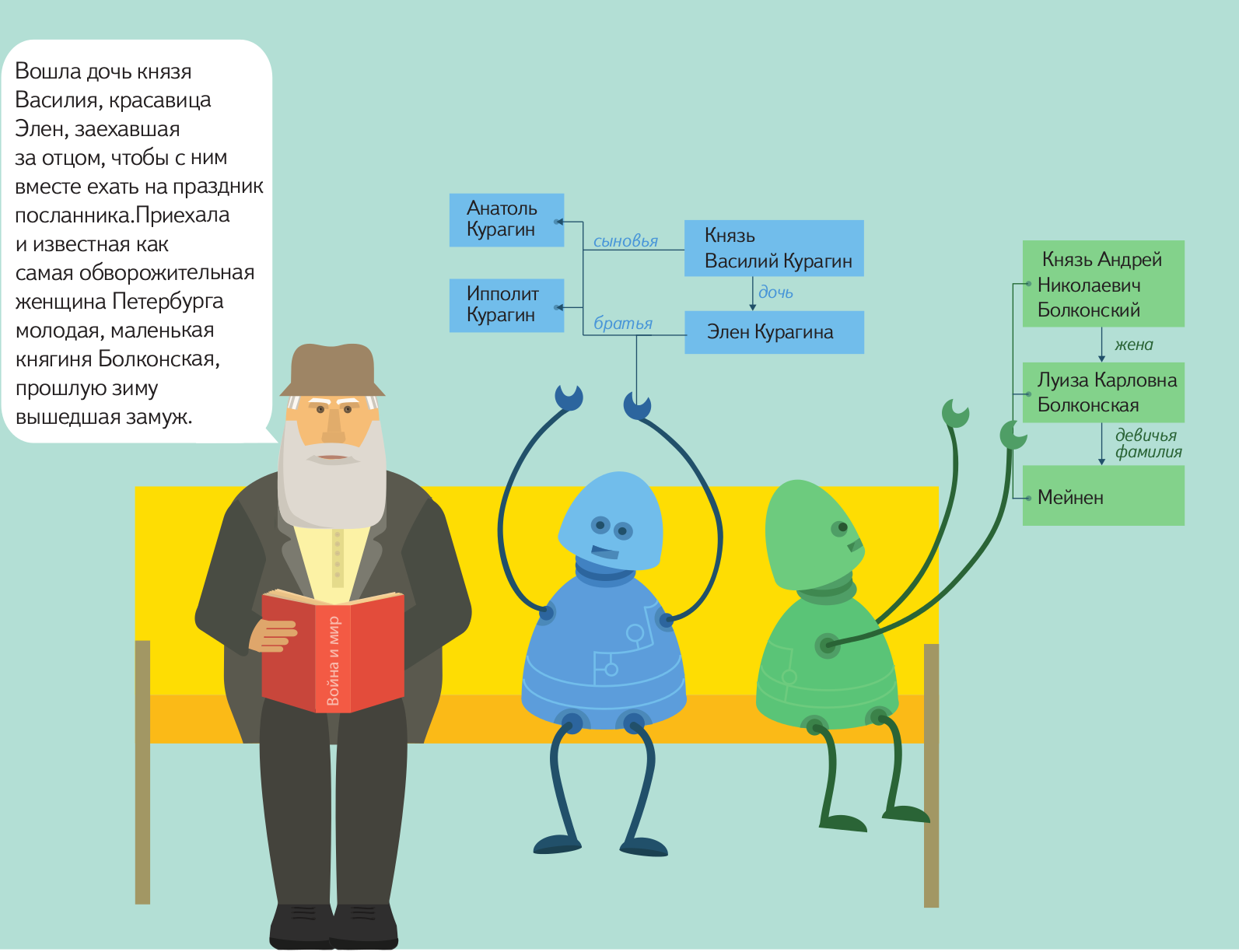
Вскоре мы планируем отдать эту технологию в open source, чтобы любой мог пользоваться ей и развивать ее, приближая тем самым светлое будущее свободного общения между человеком и компьютером. Подготовка к открытию исходных кодов уже началась, но процесс этот не такой быстрый, как нам бы хотелось, и, скорее всего, продлится до конца этого года. За это время мы постараемся как можно больше рассказать о своем продукте, для чего запускаем серию постов, в рамках которой расскажем об устройстве инструмента и принципах работы с ним.
Называется технология Томита-парсер, и по большому счету, любой желающий может воспользоваться ей уже сейчас: бинарные файлы доступны для скачивания. Однако прежде чем пользоваться технологией, нужно научиться ее правильно готовить.
Конечно, мечта о полноценной коммуникации с компьютером на естественном языке пока еще далека от полноценной реализации примерно настолько же, как и мечта об искусственном интеллекте. Однако некоторые результаты есть уже сейчас: машину можно научить находить нужные объекты в тексте на естественном языке, находить между ними связи и представлять необходимые данные в формализованном виде для дальнейшей обработки. В Яндексе уже достаточно давно применяется такая технология. Например, если вам придет письмо с предложением о встрече в определенном месте и в определенное время, специальный алгоритм самостоятельно извлечет нужные данные и предложит внести ее в календарь.
Вскоре мы планируем отдать эту технологию в open source, чтобы любой мог пользоваться ей и развивать ее, приближая тем самым светлое будущее свободного общения между человеком и компьютером. Подготовка к открытию исходных кодов уже началась, но процесс этот не такой быстрый, как нам бы хотелось, и, скорее всего, продлится до конца этого года. За это время мы постараемся как можно больше рассказать о своем продукте, для чего запускаем серию постов, в рамках которой расскажем об устройстве инструмента и принципах работы с ним.
Называется технология Томита-парсер, и по большому счету, любой желающий может воспользоваться ей уже сейчас: бинарные файлы доступны для скачивания. Однако прежде чем пользоваться технологией, нужно научиться ее правильно готовить.
Джон Резиг: Пишите код каждый день
5 min
Translation
Прошлой осенью работа над моими побочными проектами зашла в тупик: я практически не продвигался вперёд и у меня никак не получалось делать больше, не принося в жертву свою основную работу в Khan Academy.
В моей организации работы обнаружилось несколько серьёзных проблем. В основном я работал по выходным и иногда по вечерам. Как оказалось, это не самая лучшая для меня стратегия. Необходимость сделать за выходные как можно больше и лучше сильно давила на меня, а если мне не удавалось доделать задуманное, это ощущалось как провал. Проблему усугубляло и то, что не было никакой гарантии, что очередные выходные будут свободны, и даже если так — не факт, что я захочу кодить с утра до вечера все эти два дня — надо ведь иногда как-то развлечься или просто расслабиться.
Кроме того, недельный перерыв — это слишком много, очень легко забыть, над чем ты работал и на чём остановился, даже если делать заметки. А уж если в выходные поработать не удавалось — то перерыв растягивался на две недели. Такие многонедельные переключения контекста могут быть смертельными — многие мои проекты погибли, не родившись, от такого недостатка внимания.
Услышав о невероятном эксперименте Дженнифер Девальт, которая решила изучить программирование, создав 180 сайтов за 180 дней, я отважился испробовать сходную тактику: работать над побочными проектами каждый день.

Иллюстрация Стивена Резига
В моей организации работы обнаружилось несколько серьёзных проблем. В основном я работал по выходным и иногда по вечерам. Как оказалось, это не самая лучшая для меня стратегия. Необходимость сделать за выходные как можно больше и лучше сильно давила на меня, а если мне не удавалось доделать задуманное, это ощущалось как провал. Проблему усугубляло и то, что не было никакой гарантии, что очередные выходные будут свободны, и даже если так — не факт, что я захочу кодить с утра до вечера все эти два дня — надо ведь иногда как-то развлечься или просто расслабиться.
Кроме того, недельный перерыв — это слишком много, очень легко забыть, над чем ты работал и на чём остановился, даже если делать заметки. А уж если в выходные поработать не удавалось — то перерыв растягивался на две недели. Такие многонедельные переключения контекста могут быть смертельными — многие мои проекты погибли, не родившись, от такого недостатка внимания.
Услышав о невероятном эксперименте Дженнифер Девальт, которая решила изучить программирование, создав 180 сайтов за 180 дней, я отважился испробовать сходную тактику: работать над побочными проектами каждый день.
Иллюстрация Стивена Резига
Почему в России почти нет гражданского/коммерческого высокотехнологичного производства?
27 min
") Статью с обзором ситуации с микроэлектроникой в России я закончил утверждением, что сейчас в России есть технические возможности для создания любых военных микросхем (если не считаться с ценой). Однако и в комментариях к той статье, и во многих других — всех больше волновал вопрос отсутствия (на уровне погрешности измерений) производства чисто-коммерческих (гражданских) высокотехнологичных продуктов. Этот вопрос волновал и меня, потому я постоянно мучил вопросами всех, кто так или иначе связан с высокими технологиями и бизнесом в России.
Статью с обзором ситуации с микроэлектроникой в России я закончил утверждением, что сейчас в России есть технические возможности для создания любых военных микросхем (если не считаться с ценой). Однако и в комментариях к той статье, и во многих других — всех больше волновал вопрос отсутствия (на уровне погрешности измерений) производства чисто-коммерческих (гражданских) высокотехнологичных продуктов. Этот вопрос волновал и меня, потому я постоянно мучил вопросами всех, кто так или иначе связан с высокими технологиями и бизнесом в России. Ответ на него важен, если вы сами хотите создать конкурентный высокотехнологичный продукт — чтобы не потратить лучшие годы жизни в изначально неравных условиях.
Под катом попробуем разобраться чем отличаются «высокотехнологичные» компании от «низкотехнологичных», что нужно, чтобы высокотехнологичные компании могли рождаться и выживать, почему с софтом у нас лучше, чем с хардом, с чего начиналась кремниевая долина в США и можно ли её «скопировать», почему Китай всех рвет, а также — окинем взором все, что происходит в Сколково, Роснано, фонде перспективных исследований и приведут ли они к расцвету российских инноваций. Безусловно, я где-то могу ошибаться — буду рад дополнениям в комментариях.
Сразу нужно отметить, что в связи с многогранностью проблемы объем статьи получился довольно большой, так что можно начать читать с резюме в конце, и затем прочитать лишь те разделы, которые вызовут интерес. Сразу хочу предупредить — повествование «нелинейное», соседние заголовки могут описывать разные аспекты проблемы и быть друг с другом практически не связанными.
Сети для самых маленьких. Часть девятая. Мультикаст
51 min
Tutorial
Все выпуски
8.1. Сети для самых маленьких. Микровыпуск №3. iBGP
8. Сети для самых маленьких. Часть восьмая. BGP и IP SLA
7. Сети для самых маленьких. Часть седьмая. VPN
6. Сети для самых маленьких. Часть шестая. Динамическая маршрутизация
5. Сети для самых маленьких: Часть пятая. NAT и ACL
4. Сети для самых маленьких: Часть четвёртая. STP
3. Сети для самых маленьких: Часть третья. Статическая маршрутизация
2. Сети для самых маленьких. Часть вторая. Коммутация
1. Сети для самых маленьких. Часть первая. Подключение к оборудованию cisco
0. Сети для самых маленьких. Часть нулевая. Планирование
8. Сети для самых маленьких. Часть восьмая. BGP и IP SLA
7. Сети для самых маленьких. Часть седьмая. VPN
6. Сети для самых маленьких. Часть шестая. Динамическая маршрутизация
5. Сети для самых маленьких: Часть пятая. NAT и ACL
4. Сети для самых маленьких: Часть четвёртая. STP
3. Сети для самых маленьких: Часть третья. Статическая маршрутизация
2. Сети для самых маленьких. Часть вторая. Коммутация
1. Сети для самых маленьких. Часть первая. Подключение к оборудованию cisco
0. Сети для самых маленьких. Часть нулевая. Планирование
Наш умозрительный провайдер linkmeup взрослеет и обрастает по-тихоньку всеми услугами обычных операторов связи. Теперь мы доросли до IPTV.
Отсюда вытекает необходимость настройки мультикастовой маршрутизации и в первую очередь понимание того, что вообще такое мультикаст.
Это первое отклонение от привычных нам принципов работы IP-сетей. Всё-таки парадигма многоадресной рассылки в корне отличается от тёплого лампового юникаста.
Можно даже сказать, это в некоторой степени бросает вызов гибкости вашего разума в понимании новых подходов.
В этой статье сосредоточимся на следующем:
- Общее понимание Multicast
- Протокол IGMP
- Протокол PIM
- >>>PIM Dense Mode
- >>>Pim Sparse Mode
- >>>SPT Switchover — переключение RPT-SPT
- >>>DR, Assert, Forwarder
- >>>Автоматический выбор RP
- >>>SSM
- >>>BIDIR PIM
- Мультикаст на канальном уровне
- >>>IGMP-Snooping
- >>>MVR
