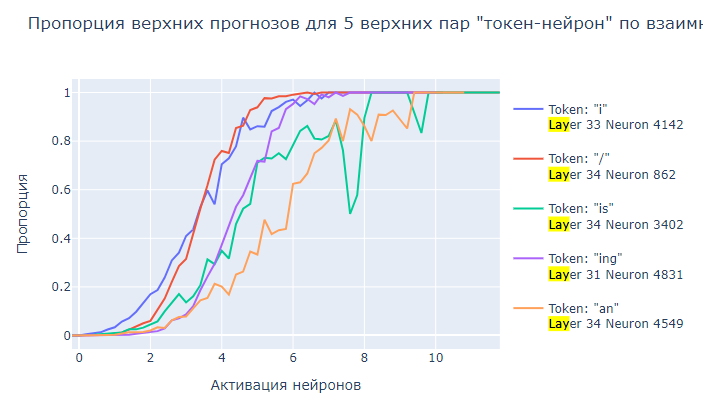
Предположим, вы программист и у вас есть два числа. Вы хотите узнать, какое из чисел больше. Если оба числа имеют одинаковый тип, то почти в любом языке программирования решение будет тривиальным. Для этой операции обычно даже есть специальный оператор
<=. Вот пример на Python:
>>> "120" <= "1132"
False
Сравнение двух чисел на Brainfuck оставим в качестве упражнения для читателя.
Ой. Ну, строго говоря, это строки, а не числа, а строки обычно сортируются
лексикографически. Но это всё-таки числа, хотя и представленные в виде строк. Это может показаться глупым, но такая проблема очень распространена в интерфейсах пользователя, например, в списках файлов. Именно поэтому нужно отбивать числовые имена файлов нулями (
frame-00001.png) или использовать описания, сохраняющие лексикографический порядок, например,
ISO 8601 для дат.
Впрочем, я отклонился от темы. Предположим, числа действительно представлены числовыми типами. Тогда всё просто и
<= отлично работает:
>>> 120 <= 1132
True
Но так ли это?