В этой теме хотелось бы познакомить читателей с относительно новым подходом к контролю доступа под названием Attribute-based access control. Знакомство будет происходить на примере сравнения с популярным нынче Role-based access control.
Уже год прошёл с того момента, как популярный сервис Miro закрыл офис в России и прекратил новые продажи российским пользователям. Сервис полностью не ушёл из России, вы можете зайти на их сайт и даже в прежнем режиме поработать на доске, но возникают сложности, если вам нужно больше, чем бесплатный тариф с ограничениями.
Одно из решений — рассмотреть российские онлайн-доски. Да, они есть и в условиях импортозамещения постоянно появляются новые. В этой статье расскажу, что происходит на российском рынке онлайн-досок, какие решения есть на замену зарубежным доскам и каким функционалам они обладают.
Текст про Midjourney привлек внимание, и в комментариях наметилась дискуссия про Stable Diffusion. Аргументы убедили меня попробовать SD самостоятельно, но вскоре я понял, что это не самая простая задача. Сообщество любителей Stable Diffusion произвело на свет множество удобных инструментов, которые своим количеством и сложностью могут отпугнуть новичков.
Всю неделю, что я экспериментировал с нейросетью, я боролся с желанием SD добавлять вторичные гендерные признаки по моим запросам и грустил, смотря на результаты генерации котиков. О своих страданиях частично писал в личном Telegram-канале — подписывайтесь! В этом же тексте — собрал основные советы по работе со Stable Diffusion и подвел итог, сравнив эту нейросеть с Midjourney.
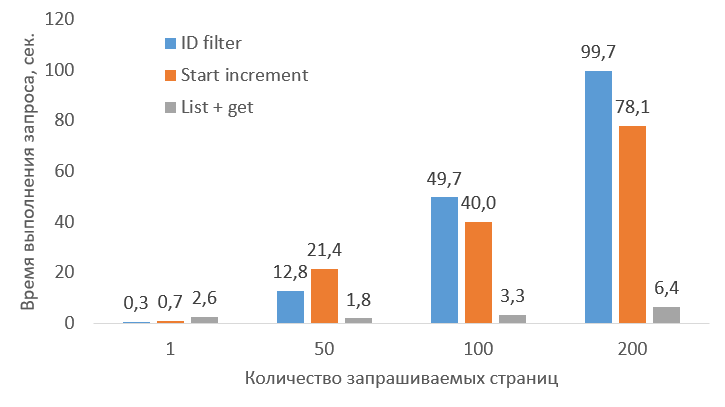
Нередко при работе с Bitrix24 REST API возникает необходимость быстро получить содержимое определенных полей всех элементов какого-то списка (например, лидов).
Традиционный способ для этого - обращение к серверу через метод *.list (например, crm.lead.list для лидов) с параметром select, перечисляющим список требуемых полей. При этом, чем больше полей вы запрашиваете, тем больше времени серверу требуется для формирования ответа. Плюс, в силу того, что информация сервером выдается постранично, получение всего списка через последовательные запросы всех страниц может занимать много времени.
Однако существует несколько стратегий для того, которые позволяют ускорить процесс на порядки.
С такой проблемой сталкивается огромное количество работодателей, когда подбор персонала превращается в бесконечный изматывающий процесс, которому нет ни конца, ни края. Рассказываем, почему такое происходит и что делать дальше?⬇
Всем привет! На днях прилетела интересная задача: «Найти бесплатные прокси-сервера». Взявшись за нее, решил обойти все сайты свободных проксей и понял — дохлые… ну или с высоким пингом.
После нескольких часов безуспешных поисков, было принято решение использовать свои ресурсы!
Итак, что в итоге должно получиться:
1. VM Ubuntu/Debian 2 CPU, 2GB RAM, 8GB HDD (ну тоесть совсем не требовательная) 2. PRIVOXY для проксирования запросов (Можно взять nginx, varnish — я взял Privoxy) 3. TOR сервер
В предыдущем посте я рассказал про то, как настроить и использовать php телеграм клиент madelineProto для парсинга постов. Но при использовании библиотеки я столкнулся с несколькими недостатками:
Долгая обработка запросов из-за авторизации телеграм клиента;
Неудобная настройка;
Проблемы с отдачей изображений из постов.
Поэтому решил создать два микросервиса на php для парсинга телеграм каналов, используя асинхронное расширение swoole. Теперь эти пакеты упрощают и ускоряют работу с telegram api (не путать с bot api) в нескольких моих проектах. Хочется поделится ими и услышать мнение других разработчиков.
Под катом расскажу об архитектуре, использовании разных областей видимости в swoole server и устранении последствий ошибок в сторонних библиотеках и внешних api. Ссылки на репозитории с исходным кодом и на тестовый сервер — в конце поста.
Несколько лет назад я начал разрабатывать свой агрегатор контента, что бы упростить свой серфинг в сети. Изначально я парсил только rss, vk и facebook, но в прошлом году решил сделать полный рефакторинг проекта: отказаться от парсинга на клиенте, сделать нормальный back-end, использовать базу данных для хранения данных и расширить список поддерживаемых ресурсов.
Помимо стандартного набора из rss, fb, vk, twitter, instagram, youtube я добавил поддержку произвольных открытых каналов из telegram.
Под катом пошаговая инструкция, как парсить любые каналы в telegram без регистрации и смс.
[UPDATE 2019-03-12] Мой новый пост про парсинг телеграм каналов: habr.com/ru/post/354000. Более качественный код, микросервисы с открытым исходным кодом и новый публичный сервер для тестов. [UPDATE 2023-10-08] Важное напоминание: Телеграмм не разрешает парсить аудиторию каналов. Используя серверный клиент можно получить только те данные, которые видны в обычном, оффициальном приложении.