Преобразование Хафа — это метод обнаружения прямых и кривых линий на полутоновых или цветных изображениях. Метод позволяет указать параметры семейства кривых и обеспечивает поиск на изображении множества кривых заданного семейства. Мы рассмотрим его применение для поиска на изображении прямолинейных отрезков и дуг окружностей.

User
LLVM изнутри: как это работает
10 min
 Приветствую хабраюзеров, в этой статье пойдет речь о внутреннем устройстве компилятора LLVM. О том, что LLVM вообще такое, можно прочитать здесь или на llvm.org. Как известно, LLVM (условно) состоит из трех частей — байткода, стратегии компиляции и окружения aka LLVM infrastructure. Я рассмотрю последнее.
Приветствую хабраюзеров, в этой статье пойдет речь о внутреннем устройстве компилятора LLVM. О том, что LLVM вообще такое, можно прочитать здесь или на llvm.org. Как известно, LLVM (условно) состоит из трех частей — байткода, стратегии компиляции и окружения aka LLVM infrastructure. Я рассмотрю последнее.Содержание:
- Сборка LLVM
- Привязка к Eclipse
- Архитектура окружения
- LLVM API
- Оптимизация Hello, World!
Пишем свою ОС: Выпуск 1
6 min
Данный цикл статей посвящён низкоуровневому программированию, то есть архитектуре компьютера, устройству операционных систем, программированию на языке ассемблера и смежным областям. Пока что написанием занимаются два хабраюзера — iley и pehat. Для многих старшеклассников, студентов, да и профессиональных программистов эти темы оказываются весьма сложными при обучении. Существует много литературы и курсов, посвящённых низкоуровневому программированию, но по ним сложно составить полную и всеохватывающую картину. Сложно, прочитав одну-две книги по ассемблеру и операционным системам, хотя бы в общих чертах представить, как же на самом деле работает эта сложная система из железа, кремния и множества программ — компьютер.
Каждый решает проблему обучения по-своему. Кто-то читает много литературы, кто-то старается поскорее перейти к практике и разбираться по ходу дела, кто-то пытается объяснять друзьям всё, что сам изучает. А мы решили совместить эти подходы. Итак, в этом курсе статей мы будем шаг за шагом демонстрировать, как пишется простая операционная система. Статьи будут носить обзорный характер, то есть в них не будет исчерпывающих теоретических сведений, однако мы будем всегда стараться предоставить ссылки на хорошие теоретические материалы и ответить на все возникающие вопросы. Чёткого плана у нас нет, так что многие важные решения будут приниматься по ходу дела, с учётом ваших отзывов.
Каждый решает проблему обучения по-своему. Кто-то читает много литературы, кто-то старается поскорее перейти к практике и разбираться по ходу дела, кто-то пытается объяснять друзьям всё, что сам изучает. А мы решили совместить эти подходы. Итак, в этом курсе статей мы будем шаг за шагом демонстрировать, как пишется простая операционная система. Статьи будут носить обзорный характер, то есть в них не будет исчерпывающих теоретических сведений, однако мы будем всегда стараться предоставить ссылки на хорошие теоретические материалы и ответить на все возникающие вопросы. Чёткого плана у нас нет, так что многие важные решения будут приниматься по ходу дела, с учётом ваших отзывов.
Декартово дерево: Часть 1. Описание, операции, применения
15 min
Оглавление (на данный момент)
Часть 1. Описание, операции, применения.
Часть 2. Ценная информация в дереве и множественные операции с ней.
Часть 3. Декартово дерево по неявному ключу.
To be continued...
Декартово дерево (cartesian tree, treap) — красивая и легко реализующаяся структура данных, которая с минимальными усилиями позволит вам производить многие скоростные операции над массивами ваших данных. Что характерно, на Хабрахабре единственное его упоминание я нашел в обзорном посте многоуважаемого winger, но тогда продолжение тому циклу так и не последовало. Обидно, кстати.
Я постараюсь покрыть все, что мне известно по теме — несмотря на то, что известно мне сравнительно не так уж много, материала вполне хватит поста на два, а то и на три. Все алгоритмы иллюстрируются исходниками на C# (а так как я любитель функционального программирования, то где-нибудь в послесловии речь зайдет и о F# — но это читать не обязательно :). Итак, приступим.
Введение
В качестве введения рекомендую прочесть пост про двоичные деревья поиска того же winger, поскольку без понимания того, что такое дерево, дерево поиска, а так же без знания оценок сложности алгоритма многое из материала данной статьи останется для вас китайской грамотой. Обидно, правда?
Следующий пункт нашей обязательной программы — куча (heap). Думаю, также многим известная структура данных, однако краткий обзор я все же приведу.
Представьте себе двоичное дерево с какими-то данными (ключами) в вершинах. И для каждой вершины мы в обязательном порядке требуем следующее: ее ключ строго больше, чем ключи ее непосредственных сыновей. Вот небольшой пример корректной кучи:
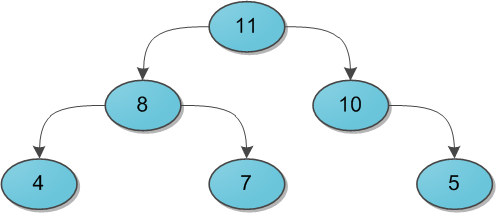
На заметку сразу скажу, что совершенно не обязательно думать про кучу исключительно как структуру, у которой родитель больше, чем его потомки. Никто не запрещает взять противоположный вариант и считать, что родитель меньше потомков — главное, выберите что-то одно для всего дерева. Для нужд этой статьи гораздо удобнее будет использовать вариант со знаком «больше».
Сейчас за кадром остается вопрос, каким образом в кучу можно добавлять и удалять из нее элементы. Во-первых, эти алгоритмы требуют отдельного места на осмотр, а во-вторых, нам они все равно не понадобятся.
Корпоративный Jabber сервер: догнать и перегнать Google
7 min
 Я думаю все знают про Google Apps. Это великолепный сервис для организации почты и коллективной работы в рамках компании. Однако у него есть пара маленьких таких недостатков: он предоставляется as is во-первых, и вся ваша корпоративная документация, почта и переписка при использовании Google Apps будут храниться на серверах Google.
Я думаю все знают про Google Apps. Это великолепный сервис для организации почты и коллективной работы в рамках компании. Однако у него есть пара маленьких таких недостатков: он предоставляется as is во-первых, и вся ваша корпоративная документация, почта и переписка при использовании Google Apps будут храниться на серверах Google.В итоге чаще всего серьёзные фирмы выбирают сложный путь — поддерживать все необходимые сервисы на собственных серверах. Этот путь, конечно, даёт массу преимуществ. Системный администратор компании сможет настроить что угодно и как угодно. Однако есть и один существенный недостаток: если у Google всё уже настроено и связано воедино, то вам придётся настраивать всё вручную. Плюс вы вряд ли сможете обеспечить вашу систему таким же красивым и удобным веб-интерфейсом.
Однако, как показывает практика, развернуть гибкую и мощную инфраструктуру для компании можно легко и не прибегая к помощи Google. Под катом я расскажу как интегрировать XMPP сервер с почтовой системой, чтобы получилось в итоге значительно лучше, чем у Google.

Уязвимость связки PHP+nginx с кривым конфигом
1 min
Summary
Announced: 2010-05-20
Credits: 80sec
Affects: сайты на ngnix+php с возможностью загрузки файлов в директории с fastcgi_pass

Background
Зачастую How-To по настройке связки nginx с php-fpm / php-cgi есть подобные строчки:
location ~ \.php$ {
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name;
include fastcgi_params;
}
Scala: Кэширование результатов исполнения методов
4 min
Иногда возникает необходимость кэширования результатов исполнения методов. Одно из возможных решений для java описано здесь. Всё, в принципе, тривиально: EHCache, Spring AOP для перехвата вызовов, немножко кода.
Рассмотрим, как мне кажется, более элегантное решение на scala.
Рассмотрим, как мне кажется, более элегантное решение на scala.
Обзор моделей работы с потоками
4 min
Translation
Обзор моделей работы с потоками
Многие люди не понимают того, как многопоточность реализована в различных языках программирования. В наши времена многоядерных процессоров такое знание будет весьма полезно.
Вот вам небольшой обзор.
Map/Reduce своими руками — Apache CouchDb
5 min
 Предупреждаю — мой взгляд совершенно не претендует на какую бы то ни было объективность. Но реляционные базы данных меня никогда, мягко говоря, не вдохновляли.
Предупреждаю — мой взгляд совершенно не претендует на какую бы то ни было объективность. Но реляционные базы данных меня никогда, мягко говоря, не вдохновляли. Нет, я вполне понимаю когда у вас действительно приложение ориентировано на обработку и хранение больших массивов данных. Ну, ERP-системы, всякие хранилища, статистика там, «в прошлом месяце продали сто тыщ карандашей, в этом двести».
С другой стороны, в большинстве случаев, когда речь идет о десктопных (или веб-) приложениях, где не нужно ворочать миллионами примитивных записей, а приложение работает с относительно высокоуровневыми, сложными объектами, суть «дизайна и проектирования баз данных» заключается в повторении двух действий:
Из чего готовят Google Analytics Cookies
3 min
Tutorial

Добрый день.
Недавно одни из наших заказчиков выразили желание получать дополнительную информацию о посетителях своего сайта, конкретнее — о людях, заполнивших контактную форму. Это крупная европейская компания и им хотелось бы «фильтровать» своих потенциальных клиентов. Поясню на примере — допустим, решают они организовать выставку своего оборудования в Венгрии и им нужно решить, кто из венгров, оставлявших им свои контакты, скорее всего стоящий клиент, а кто «мимо проходил».
Основными показателями «надежности» клиента для нас стали: число посещений сайта, время проведенное на сайте, количество просмотренных страниц. Всю эту информацию мы получили из Google Analytics Cookies.
Что же из себя представляют печеньки от Google?
WTF is a SuperColumn? Введение в модель данных Cassandra
17 min
Translation
Это перевод статьи, датированной 1м сентября 2009 года, следует это учесть при прочтении. — прим. пер.
В последний месяц или два команда инженеров Digg потратила совсем немного времени на изучение, тестирование и окончательное внедрение Cassandra в продакшен. Это был очень веcёлый проект, но до того, как веселье началось, нам пришлось потратить какое-то время на выяснение того, что же представляет собой модель данных Cassandra… фраза «WTF is a «super column»» («что за фигня этот суперстолбец?») была произнесена не один раз.
Если вы работали ранее с РСУБД (это касается почти всех), вы вероятно будете немного обескуражены некоторыми названиями при изучении модели данных Cassandra. Мне и моей команде в Digg потребовалось несколько дней обсуждений, прежде чем мы «врубились». Пару недель назад в списке рассылки разработчиков шёл процесс bikeshed-а на тему полностью новой схемы именования для разрешения неразберихи. На всём протяжении дискуссии я думал: «может, если будет несколько нормальных примеров, люди не будут так смущены названиями». Так, это моя попытка объяснения модели данных Cassandra; она предназначена для того, чтобы вы ознакомились, но не уходили в дебри, и, надеюсь, это поможет прояснить некоторые вещи.
В последний месяц или два команда инженеров Digg потратила совсем немного времени на изучение, тестирование и окончательное внедрение Cassandra в продакшен. Это был очень веcёлый проект, но до того, как веселье началось, нам пришлось потратить какое-то время на выяснение того, что же представляет собой модель данных Cassandra… фраза «WTF is a «super column»» («что за фигня этот суперстолбец?») была произнесена не один раз.
Если вы работали ранее с РСУБД (это касается почти всех), вы вероятно будете немного обескуражены некоторыми названиями при изучении модели данных Cassandra. Мне и моей команде в Digg потребовалось несколько дней обсуждений, прежде чем мы «врубились». Пару недель назад в списке рассылки разработчиков шёл процесс bikeshed-а на тему полностью новой схемы именования для разрешения неразберихи. На всём протяжении дискуссии я думал: «может, если будет несколько нормальных примеров, люди не будут так смущены названиями». Так, это моя попытка объяснения модели данных Cassandra; она предназначена для того, чтобы вы ознакомились, но не уходили в дебри, и, надеюсь, это поможет прояснить некоторые вещи.
Сервис для сборки Zend Framework в один файл
1 min
Здравствуйте, уважаемые хабрачитатели!
Сей краткий пост посвящен небольшому сервису по сборке Zend Framework-a в один файл.
Зачем это делать, не раз уже писалось на хабре (например, тут), но если кому-то лень читать, я передам основной тезис: при использовании кэшера опкода (к примеру, eaccelerator) сборка фреймворка в один файл дает большой прирост производительности.
Сервис находится здесь. Кроме меня, его никто не тестировал, так что прошу сообщать о найденных багах.
На данный момент исходным материалом для сборок служит Zend Framework версии 1.10.2.
Буду рад, если кому-то это окажется полезным.
Сей краткий пост посвящен небольшому сервису по сборке Zend Framework-a в один файл.
Зачем это делать, не раз уже писалось на хабре (например, тут), но если кому-то лень читать, я передам основной тезис: при использовании кэшера опкода (к примеру, eaccelerator) сборка фреймворка в один файл дает большой прирост производительности.
Сервис находится здесь. Кроме меня, его никто не тестировал, так что прошу сообщать о найденных багах.
На данный момент исходным материалом для сборок служит Zend Framework версии 1.10.2.
Буду рад, если кому-то это окажется полезным.
Syn — библиотека синтетических событий, которая делает тестирование проще
2 min
Translation
Команда Jupiter IT выпустила Syn, библиотеку, которая позволяет вам создавать синтетические события для использования при тестировании. Эта отдельная библиотека предназначена для оказания помощи в тестировании сложного поведения пользовательского интерфейса, имитируя действия пользователя, такие как печать с помощью клавиатуры, нажатие кнопок мыши и перетаскивание с её помощью.
7 бесплатных сервисов для проверки сайтов (о которых вы могли и не знать)
2 min

Мне достаточно часто приходится использовать различные онлайн-сервисы для проверки доступности сайтов и их поверхностных тестов и проверок.
Как показал краткий опрос коллег — почти у всех эти наборы сервисов отличаются. Я хочу показать вам свой, прошу в
progress bar для консольных утилит
1 min
По долгу службы мне время от времени приходится копировать, архивировать, разархивировать и проводить другие стандартные действия с большими файлами. Консольные утилиты, типа cp, tar или cat — отлично справляются с поставленной перед ними задачей, но возникает одна маленькая проблема: предположим, что надо заархивировать SQL-дамп на 500 Мб, на среднем железе данная операция может выполняться 5 — 10 минут и при этом, стандартный tar не выводит никакой строки прогресса, т.е. консоль как бы подвисает и только открыв top в соседнем окне можно понять что что-то происходит. Я думаю, что будет намного удобнее, если в консоли появится полоска прогресса как в том же scp и тогда пользователь будет лучше осведомлен о том, как долго ему осталось ждать до завершения операции.
Притча о шаблонах
8 min
— Здравствуй *с широко развевающейся по лицу улыбкой* дружок.
— Ваа! *с ярким блеском в широко распахнутых глазах* Тётя Ася приехала!
— Да, и у меня есть для тебя новая сказка *присела и взяла малыша за руки* хочешь послушать?
— Конечно! *слегка смутился и отвёл взгляд* Мне тут дядя такие страшные истории рассказывал…
— Ну, надеюсь моя история тебя не испугает *потрепала его по волосам* Она должна научить тебя мыслить шаблонно.
— Эээ? *лицо перекосилось от недопонимания* Это как?
— М… сейчас узнаешь *подмигнула и взяла на ручки* Вот когда тебе нужно вставить переменные в строку — ты как поступишь?
— Ну… *взял карандаш и чирканул на лежащей рядом бумажке* примерно так:
— Ты ничего не забыл? *победоносно подняла голову*
— Да вроде нет… *уткнулся носом в код, ещё раз внимательно его проверяя*
— Что, если пользователь введёт… *выдержала многозначительную паузу и добавила*
— Ваа! *с ярким блеском в широко распахнутых глазах* Тётя Ася приехала!
— Да, и у меня есть для тебя новая сказка *присела и взяла малыша за руки* хочешь послушать?
— Конечно! *слегка смутился и отвёл взгляд* Мне тут дядя такие страшные истории рассказывал…
— Ну, надеюсь моя история тебя не испугает *потрепала его по волосам* Она должна научить тебя мыслить шаблонно.
— Эээ? *лицо перекосилось от недопонимания* Это как?
— М… сейчас узнаешь *подмигнула и взяла на ручки* Вот когда тебе нужно вставить переменные в строку — ты как поступишь?
— Ну… *взял карандаш и чирканул на лежащей рядом бумажке* примерно так:
var query= 'xxx'
var resultCount= 512
var message= 'По запросу <kbd>' + query + '</kbd> найдено страниц: ' + resultCount— Ты ничего не забыл? *победоносно подняла голову*
— Да вроде нет… *уткнулся носом в код, ещё раз внимательно его проверяя*
— Что, если пользователь введёт… *выдержала многозначительную паузу и добавила*
Включение вывода лога в script/console
1 min
Мне часто не хватает вывода SQL-лога, когда я вызываю метод find у ActiveRecord-модели в консоли. Если добавить следующие строчки в файл ~/.irbrc, то прямо в консоль будет выводиться лог:
Ruby и C. Часть 1.
3 min
Ruby очень легко интегрируется с языком программирования C. Можно создавать расширения для Ruby. Или мы можем сделать обертку для библиотеки на C, и использовать ее как обычную Ruby библиотеку. Так же можно реализовать критичные вычисления на C прямо в Ruby коде! Другой вариант интеграции — это использование Ruby в C/C++ программах, в качестве скриптового языка. Например, как это сделано в Google SketchUp.
Давайте посмотрим, какие возможности Ruby представляет для интеграции с C.
Давайте посмотрим, какие возможности Ruby представляет для интеграции с C.
Выступаем публично. Подготовка к твоему первому выступлению на конференции
4 min
 Приветствую, коллеги по цеху. Начну с отказа от ответственности. Сам я не опытный рассказчик, а только учусь. Возможно, именно поэтому мой опыт будет интересен другим новичкам. Опытных презентаторов, кому есть что добавить — прошу отписаться в комментах или в личку — что можно было бы сделать лучше.
Приветствую, коллеги по цеху. Начну с отказа от ответственности. Сам я не опытный рассказчик, а только учусь. Возможно, именно поэтому мой опыт будет интересен другим новичкам. Опытных презентаторов, кому есть что добавить — прошу отписаться в комментах или в личку — что можно было бы сделать лучше.Началось всё с того, что на РИФ+КИБ нашей компании выступить не удалось, в силу разных причин, а давно хотелось. Следующее интересное отраслевое событие — "Неделя электронной торговли", и наши доклады включили в программу мероприятия (не без помощи razmolot).
Начитавшись на Хабре статей (раз, два, три и т.д.), начал готовиться к первому своему публичному выступлению.
Итак. Первое: Цели. Как правильно писали умные люди на Хабре — презентация это не "о чем", а "зачем".
Arduino: первое знакомство
4 min
Месяц назад я заказала себе игрушку по имени Arduino. Это набор «кубиков», из которых без паяльника, травления печатных плат и прочей «черной магии» любой чайник может собрать работающее устройство. В общем, это такой конструктор как для профессионального прототипирования так и для разнообразных любительских экспериментов.
Через месяц после заказа ко мне пришла посылка с Arduino, точнее, ее вариацией — Seeeduino. Вот, что в ней было:

Через месяц после заказа ко мне пришла посылка с Arduino, точнее, ее вариацией — Seeeduino. Вот, что в ней было: