
Добрый день, дорогие читатели!
В прошлых статьях я в общих чертах рассказывал про наше открытое отказоустойчивое хранилище Elliptics, а также немного опускался в детали. Сегодня же я вам наглядно расскажу и покажу, как использовать Elliptics на примере создания своей собственной отказоустойчивой ХабраМузыки.

ХабраМузыка – это ваше личное хранилище музыки с поддержкой региональности, реплицирования данных, минимальной нагрузкой на диск и сеть, а также простым HTTP API, который можно использовать в любом вашем приложении или на личном сайте.
Под катом — пошаговые подробности.
В прошлых статьях я в общих чертах рассказывал про наше открытое отказоустойчивое хранилище Elliptics, а также немного опускался в детали. Сегодня же я вам наглядно расскажу и покажу, как использовать Elliptics на примере создания своей собственной отказоустойчивой ХабраМузыки.
ХабраМузыка – это ваше личное хранилище музыки с поддержкой региональности, реплицирования данных, минимальной нагрузкой на диск и сеть, а также простым HTTP API, который можно использовать в любом вашем приложении или на личном сайте.
Под катом — пошаговые подробности.

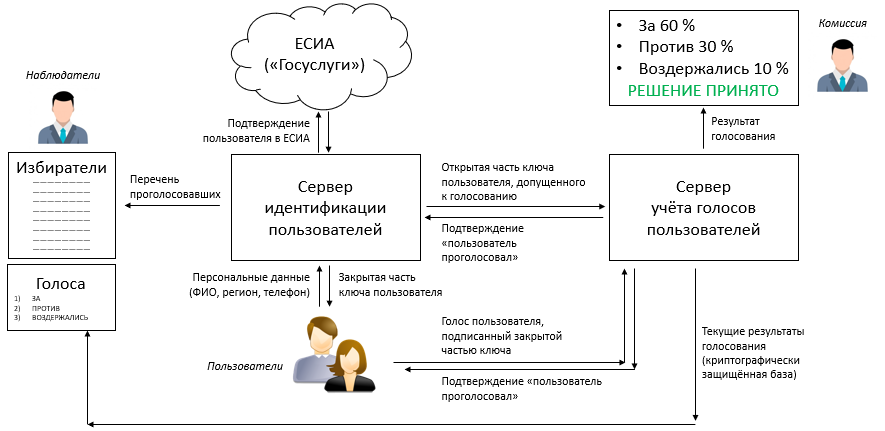







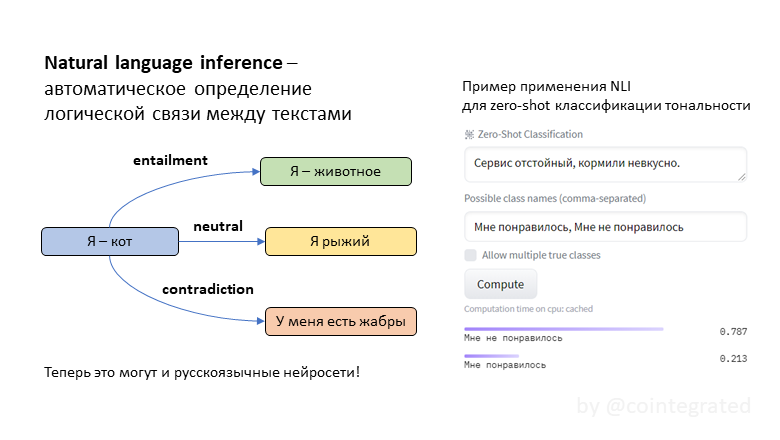

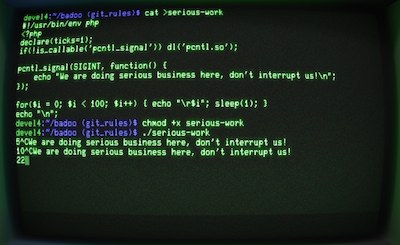 Для большинства специалистов PHP не является языком, который бы всерьёз использовался для написания консольных утилит, и для этого есть много причин. PHP изначально разрабатывался как язык для создания веб-сайтов, но, начиная с PHP 4.3, в 2002-ом году появилась
Для большинства специалистов PHP не является языком, который бы всерьёз использовался для написания консольных утилит, и для этого есть много причин. PHP изначально разрабатывался как язык для создания веб-сайтов, но, начиная с PHP 4.3, в 2002-ом году появилась 



