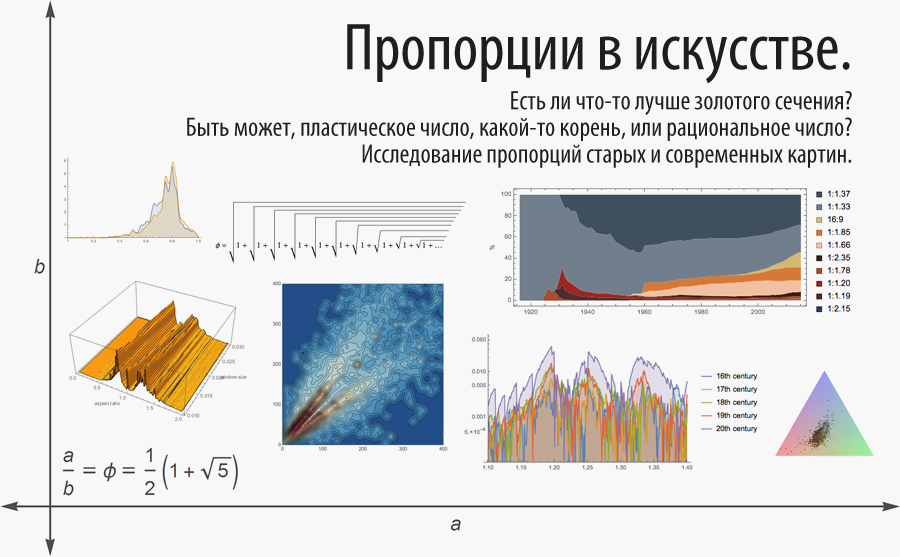
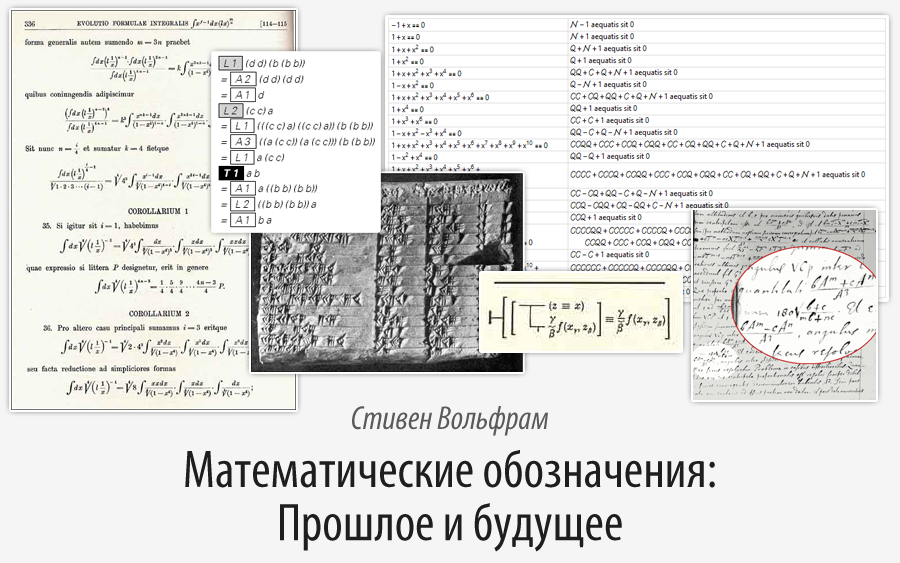
Перевод поста Стивена Вольфрама (Stephen Wolfram) "Mathematical Notation: Past and Future (2000)".
Выражаю огромную благодарность Кириллу Гузенко KirillGuzenko за помощь в переводе и подготовке публикации
Содержание
Резюме
Введение
История
Компьютеры
Будущее
Примечания
—
Эмпирические законы для математических обозначений
—
Печатные обозначения против экранных
—
Письменные обозначения
—
Шрифты и символы
—
Поиск математических формул
—
Невизуальные обозначения
—
Доказательства
—
Отбор символов
—
Частотное распределение символов
—
Части речи в математической нотации
Стенограмма речи, представленной на секции «MathML и математика в сети» первой Международной Конференции MathML в 2000-м году.
Резюме
Большинство математических обозначений существуют уже более пятисот лет. Я рассмотрю, как они разрабатывались, что было в античные и средневековые времена, какие обозначения вводили Лейбниц, Эйлер, Пеано и другие, как они получили распространение в 19 и 20 веках. Будет рассмотрен вопрос о схожести математических обозначений с тем, что объединяет обычные человеческие языки. Я расскажу об основных принципах, которые были обнаружены для обычных человеческих языков, какие из них применяются в математических обозначениях и какие нет.
Согласно историческим тенденциям, математическая нотация, как и естественный язык, могла бы оказаться невероятно сложной для понимания компьютером. Но за последние пять лет мы внедрили в
Mathematica возможности к пониманию чего-то очень близкого к стандартной математической нотации. Я расскажу о ключевых идеях, которые сделали это возможным, а также о тех особенностях в математических обозначениях, которые мы попутно обнаружили.
Большие математические выражения — в отличии от фрагментов обычного текста — часто представляют собой результаты вычислений и создаются автоматически. Я расскажу об обработке подобных выражений и о том, что мы предприняли для того, чтобы сделать их более понятными для людей.
Традиционная математическая нотация представляет математические объекты, а не математические процессы. Я расскажу о попытках разработать нотацию для алгоритмов, об опыте реализации этого в APL, Mathematica, в программах для автоматических доказательств и других системах.
Обычный язык состоит их строк текста; математическая нотация часто также содержит двумерные структуры. Будет обсуждён вопрос о применении в математической нотации более общих структур и как они соотносятся с пределом познавательных возможностей людей.
Сфера приложения конкретного естественного языка обычно ограничивает сферу мышления тех, кто его использует. Я рассмотрю то, как традиционная математическая нотация ограничивает возможности математики, а также то, на что могут быть похожи обобщения математики.










 Исследуя одну задачу оптимизации, столкнулся с проблемой симметричности конфигураций при прямом переборе вариантов. Схожая проблема возникает в некоторых решениях задачи о восьми ферзях. Исследуя центральную симметрию прямоугольной сетки, я обнаружил
Исследуя одну задачу оптимизации, столкнулся с проблемой симметричности конфигураций при прямом переборе вариантов. Схожая проблема возникает в некоторых решениях задачи о восьми ферзях. Исследуя центральную симметрию прямоугольной сетки, я обнаружил