В этой статье я опишу принципиальные различия Apache и Nginx, архитектуру фронтэнд-бэкэнд, установку Apache в качестве бэкэнда и Nginx в качестве фронтэнда. А также опишу технологию, позволяющую ускорить работу веб-сервера: gzip_static+yuicompressor.

Виктор Павлович Гришко @Yeah
Пользователь
Разворачивание широкой таблицы в столбец (EAV pattern)
3 min
Задача
Есть сущность, которая характеризуется огромным и часто переменным числом параметров. Задача хранить эти сущности да еще и так чтоб поиск тоже можно было вести желательно еще и с построением индекса.
Примеси VS делегирование: преимущества и недостатки при реализации «плагинов»
5 min
В данной статье я предлагаю вам свой взгляд на выбор использования примесей или делегирования в проектах для добавления в класс нового функционала.
Начальные условия такие: мы рассматриваем примеси, имеющие свое состояние и имеющие доступ ко всем членам класса-агрегатора. Все публичные члены класса примеси становятся частью агрегатора. Мы оставляем за кадром вопрос быстродействия. Вопрос исследуем на примере добавления нового функционала в модель выдуманного ORM.
В основном данная статья относится к PHP, но с некоторыми оговорками подходит и для многих других динамических языков, позволяющих тем или иным способом реализовывать примеси.
Начальные условия такие: мы рассматриваем примеси, имеющие свое состояние и имеющие доступ ко всем членам класса-агрегатора. Все публичные члены класса примеси становятся частью агрегатора. Мы оставляем за кадром вопрос быстродействия. Вопрос исследуем на примере добавления нового функционала в модель выдуманного ORM.
В основном данная статья относится к PHP, но с некоторыми оговорками подходит и для многих других динамических языков, позволяющих тем или иным способом реализовывать примеси.
Эволюция юнит-теста
5 min
Много слов сказано о том, как правильно писать юнит-тесты, и вообще о пользе TDD. Потом ещё и какое-то BDD замаячило на горизонте. Приходится разбираться, что из них лучше и между ними какая разница. Может, это и есть причина, почему большинство разработчиков решили не заморачиваться и до сих пор не используют ни того, ни другого?
Коротко: BDD — это дальнейшее развитие идей TDD, стало быть, его и надо использовать. А разницу между TDD и BDD я попробую объяснить на простом примере.
Рассмотрим 3 ревизии одного юнит-теста, который я нашёл в одном реальном проекте.
Первая версия этого юнит-теста была такой:
Коротко: BDD — это дальнейшее развитие идей TDD, стало быть, его и надо использовать. А разницу между TDD и BDD я попробую объяснить на простом примере.
Рассмотрим 3 ревизии одного юнит-теста, который я нашёл в одном реальном проекте.
Попытка номер №1
Первая версия этого юнит-теста была такой:
«Spirit»: Node.js MVC Framework
13 min

Привет, ребята! С этого момента я хочу начать цикл статтей с подробностями по созданию сообственного MVC фреймворка для
node.js, название которому будет — Spirit.Первая статья будет состять из четырех частей:
1. Идея и миссия фреймворка
2. Настройка сервера
3. Создание каркаса фреймворка
4. Создание продвинутого и удобного роутера
Предупреждаю сразу, что статья — огромна, с кучей текста и большими блоками кода.
Грабли при верстке HTML писем
3 min
Довольно часто наши клиенты устраивают регулярные рассылки с новостями. Почти всегда их не устраивают текстовые рассылки или простое оформление HTML рассылок. Наши дизайнеры вовсю креативят, а мы потом набиваем шишки при верстке их макетов с корректным отображением во множестве почтовых клиентов.
Ниже список встретившихся нам особенностей и способы их разрешения (как то упорядочить их мне не удалось, поэтому всё идет единым списком)
Ниже список встретившихся нам особенностей и способы их разрешения (как то упорядочить их мне не удалось, поэтому всё идет единым списком)
Когда не нужна тригонометрия
4 min
Просматривая различный код по выводу на экран какой-нибудь даже примитивной графики, я заметил чрезмерную любовь некоторых программистов к тригонометрии. Часто код пестрит синусами, косинусами и арктангенсами там, где без них можно обойтись. Этим грешат даже хорошие программисты, которые способны спроектировать сложную систему, но почему-то не освоили вектора в объёме школьной программы. Буквально азов векторной алгебры хватает для решения многих насущных проблем. В этом топике я хочу провести краткий ликбез, напомнить основные действия с векторами на плоскости и в качестве примера решить две задачи без тригонометрии: поиск отражённого луча по падающему лучу и произвольно расположенному зеркалу, а также рисование наконечника стрелки. Если вы можете представить в голове рисование произвольно направленной стрелки без синусов и косинусов, смело пропускайте этот топик. Для остальных постараюсь объяснять попроще.
Система непересекающихся множеств и её применения
10 min
Добрый день, Хабрахабр. Это еще один пост в рамках моей программы по обогащению базы данных крупнейшего IT-ресурса информацией по алгоритмам и структурам данных. Как показывает практика, этой информации многим не хватает, а необходимость встречается в самых разнообразных сферах программистской жизни.
Я продолжаю преимущественно выбирать те алгоритмы/структуры, которые легко понимаются и для которых не требуется много кода — а вот практическое значение сложно недооценить. В прошлый раз это было декартово дерево. В этот раз — система непересекающихся множеств. Она же известна под названиями disjoint set union (DSU) или Union-Find.
Поставим перед собой следующую задачу. Пускай мы оперируем элементами N видов (для простоты, здесь и далее — числами от 0 до N-1). Некоторые группы чисел объединены в множества. Также мы можем добавить в структуру новый элемент, он тем самым образует множество размера 1 из самого себя. И наконец, периодически некоторые два множества нам потребуется сливать в одно.
Формализируем задачу: создать быструю структуру, которая поддерживает следующие операции:
MakeSet(X) — внести в структуру новый элемент X, создать для него множество размера 1 из самого себя.
Find(X) — возвратить идентификатор множества, которому принадлежит элемент X. В качестве идентификатора мы будем выбирать один элемент из этого множества — представителя множества. Гарантируется, что для одного и того же множества представитель будет возвращаться один и тот же, иначе невозможно будет работать со структурой: не будет корректной даже проверка принадлежности двух элементов одному множеству
Unite(X, Y) — объединить два множества, в которых лежат элементы X и Y, в одно новое.
На рисунке я продемонстрирую работу такой гипотетической структуры.
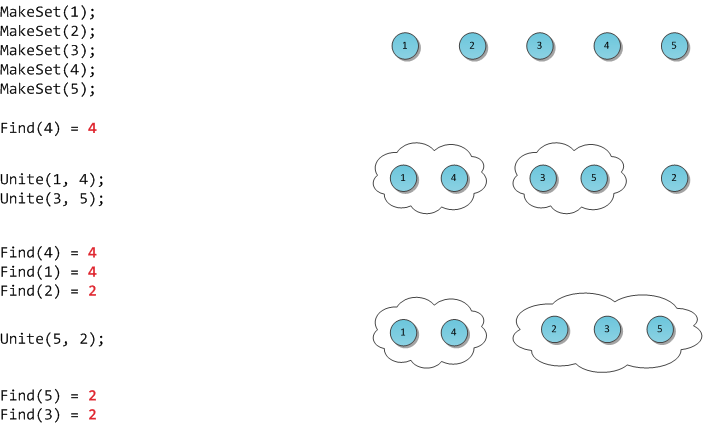
Я продолжаю преимущественно выбирать те алгоритмы/структуры, которые легко понимаются и для которых не требуется много кода — а вот практическое значение сложно недооценить. В прошлый раз это было декартово дерево. В этот раз — система непересекающихся множеств. Она же известна под названиями disjoint set union (DSU) или Union-Find.
Условие
Поставим перед собой следующую задачу. Пускай мы оперируем элементами N видов (для простоты, здесь и далее — числами от 0 до N-1). Некоторые группы чисел объединены в множества. Также мы можем добавить в структуру новый элемент, он тем самым образует множество размера 1 из самого себя. И наконец, периодически некоторые два множества нам потребуется сливать в одно.
Формализируем задачу: создать быструю структуру, которая поддерживает следующие операции:
MakeSet(X) — внести в структуру новый элемент X, создать для него множество размера 1 из самого себя.
Find(X) — возвратить идентификатор множества, которому принадлежит элемент X. В качестве идентификатора мы будем выбирать один элемент из этого множества — представителя множества. Гарантируется, что для одного и того же множества представитель будет возвращаться один и тот же, иначе невозможно будет работать со структурой: не будет корректной даже проверка принадлежности двух элементов одному множеству
if (Find(X) == Find(Y)).Unite(X, Y) — объединить два множества, в которых лежат элементы X и Y, в одно новое.
На рисунке я продемонстрирую работу такой гипотетической структуры.
MapReduce: более продвинутые примеры, попробуем без зауми
9 min
Чтобы не откладывать в долгий ящик сразу порассказываю несколько других примеров для MapReduce, обещанные в топике "MapReduce без зауми". (Если не понимаете полностью что такое MapReduce — прочитайте тот топик сначала! Без него не разберетесь)
Поговорим тут о подсчетах национальностей в городах, средних оценках и приводах учеников, ТИЦ, PageRank, входящих ссылках, нишевых ключевых словах, словах-синонимах, социальных сетях и общих друзьях. Постараемся обойтись без математических знаков и зауми.
Однако тема сама по себе сложная и все же напрячь мозги придется. Когда поймете — будет очень просто.
Допустим у нас есть Интернет. В Интернете есть исходящие ссылки.
Допустим на входе у нас есть такие данные об ИСХОДЯЩИХ ссылках, собранные нашим паучком:
Т.е. мы знаем, что Хабр ссылается на Apple, MS, Ubuntu и Яндекс но кто ссылается на Хабр? Да, вопрос примитивный, но все же разложим на MapReduce. Дальше будет интереснее и этот пример понадобится.
Поговорим тут о подсчетах национальностей в городах, средних оценках и приводах учеников, ТИЦ, PageRank, входящих ссылках, нишевых ключевых словах, словах-синонимах, социальных сетях и общих друзьях. Постараемся обойтись без математических знаков и зауми.
Однако тема сама по себе сложная и все же напрячь мозги придется. Когда поймете — будет очень просто.
Входящие ссылки
Допустим у нас есть Интернет. В Интернете есть исходящие ссылки.
Допустим на входе у нас есть такие данные об ИСХОДЯЩИХ ссылках, собранные нашим паучком:
habrahabr.ru -> thematicmedia.ru, apple.ru, microsoft.com, ubuntu.com, yandex.ru
thematicmedia.ru -> habrahabr.ru, autokadabra.ru
autokadabra.ru -> habrahabr.ru, yandex.ruТ.е. мы знаем, что Хабр ссылается на Apple, MS, Ubuntu и Яндекс но кто ссылается на Хабр? Да, вопрос примитивный, но все же разложим на MapReduce. Дальше будет интереснее и этот пример понадобится.
MapReduce или подсчеты за пределами возможностей памяти и процессора (попробую без зауми)
8 min
Давно хотел рассказать про MapReduce, а то как ни взгляшешь на подобное — такая заумь, что просто ужас берет, а на самом деле очень простой и полезный подход для многих целей. И реализовать самому — не так уж и сложно.
Сразу скажу — топик — для тех, кто не разобрался что такое MapReduce. Для тех, кто разобрался — полезного тут ничего не будет.
Начнем с того как собственно родилась лично у меня идея MapReduce (хотя я и не знал, что он так называется, и, разумеется, пришла она мне куда позже чем Гугловсцам).
Сначала опишу как она рождалась (подход был неправильный), а потом как надо правильно делать.
А родилась она, как и, наверное, везде — для подсчета частоты слов, когда обычной памяти не хватает (подсчет частоты всех слов в Википедии). Вместо слова «частота» тут скорее должно быть «количество вхождений», но для простоты оставлю «частота».
В самом простом случае мы можем завести хеш (dict, map, hash, ассоциативный массив, array() в PHP) и считать в нем слова.
Но что делать когда память под хеш кончится, а мы посчитали только одну сотую всех слов?
Сразу скажу — топик — для тех, кто не разобрался что такое MapReduce. Для тех, кто разобрался — полезного тут ничего не будет.
Начнем с того как собственно родилась лично у меня идея MapReduce (хотя я и не знал, что он так называется, и, разумеется, пришла она мне куда позже чем Гугловсцам).
Сначала опишу как она рождалась (подход был неправильный), а потом как надо правильно делать.
Как посчитать все слова в Википедии (неправильный подход)
А родилась она, как и, наверное, везде — для подсчета частоты слов, когда обычной памяти не хватает (подсчет частоты всех слов в Википедии). Вместо слова «частота» тут скорее должно быть «количество вхождений», но для простоты оставлю «частота».
В самом простом случае мы можем завести хеш (dict, map, hash, ассоциативный массив, array() в PHP) и считать в нем слова.
$dict['word1'] += 1Но что делать когда память под хеш кончится, а мы посчитали только одну сотую всех слов?
Требования к html-верстке
6 min
1. Верстка, аутсорсинг и технические задания
 Верстка — относительно независимый этап веб-разработки и, к примеру, в маленьких веб-студиях часто — это первый кандидат на аутсорсинг в условиях ограниченных трудовых ресурсов.
Верстка — относительно независимый этап веб-разработки и, к примеру, в маленьких веб-студиях часто — это первый кандидат на аутсорсинг в условиях ограниченных трудовых ресурсов.Так сложилось, что мне часто приходилось отдавать эту работу субподрядчикам и, несмотря на предполагаемую однозначность результата, иногда верстальщики меня очень удивляли. Причем чаще — в негативном смысле.
Чтобы сэкономить трудовые ресурсы штатных верстальщиков, недостаточно просто переложить эту работу на плечи первого приглянувшегося фрилансера. Все намного проще, если вы постоянно отдаете работу на аутсорсинг одним и тем же исполнителям — в процессе длительного сотрудничества всегда складывается какой-то негласный свод стандартов и требований, выполнение которых входит в привычку. Но если вы работаете с человеком впервые — самое хорошее портфолио и рекомендации не гарантируют получения нужного результата и более того — даже не предполагают, что исполнитель вообще вас правильно поймет. Потому нужны детальные технические задания по верстке.
Правильная обработка ошибок в PHP
7 min
Что я понимаю под правильной обработкой:
- Универсальное решение, которое можно вставить в любой существующий код;
- Легко расширяемое решение;
- В PHP аж три «механизма ошибок»: собственно ошибки (error), исключения (exception) и утверждения (assertion). Свести три механизма к одному — exception. В комментариях к предыдущей статье на эту тему выражалось мнение, что exception это плохой и/или сложный метод обработки ошибок. Я так не считаю и готов это обсудить в комментариях;
- Опциональное логирование;
- Общий обработчик exception, который будет поддерживать разные форматы вывода и debug/production режимы;
- В debug режиме должен выводится trace. Требования к trace: компактный, понятный и по возможности ссылки на открытие файлов в IDE.
К вопросу о кроссбраузерном использовании SVG
14 min
Для векторной графики в Интернете формат SVG — самое то. Во-первых, он поддерживает масштабирование любой степени. Во-вторых, можно обращаться к любым составляющим элементам такой картинки — адресовать их, стилизовать и скриптовать. В-третьих, за исключением совсем маленьких файлов, этот формат выигрывает по компактности перед любыми растровыми представлениями, особенно если применить gzip-сжатие. В-четвёртых, сие есть стандарт W3C.
Но как поместить SVG-картинку в HTML-документ?
Но как поместить SVG-картинку в HTML-документ?
Как использовать свой тип контента
8 min
 В Wordpress есть два типа контента: Посты и Страницы.
В Wordpress есть два типа контента: Посты и Страницы. Эти типы содержат такие поля как название, описание, категории/тэги.
Дополнительное описание можно создать с помощью Пользовательских Полей (Custom Fields).
В Wordpress 3.0 появилась возможность создавать свой тип контента.
Идея в том, чтоб создать новый тип контента, например Потфолио (название, описание, адрес сайта, дата релиза, имя заказчика, используемые технологии), который бы не выводился вместе с постами и имел бы другое представление.

Разметка независимыми элементами
3 min
Развивая идею вёрстки независимыми блоками мы постепенно придём к вёрстке независимыми модулями, а пока остановимся подробней на сабже…
Но сперва небольшое терминологическое отступление.
Вёрстка страницы — процесс расположения элементов на странице в соответствии с дизайном.
Вёрстка бывает:
Но сперва небольшое терминологическое отступление.
Вёрстка страницы — процесс расположения элементов на странице в соответствии с дизайном.
Вёрстка бывает:
- Табличная. Страница представляет из себя одну большую таблицу с мелкими ячейками. Каждый элемент занимает несколько смежных ячеек образующих прямоугольную, не пересекающуюся с остальными, область.
- Блочная. Страница делится на крупные блоки, те на более мелкие, и так далее до нужной степени детализации.
- Слоёная. Элементы позиционируются абсолютно, независимо от расположения остальных элементов.
US Virtual Bank Account, или как вывести деньги с зарубежных платежных систем
6 min
Преамбула.
В связи с бурным развитием мобильных устройств и ОС Google Android в частности, интерес к разработке программного обеспечения под данную платформу весьма закономерное явление. Как оказалось, он мало чем отличается от обычной разработки на Яве под десктоп/веб, а с учетом возможности использования «стандартного» IDE (Eclipse) путем скачки и встраивания SDK Андроида, а также наличия исчерпывающей документации многие технические вопросы снимаются сами собой. Концептуальный аспект (т.е. идея для реализации в виде ПО) также не заставила себя ждать, благо платформа сравнительно новая, не смотря на недавно вышедшую уже версию 2.1, и конкурентная среда соответственно не такая насыщенная, если взять, к примеру, разработку под тот же iPhone. (Тут могла бы быть развернутая часть о самом ПО, но ввиду некоторых нюансов, таких как незаконченность проекта и отсутствие конкретных результатов, пока ее пропустим).
Оставался последний, и, естественно, самый интересный (логично, не правда ли?) вопрос – денежный, а конкретно – как правильно вывести честно заработанные дензнаки, полученные от продажи ПО на Android Market.

Вдаваться подробности не буду, все-таки статья ориентирована на тех, кто примерно ориентируется в данной теме, скажу коротко — в данном случае под прицелом оказывается сервис обработки онлайновых платежей Google Checkout, который с нерезидентами США изначально не работает. Насколько мне известно, прямых путей решения данной проблемы нет, поэтому пришлось искать обходные дорожки.
Мета-данные. На пути к идеалам управления моделями данных
6 min
О чём этот пост
- Это пост-обзор вариантов управления моделями данных, известных автору, на основе опыта, слухов, и чтения инструкций
- Также этот пост — попытка классификации существующих вариантов управления моделями данных
- Напоследок приводится идея и начальные штрихи в реализации системы управления моделями данных, которая не должна содержать недостатков предыдущих
Определения и ограничения
Предполагается, что читатель является (или когда-нибудь станет) разработчиком Enterprise Application, которому часто нужно писать быстро и качественно, но не боящегося лезть в дебри JPA/JTA/RMI чтобы «подкрутить напильником» особо тонкие места.
Данные — то, что хранится в базе данных приложения. Данные о клиентах, пользователях, заказах и т.п.
Метаданные — описание структуры данных. Описание того, какие типы объектов хранятся в базе данных, какие у них есть поля (аттрибуты, элементы), описание зависимостей между объектами. В общем случает типы могут наследовать атрибуты родительского типа, а один атрибут в общем случае может присутствовать у двух и более типов, несвязанных отношением наследования.
Chain Friends by MongoDB
2 min
 Про MongoDb было рассказано не так много, но относительно полно, например здесь. Хочу поделиться еще с одним практическим использованием этой БД — это построение цепочек друзей. Построение цепочек и концепцию кругов было использовано в Мойм Круге. Вот пример: Я — Иван Петров — Петр-Иванов — Киририлл Лавров — Вася Пупкин.
Про MongoDb было рассказано не так много, но относительно полно, например здесь. Хочу поделиться еще с одним практическим использованием этой БД — это построение цепочек друзей. Построение цепочек и концепцию кругов было использовано в Мойм Круге. Вот пример: Я — Иван Петров — Петр-Иванов — Киририлл Лавров — Вася Пупкин. MongoDb было выбрано как высокопроизводительное хранилище данных, позволяющее быстро извлекать массивы структур данных. Традиционные key/value DB для этого не подходят, почему — поймете по ходу изложения статьи.
В данной статье рассмотрен опыт использования noSQL DB при построение «цепочек друзей» в небольшой соц-сети 300 тыс пользователей.
CSS-Expressions on DOMReady (CSS+JS в одном файле)
3 min
Вероятно, многие из вас используя css-expressions сталкивались с проблемой периодического появления сообщения abort. В народе поговаривают, что связано это с изменением DOM-дерева до его готовности.
Я тоже сталкивался и, не долго думая, решил написать небольшую «обертку» для expression’ов, которые я часто использую, учитывающую готовность DOM, упакованную в файл стилей.
Оную вашему вниманию и представляю.
Я тоже сталкивался и, не долго думая, решил написать небольшую «обертку» для expression’ов, которые я часто использую, учитывающую готовность DOM, упакованную в файл стилей.
Оную вашему вниманию и представляю.
PHPUnit. Автоматические тесты
4 min
Translation
Предисловие переводчика:
Недавно начал изучать PHPUnit (framework семейства xUnit) и с удивлением обнаружил, что на русском языке нет статей про автоматические тесты для самых-самых чайников.
В первой главе документации по PHPUnit на примерах очень доступно рассказывается, что такое автоматическое тестирование.
Даже хорошие программисты допускают ошибки. Разница между хорошим программистом и плохим заключается в том, что хороший программист как можно чаще использует тесты, чтобы найти свои ошибки.
Чем раньше Вы начнете тестировать, тем выше Ваши шансы найти ошибку, и тем ниже цена исправления.
Это объясняет, почему откладывание тестирования до момента передачи программы заказчику является очень плохой практикой. Большинство ошибок так и не будет найдено, а цена исправления станет такой высокой, что Вам придется составить большой график работы, т.к. сразу Вы не сможете их все исправить.
Недавно начал изучать PHPUnit (framework семейства xUnit) и с удивлением обнаружил, что на русском языке нет статей про автоматические тесты для самых-самых чайников.
В первой главе документации по PHPUnit на примерах очень доступно рассказывается, что такое автоматическое тестирование.
Даже хорошие программисты допускают ошибки. Разница между хорошим программистом и плохим заключается в том, что хороший программист как можно чаще использует тесты, чтобы найти свои ошибки.
Чем раньше Вы начнете тестировать, тем выше Ваши шансы найти ошибку, и тем ниже цена исправления.
Это объясняет, почему откладывание тестирования до момента передачи программы заказчику является очень плохой практикой. Большинство ошибок так и не будет найдено, а цена исправления станет такой высокой, что Вам придется составить большой график работы, т.к. сразу Вы не сможете их все исправить.