Постановка задачи поиска в строке
Часто приходится сталкиваться со специфическим поиском, так называемым поиском строки (поиском в строке). Пусть есть некоторый текст Т и слово (или образ) W. Необходимо найти первое вхождение этого слова в указанном тексте. Это действие типично для любых систем обработки текстов. (Элементы массивов Т и W – символы некоторого конечного алфавита – например, {0, 1}, или {a, …, z}, или {а, …, я}.)
Наиболее типичным приложением такой задачи является документальный поиск: задан фонд документов, состоящих из последовательности библиографических ссылок, каждая ссылка сопровождается «дескриптором», указывающим тему соответствующей ссылки. Надо найти некоторые ключевые слова, встречающиеся среди дескрипторов. Мог бы иметь место, например, запрос «Программирование» и «Java». Такой запрос можно трактовать следующим образом: существуют ли статьи, обладающие дескрипторами «Программирование» и «Java».
Поиск строки формально определяется следующим образом. Пусть задан массив Т из N элементов и массив W из M элементов, причем 0<M≤N. Поиск строки обнаруживает первое вхождение W в Т, результатом будем считать индекс i, указывающий на первое с начала строки (с начала массива Т) совпадение с образом (словом).
Пример. Требуется найти все вхождения образца W = abaa в текст T=abcabaabcabca.

Образец входит в текст только один раз, со сдвигом S=3, индекс i=4.


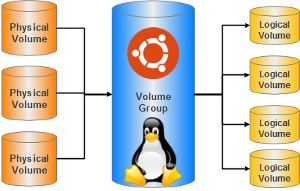 Классические разделы, на которые чаще всего разбивается жёсткий диск для установки системы и хранения данных, имею ряд существенных недостатков. Их размер очень сложно изменять, они находятся в строгой последовательности и просто взять кусочек от первого раздела и добавить к последнему не получится, если между ними есть ещё разделы. Поэтому очень часто при начальном разбиении винчестера пользователи ломают себе голову — сколько места выделить под тот или иной раздел. И почти всегда в процессе использования системы приходят к выводу, что они сделали не правильный выбор.
Классические разделы, на которые чаще всего разбивается жёсткий диск для установки системы и хранения данных, имею ряд существенных недостатков. Их размер очень сложно изменять, они находятся в строгой последовательности и просто взять кусочек от первого раздела и добавить к последнему не получится, если между ними есть ещё разделы. Поэтому очень часто при начальном разбиении винчестера пользователи ломают себе голову — сколько места выделить под тот или иной раздел. И почти всегда в процессе использования системы приходят к выводу, что они сделали не правильный выбор.

 Здравствуйте, хабражители. Думаю, многие из вас слышали о программируемых калькуляторах (а некоторые даже использовали их). Как ни странно, здесь я не нашел ни одной статьи, рассказывающей о такой интересной вещи, и поэтому решил восполнить этот пробел и рассказать об основах программирования на калькуляторах.
Здравствуйте, хабражители. Думаю, многие из вас слышали о программируемых калькуляторах (а некоторые даже использовали их). Как ни странно, здесь я не нашел ни одной статьи, рассказывающей о такой интересной вещи, и поэтому решил восполнить этот пробел и рассказать об основах программирования на калькуляторах.


