Как мыслить и действовать адекватно ситуации, избавиться от инфантилизма и не наступать на одни и те же "грабли"? Эта статья может стать отправной точкой для получения навыков усвоения материала почти любой сложности.
Общая семантика включает в себя метод, помогающий достигать надлежащих оценочных реакций, что способствует психическому здоровью. Ее основы заложил А. Коржибски и определил ее как общую теорию оценки фактов, отношений ощущений и т.д. с точки зрения того, как действительно происходят оценочные реакции.
Аристотель уникален тем, что его последователи поклонялись не только его лучшим качествам, но также и его недостаткам, чего он никогда не делал в отношении кого-либо, живого или мертвого; за что и был не раз он порицаем – за непоклонение. Огастес де Морган - "наука и здравомыслие" А. Коржибски.
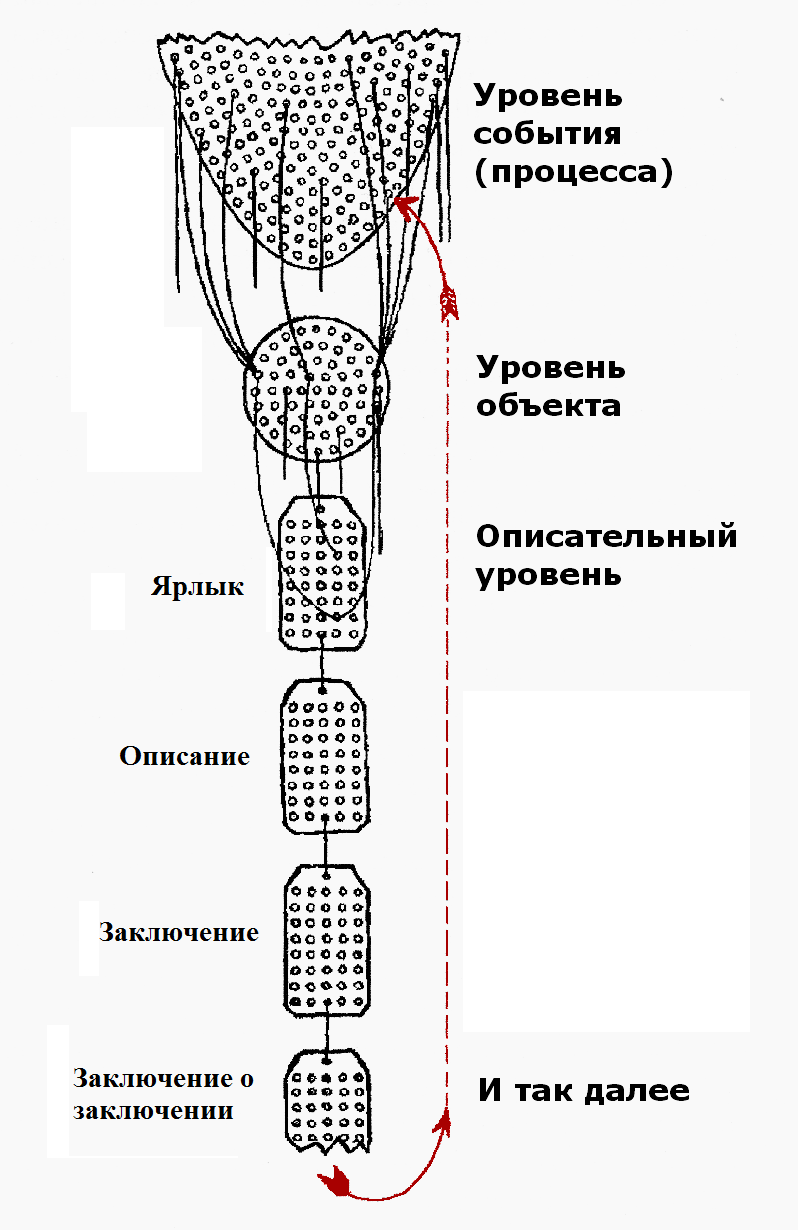
В 1933 году польский математик по имени Альфред Коржибски издал книгу "наука и здравомыслие", а в 1938 году основал институт общей семантики в США. В основе его концепции лежит утверждение о том, что любое человеческое познание ограничивается структурой нервной системы и структурой языка. Это значит, что человек априори не может знать всё обо всём. Коржибски проанализировал структуру языков индоевропейской группы математическими методами и выявил фундаментальные основы логики языка, которым люди пользуются изо дня в день, скрытые в неопределяемых и многопорядковых терминах (принимающие значение только при наличии контекста). Через них показана метафизика лежащая в основе используемого нами языка, его несовершенство, некоторое несоответствие действительности (например, может использоваться одно слово для нескольких сущностей одновременно, что может способствовать неверной оценке и неэффективному поведению (об этом позже)). Для преодоления этого барьера Коржибски ввел в ОС (общая семантика) в обиход не-элементалистский (позже станет понятно что это значит) термин семантической реакции - психологическая реакция индивидуума на слова, язык и другие символы и события в связи с их смыслом, и психологические реакции, которые становятся смыслами и конфигурациями отношений в тот момент, когда индивидуум начинает анализировать их, или кто-то другой делает это за него. Так же разработал простое и наглядное средство для обучения новым, более адекватным семантическим реакциям - структурный дифференциал. Данный подход предлагаю начать с изложения о понятии механизма времясвязывания.