
Определяем пользователей VPN (и их настройки!) и прокси со стороны сайта
6 min

We can save the day from dark, from bad
There's no one we need
Многие из вас используют VPN или прокси в повседневной жизни. Кто-то использует его постоянно, получая доступ к заблокированным на государственном или корпоративном уровне ресурсам, многие используют его изредка, для обхода ограничений по географическому положению. Как вы можете знать, крупные интернет-игроки в сфере стриминга видео, музыки и продажи игр никогда не любили пользователей, которые легко обходят географические ограничения, разблокируя недоступный в их стране контент, или совершая покупки заметно дешевле. За примерами не нужно далеко ходить: Netflix изменил свое соглашение об использовании, добавив пункт о блокировке VPN, всего 2 месяца назад; Hulu тоже грешил блокировкой пользователей, а Steam вообще подозрительно смотрит на не-русскоязычных пользователей из России. В последнее время, компании пытаются блокировать уже не конкретных пользователей, а сами IP-адреса VPN-сервисов, создавая определенные неудобства уже самому VPN-сервису и его пользователям. Похоже, они не используют никаких спецсредств, а блокируют выборочно и вручную. Хоть я и не поддерживаю какие-либо блокировки вообще, меня заинтересовала техническая часть вопроса: можно ли как-то определить использование прокси-серверов и VPN со стороны сервера, не прикладывая особых усилий?
Можно, при определенных условиях. И достаточно точно.

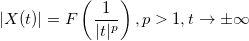 ,
,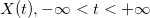 , удовлетворяет условию:
, удовлетворяет условию: 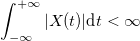
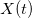 как временной процесс. Существует частотная область, в которой функция — сумма составляющих, имеющих определенную частоту. Функция
как временной процесс. Существует частотная область, в которой функция — сумма составляющих, имеющих определенную частоту. Функция 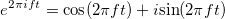 .
.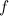 имеет вид:
имеет вид: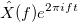 , где
, где 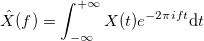 .
.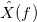 называется преобразованием Фурье.
называется преобразованием Фурье.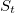 . Рассчитаем логарифмические отношения:
. Рассчитаем логарифмические отношения: 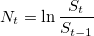
 на
на 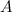 смежных периодов длиной
смежных периодов длиной 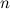 . Отметим каждый период как
. Отметим каждый период как 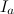 , где
, где 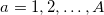 . Определим для каждого
. Определим для каждого 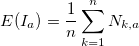




 Благодаря кодам Рида-Соломона можно прочитать компакт-диск с множеством царапин, либо передать информацию в условиях связи с большим количеством помех. В среднем для компакт-диска избыточность кода (т.е. количество дополнительных символов, благодаря которым информацию можно восстанавливать) составляет примерно 25%. Восстановить при этом можно количество данных, равное половине избыточных. Если емкость диска 700 Мб, то, получается, теоретически можно восстановить до 87,5 Мб из 700. При этом нам не обязательно знать, какой именно символ передан с ошибкой. Также стоит отметить, что вместе с кодированием используется перемежевание, когда байты разных блоков перемешиваются в определенном порядке, что в результате позволяет читать диски с обширными повреждениями, локализированными близко друг к другу (например, глубокие царапины), так как после операции, обратной перемежеванию, обширное повреждение оборачивается единичными ошибками во множестве блоков кода, которые поддаются восстановлению.
Благодаря кодам Рида-Соломона можно прочитать компакт-диск с множеством царапин, либо передать информацию в условиях связи с большим количеством помех. В среднем для компакт-диска избыточность кода (т.е. количество дополнительных символов, благодаря которым информацию можно восстанавливать) составляет примерно 25%. Восстановить при этом можно количество данных, равное половине избыточных. Если емкость диска 700 Мб, то, получается, теоретически можно восстановить до 87,5 Мб из 700. При этом нам не обязательно знать, какой именно символ передан с ошибкой. Также стоит отметить, что вместе с кодированием используется перемежевание, когда байты разных блоков перемешиваются в определенном порядке, что в результате позволяет читать диски с обширными повреждениями, локализированными близко друг к другу (например, глубокие царапины), так как после операции, обратной перемежеванию, обширное повреждение оборачивается единичными ошибками во множестве блоков кода, которые поддаются восстановлению.