В этом посте я поговорю о простом, но иногда полезном приеме программирования — method chaining. Также расскажу про потенциальный подводный камень, связанный с его использованием

Antony Polukhin @antoshkka
Эксперт-разработчик C++
Бан по континентам
3 min
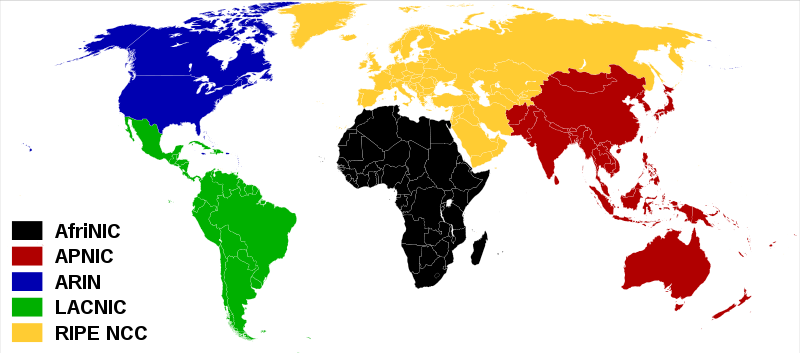
В одно прекрасное утро я просматривал логи и задал себе ряд вопросов:
- А жду ли я письма из Юго-Восточной Азии? (когда смотрел логи почты)
- И с какого перепугу ко мне стучатся ssh брутфорсеры из Штатов?
- Мне надо терпеть сетевые сканеры из Австралии?
- Кто мне звонит из Африки? (когда разглядывал логи asterisk)
- С какой стати к моему POP-серверу обращаются из Латинской Америки?
Почему бы не забанить по континентам? Оставив только нужный континент(ы)?
Арифметика полей Галуа для кодирования информации кодами Рида-Соломона
4 min

Коды Рида-Соломона относятся к недвоичным, блочным, помехоустойчивым кодам и могут использоваться в области хранения информации для избегания потери поврежденной информации.
Об особенностях внедрения СПО в малом бизнесе
5 min
Добрый день, уважаемое сообщество!
Существует большое количество малых и «маленьких, но гордых» организаций, которые при всей своей простоте вынуждены пользоваться определенной IT инфраструктурой. Хочу поделиться с вами некоторыми выводами по внедрению в них свободного ПО (СПО) и Линукса, которые я вынес для себя на базе многолетнего положительного опыта в этой области.

Обычно существовавшее изначально положение вещей характеризовалось следующим:
1. Организации с количеством компьютеров от 1 до 50 предпочитали использовать проприетарные решения для ОС одной хорошо всем известной заатлантической конторы.
2. Денег на покупку лицензий всегда не было. Предпочитали использовать «пиратчину».
Существует большое количество малых и «маленьких, но гордых» организаций, которые при всей своей простоте вынуждены пользоваться определенной IT инфраструктурой. Хочу поделиться с вами некоторыми выводами по внедрению в них свободного ПО (СПО) и Линукса, которые я вынес для себя на базе многолетнего положительного опыта в этой области.
Слепок типичного заказчика
Обычно существовавшее изначально положение вещей характеризовалось следующим:
1. Организации с количеством компьютеров от 1 до 50 предпочитали использовать проприетарные решения для ОС одной хорошо всем известной заатлантической конторы.
2. Денег на покупку лицензий всегда не было. Предпочитали использовать «пиратчину».
Внедрение корпоративного Linux в ПриватБанке
6 min
История
Внедрение Linux в ПриватБанке началось в 2007 году. За это время был пройден большой путь и хотелось бы поделиться с сообществом своим опытом внедрения. На данный момент мы достигли следующих показателей: более 36500 рабочих мест с ОС Linux в 4000 отделений, расположенных в 5 странах.
В 2007 году за основу был взят ASPLinux 11.2. Со временем для альтернативы были выбраны другие дистрибутивы — Fedora, openSUSE, Ubuntu. Позже стала очевидной необходимость создания собственного дистрибутива и системы управления рабочими станциями. Разработка началась в январе 2012 года. Для основы был выбран Ubuntu 12.04 LTS с рабочим окружением Gnome Classic (no effect). Основные аргументы: Ubuntu — самый распространённый десктопный дистрибутив последних лет; обширное комьюнити, где проще найти решение возникающих проблем; именно его в качестве основы внедрения выбрал Google, много примеров внедрения в государственных и муниципальных учреждениях Германии, Франции. Выбор системы управления остановился на Puppet.
В июне 2012 года стартовал переход и к январю 2013 на корпоративную ОС были переведены уже около 95% ПК. Такая скорость перехода обусловлена тем, что сотрудники уже имели опыт работы в Linux.
Основные задачи, которые удалось решить благодаря текущему внедрению:
- cущественная экономия ресурсов при поддержке ОС на рабочих местах сотрудников;
- поддержание программного обеспечения в актуальном состоянии;
- возможность оперативного применения критических обновлений (до 1 часа на всех ПК);
- cбор и анализ статистической информации о парке ПК и периферии;
- создание системы проактивной реакции на сбои (Event Manager).
Дальше более детальное описание компонентов нашей реализации.
7 простых оптимизаций, уменьшивших нагрузку на CPU с 80% до 27%
7 min
Уже более 3 лет наша команда занимается разработкой такого важного компонента сети оператора как PCRF. Policy and Charging Rules Function (PCRF) – решение для управления политиками обслуживания абонента в сетях LTE (3GPP), позволяющее в реальном времени назначать ту или иную политику, принимая во внимание сервисы, подключенные у абонента, его местонахождение, качество сети в данном месте в данный момент, время суток, объем потребленного трафика и т.д. Под политикой в данном контексте подразумевается доступный абоненту набор сервисов и параметры QoS (качества обслуживания). Анализируя соотношение цена-качество для различных продуктов в данной области от разнообразных поставщиков, мы приняли решение разрабатывать свой продукт. И вот уже более 2 лет, наш PCRF успешно работает на коммерческой сети компании Yota. Решение полностью софтовое, с возможностью устанавливать даже на обычные виртуальные сервера. Работает в коммерции на Red Hat Linux, но в целом возможна установка и под другие Linux-системы.
Испытания boost::lockfree на скорость и задержку передачи сообщения
11 min
Не так давно в boost-1.53 появился целый новый раздел — lockfree реализующий неблокирующие очереди и стек.
Я последние несколько лет работал с так называемыми неблокируюшими алгоритмами (lock-free data structures), мы их сами писали, сами тестировали, сами использовалии втайне ими гордились. Естественно, у нас немедленно встал вопрос, переходить ли с самодельных библиотек на boost, и если переходить, то когда?
Вот тогда у меня и возникла в первый раз идея применить к boost::lockfree кое-какие из методик которыми мы испытывали собственный код. К счастью, сам алгоритм нам тестировать не придется и можно сосредоточиться на измерении производительности.
Я постараюсь сделать статью интересной для всех. Тем кто еще не сталкивался с подобными задачами будет полезно посмотреть на то что такие алгоритмы способны, а главное, где и как их стоит или не стоит использовать. Для тех кто имеет опыт разработки неблокирующих очередей возможно будет интересно сравнить данные количественных измерений. Я сам по крайней мере таких публикаций еще не видел.
Я последние несколько лет работал с так называемыми неблокируюшими алгоритмами (lock-free data structures), мы их сами писали, сами тестировали, сами использовали
Вот тогда у меня и возникла в первый раз идея применить к boost::lockfree кое-какие из методик которыми мы испытывали собственный код. К счастью, сам алгоритм нам тестировать не придется и можно сосредоточиться на измерении производительности.
Я постараюсь сделать статью интересной для всех. Тем кто еще не сталкивался с подобными задачами будет полезно посмотреть на то что такие алгоритмы способны, а главное, где и как их стоит или не стоит использовать. Для тех кто имеет опыт разработки неблокирующих очередей возможно будет интересно сравнить данные количественных измерений. Я сам по крайней мере таких публикаций еще не видел.
Пишем сайт с новостями на Wt
9 min
Для начала расскажу немного о себе. Я студент 4 курса МАИ специальности «ЭВМ, комплексы, системы и сети», а также начинающий программист на С++/Qt. Очень давно я хотел научиться веб-разработке, но до изучения всех необходимых языков и технологий руки никак не доходили. Недавно на Хабре появилась статья о создании веб-приложений с помощью C++ библиотеки Wt, и я решил поближе познакомиться с этой библиотекой.
Перехват функций ядра Linux с использованием исключений (kprobes своими руками)
8 min
Tutorial
Перехват функций ядра является базовым методом, позволяющим переопределять (дополнять) различные его механизмы. Исходя из того, что за исключением небольших архитектурно-зависимых частей, ядро Linux почти полностью написано на языке C, можно утверждать, что для осуществления встраивания в большинство из компонентов ядра, достаточно иметь возможность перехвата соответствующих функций ЯВУ, реализующих ту или иную логику.
Данная статья является практическим обобщением представленных ранее статей:
Далее будет рассмотрено каким образом использование данных материалов может быть применимо в обеспечении возможности перехвата функций ядра Linux.
Данная статья является практическим обобщением представленных ранее статей:
- Управляемый PageFault в ядре Linux
- Кошерный способ модификации защищённых от записи областей ядра Linux
Далее будет рассмотрено каким образом использование данных материалов может быть применимо в обеспечении возможности перехвата функций ядра Linux.
0day* уязвимости к Новому Году: ICQ, Ebay, Forbes, PayPal и AVG
3 min
В одном из своих постов я пытался привлечь внимание к проблеме безответственного отношения к уязвимостям различных веб-сайтов. Представьте себе ситуацию: вы энтузиаст в области информационной безопасности, нашли уязвимости на каком-нибудь известном сайте и пытаетесь о ней сообщить, но:
В подобных ситуациях чаще всего энтузиасты ждут, а потом раскрывают детали уязвимостей. Но проблема в том, что даже при огласке ничего не меняется. Этот пост — компиляция подобных огласок (т.е. вся представленная информация уже была доступна публично длительное время) об уязвимостях на крупных ресурсах, возможно, что-нибудь да и изменится.
- Невозможно найти никаких контактных данных для связи с тех. поддержкой сайта, а лучше именно со службой безопасности;
- Контактные данные есть, но вам никто не отвечает;
- Или чудо! Контактные данные есть, вам отвечают, но говорят что это не уязвимость и исправлять они ничего не будут.
В подобных ситуациях чаще всего энтузиасты ждут, а потом раскрывают детали уязвимостей. Но проблема в том, что даже при огласке ничего не меняется. Этот пост — компиляция подобных огласок (т.е. вся представленная информация уже была доступна публично длительное время) об уязвимостях на крупных ресурсах, возможно, что-нибудь да и изменится.
Удобная работа в консоли, или красим STDERR в красный цвет
7 min

Работа в консоли
Многие из нас пользуются консолью каждый день, и, наверное, каждый задавал себе вопрос: как я могу сделать свою работу в консоли эффективнее? Что я могу сделать, чтобы тратить меньше времени на выполнение рутинных операций? В этой статье я бы хотел вкратце рассказать о нескольких простых, но полезных вещах при работе с bash, о которых вы, возможно, не знали.
Алгоритм Брезенхэма в приложениях реального времени — часть вторая
4 min
Recovery Mode
Продолжение поста "Алгоритм Брезенхэма в приложениях реального времени".
Напомним, что речь идет написании программы вывода для лазерных сканаторов

Напомним, что речь идет написании программы вывода для лазерных сканаторов
Отладка native-кода под Android: ручное и автоматизированное тестирование
18 min
Tutorial
С развитием и ростом популярности ОС Android количество и разнообразие устройств под её управлением неуклонно растёт. Из-за различий в архитектуре, предназначении и оптимизации скорость и стабильность работы исполняемого кода может значительно изменяться. Поэтому, для обеспечения стабильности и оптимизации работы приложений и ОС, особенно использующих особенности конкретной архитектуры, платформы, или кода, портированного с других платформ, стоит особо внимание уделить процессу отладки кода под Андроид. В этой статье пойдёт речь о ключевых моментах и особенностях работы с native-кодом под Android. Всем, кому интересен этот мануал, прошу под кат.
Разработка кроссплатформенных модульных приложений на C++ с библиотекой wxWidgets
31 min
Tutorial
Введение
Уже долгое время не пишу статьи о разработке, хотя сам процесс написания мне очень нравится и позволяет привести мысли в порядок.
И вот, есть возможность сейчас рассказать о наработках, которые появились за последнее время. Надеюсь, кому-то этот текст сильно упростит жизнь и даст толчок к покорению новых вершин.
В этот раз речь пойдет о создании кроссплатформенных приложений с плагинами на C++ с использованием библиотеки wxWidgets. Рассматриваться будут операционные системы Windows, Linux и OS X, как наиболее популярные.
Как обычно, первая часть будет обзорной, для того, чтобы снизить порог входа для читателей. Кому-то информация из первой части покажется очевидной (особенно то, что касается инструментария), но, все же, я считаю ее необходимой, ибо для новичков информация из первой части позволит с минимальными усилиями организовать процесс разработки.
Дальше — поэтапный разбор кода тестового приложения с пояснениями.
Lock-free структуры данных. Внутри. Схемы управления памятью
28 min

Как я упоминал в своих предыдущих заметках, основными трудностями при реализации lock-free структур данных являются ABA-проблема и удаление памяти. Я разделяю эти две проблемы, хоть они и связаны: дело в том, что существуют алгоритмы, решающие только одну из них.
В этой статье я дам обзор известных мне методов безопасного удаления памяти (safe memory reclamation) для lock-free контейнеров. Демонстрировать применение того или иного метода я буду на классической lock-free очереди Майкла-Скотта [MS98].
Lock-free структуры данных. Основы: Модель памяти
18 min

В предыдущей статье мы заглянули внутрь процессора, пусть и гипотетического. Мы выяснили, что для корректного выполнения параллельного кода процессору необходимо подсказывать, до каких пределов ему разрешено проводить свои внутренние оптимизации чтения/записи. Эти подсказки – барьеры памяти. Барьеры памяти позволяют в той или иной мере упорядочить обращения к памяти (точнее, кэшу, — процессор взаимодействует с внешним миром только через кэш). “Тяжесть” такого упорядочения может быть разной, — каждая архитектура может предоставлять целый набор барьеров “на выбор”. Используя те или иные барьеры памяти, мы можем построить разные модели памяти — набор гарантий, которые будут выполняться для наших программ.
В этой статье мы рассмотрим модель памяти C++11.
Два парадокса в программах на языке C
3 min
Хочу рассказать о двух странностях, с которыми мне пришлось столкнуться, программируя вычислительные алгоритмы на языке C.
Итак, первое неожиданное поведение для некоторых программистов. Вот маленькая прога.
Разберем ее. Поразрядная операция ~ инвертирует состояние каждого бита байта a, в который изначально записана единица. В результате должны получить 11111110b, то есть 254. Сдвигая этот байт вправо на один бит, должны получить 127. Однако код, который дает, например, компилятор gcc, выводит в консоль число 255?!
Сначала я подумал о том, что дело в приоритете — вдруг у компилятора приоритет операций «косячит»? То есть будто бы сначала делается сдвиг, а потом — инверсия (а что, логично...). Так в чем же дело?
Итак, первое неожиданное поведение для некоторых программистов. Вот маленькая прога.
#include <stdio.h>
int main()
{
unsigned char a = 1, b;
b = ~a >> 1;
printf("%u\n", b);
return 0;
}
Разберем ее. Поразрядная операция ~ инвертирует состояние каждого бита байта a, в который изначально записана единица. В результате должны получить 11111110b, то есть 254. Сдвигая этот байт вправо на один бит, должны получить 127. Однако код, который дает, например, компилятор gcc, выводит в консоль число 255?!
Сначала я подумал о том, что дело в приоритете — вдруг у компилятора приоритет операций «косячит»? То есть будто бы сначала делается сдвиг, а потом — инверсия (а что, логично...). Так в чем же дело?
Создаем платформер за 30 минут
15 min
Tutorial
Здравствуйте! Сегодня мы будем писать платформер, используя C++, Box2D и SFML, а также редактор 2D карт для игр Tiled Map Editor.
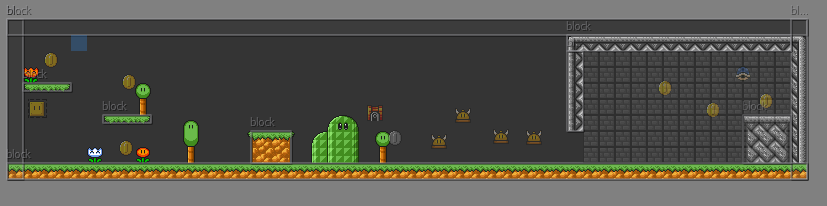
Вот результат (карта создавалась 5 минут + во время сьемки игра тормозила + экран не так растянут — дефект Bandicam):
Исходники и exe — внизу статьи.
Вот результат (карта создавалась 5 минут + во время сьемки игра тормозила + экран не так растянут — дефект Bandicam):
Исходники и exe — внизу статьи.
Как я наказал Firaxis или история о том, как перебрать бинарный движок через глушитель
6 min

Речь пойдёт о далёком 2005 году, когда только-только вышла Civilization4 от Sid Meier. К тому времени я плотно висел в Civilization3, прошёл её раз дцать на самых разных картах, и тут вышла долгожданная четвёрка. Это были годы P3-512Mb для mid-end и P4-1Gb в hi-end. Только топовые конфиги в те годы имели два гига памяти на борту.
Civilization 4 вышла с графикой уровня года 2002-2003го, что в принципе нормально для мэинстрима тех времён, особенно учитывая что это пошаговая стратегия, а не шутер. Но жрала с течением игры до 900Mb оперативки, что приводило к жуткому свопу, особенно на больших картах, особенно к концу игры, особенно на ноутбуках. Народ недоумевал, я тоже. Учитывая, что в те же годы вышел Far Cry с куда более красивой графикой, и который вполне игрался на максимуме даже с 512Mb на борту, такое поведение Civilization 4 выглядело крайне странным. Захотелось разобраться и покарать…
Linux pipes tips & tricks
8 min
Tutorial
Pipe — что это?
Pipe (конвеер) – это однонаправленный канал межпроцессного взаимодействия. Термин был придуман Дугласом Макилроем для командной оболочки Unix и назван по аналогии с трубопроводом. Конвейеры чаще всего используются в shell-скриптах для связи нескольких команд путем перенаправления вывода одной команды (stdout) на вход (stdin) последующей, используя символ конвеера ‘|’:
cmd1 | cmd2 | .... | cmdN
Например:
$ grep -i “error” ./log | wc -l
43
grep выполняет регистронезависимый поиск строки “error” в файле log, но результат поиска не выводится на экран, а перенаправляется на вход (stdin) команды wc, которая в свою очередь выполняет подсчет количества строк.
Логика
Конвеер обеспечивает асинхронное выполнение команд с использованием буферизации ввода/вывода. Таким образом все команды в конвейере работают параллельно, каждая в своем процессе.
Размер буфера начиная с ядра версии 2.6.11 составляет 65536 байт (64Кб) и равен странице памяти в более старых ядрах. При попытке чтения из пустого буфера процесс чтения блокируется до появления данных. Аналогично при попытке записи в заполненный буфер процесс записи будет заблокирован до освобождения необходимого места.
Важно, что несмотря на то, что конвейер оперирует файловыми дескрипторами потоков ввода/вывода, все операции выполняются в памяти, без нагрузки на диск.
Вся информация, приведенная ниже, касается оболочки bash-4.2 и ядра 3.10.10.
Простой дебаг
Утилита strace позволяет отследить системные вызовы в процессе выполнения программы:
$ strace -f bash -c ‘/bin/echo foo | grep bar’
....
getpid() = 13726 <– PID основного процесса
...
pipe([3, 4]) <– системный вызов для создания конвеера
....
clone(....) = 13727 <– подпроцесс для первой команды конвеера (echo)
...
[pid 13727] execve("/bin/echo", ["/bin/echo", "foo"], [/* 61 vars */]
.....
[pid 13726] clone(....) = 13728 <– подпроцесс для второй команды (grep) создается так же основным процессом
...
[pid 13728] stat("/home/aikikode/bin/grep",
...