В области новых технологий и продуктов мы привыкли, что «цифра» является синонимом всего передового, современного и высокотехнологичного, а «аналог» – всего ретроградского, вышедшего из употребления и низкотехнологичного.
Но если вы думаете, что аналог умер, вы ошибаетесь. Аналоговая обработка не только является ключевой составляющей множества жизненно важных систем, на которых мы опираемся, но и пробивает дорогу в новое поколение вычислительных и интеллектуальных систем, лежащих в основе очень интересных технологий будущего: искусственного интеллекта и робототехники.
Перед тем, как мы обсудим возрождение аналога – и то, почему инженеры и инноваторы, работающие над ИИ и роботами, должны обратить на это внимание – необходимо понять важность и наследие старого аналогового века.








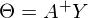 , где
, где 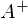 — псевдообратная матрица. Это решение наглядное, точное и короткое. Но есть проблема, которую можно решить численно. Градиентный спуск — метод численной оптимизации, который может быть использован во многих алгоритмах, где требуется найти экстремум функции — нейронные сети, SVM, k-средних, регрессии. Однако проще его воспринять в чистом виде (и проще модифицировать).
— псевдообратная матрица. Это решение наглядное, точное и короткое. Но есть проблема, которую можно решить численно. Градиентный спуск — метод численной оптимизации, который может быть использован во многих алгоритмах, где требуется найти экстремум функции — нейронные сети, SVM, k-средних, регрессии. Однако проще его воспринять в чистом виде (и проще модифицировать). В свое время на Хабре был опубликован цикл статей «Логика мышления». С тех пор прошло два года. За это время удалось сильно продвинуться вперед в понимании того, как работает мозг и получить интересные результаты моделирования. В новом цикле «Логика сознания» я опишу текущее состоянии наших исследований, ну а попутно попытаюсь рассказать о теориях и моделях интересных для тех, кто хочет разобраться в биологии естественного мозга и понять принципы построения искусственного интеллекта.
В свое время на Хабре был опубликован цикл статей «Логика мышления». С тех пор прошло два года. За это время удалось сильно продвинуться вперед в понимании того, как работает мозг и получить интересные результаты моделирования. В новом цикле «Логика сознания» я опишу текущее состоянии наших исследований, ну а попутно попытаюсь рассказать о теориях и моделях интересных для тех, кто хочет разобраться в биологии естественного мозга и понять принципы построения искусственного интеллекта.


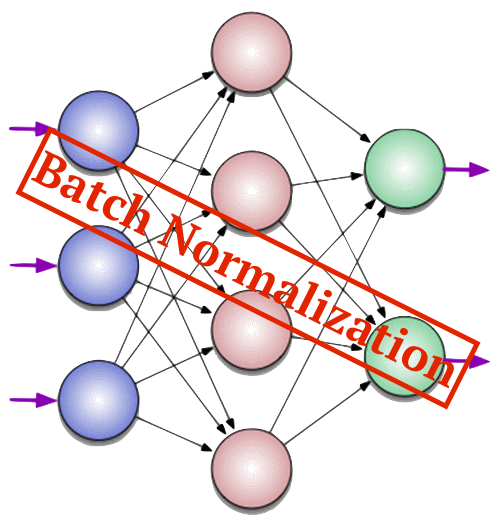
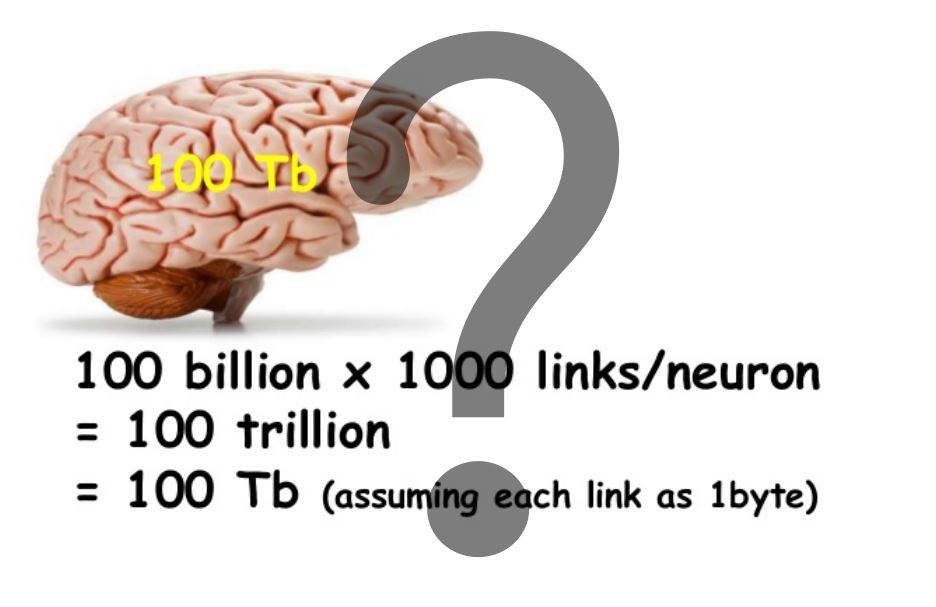 Когда с нами что-то происходит наш мозг фиксирует это, создавая воспоминания. Изменения, которые при этом происходят с мозгом, принято называть энграммами или следами памяти.
Когда с нами что-то происходит наш мозг фиксирует это, создавая воспоминания. Изменения, которые при этом происходят с мозгом, принято называть энграммами или следами памяти.