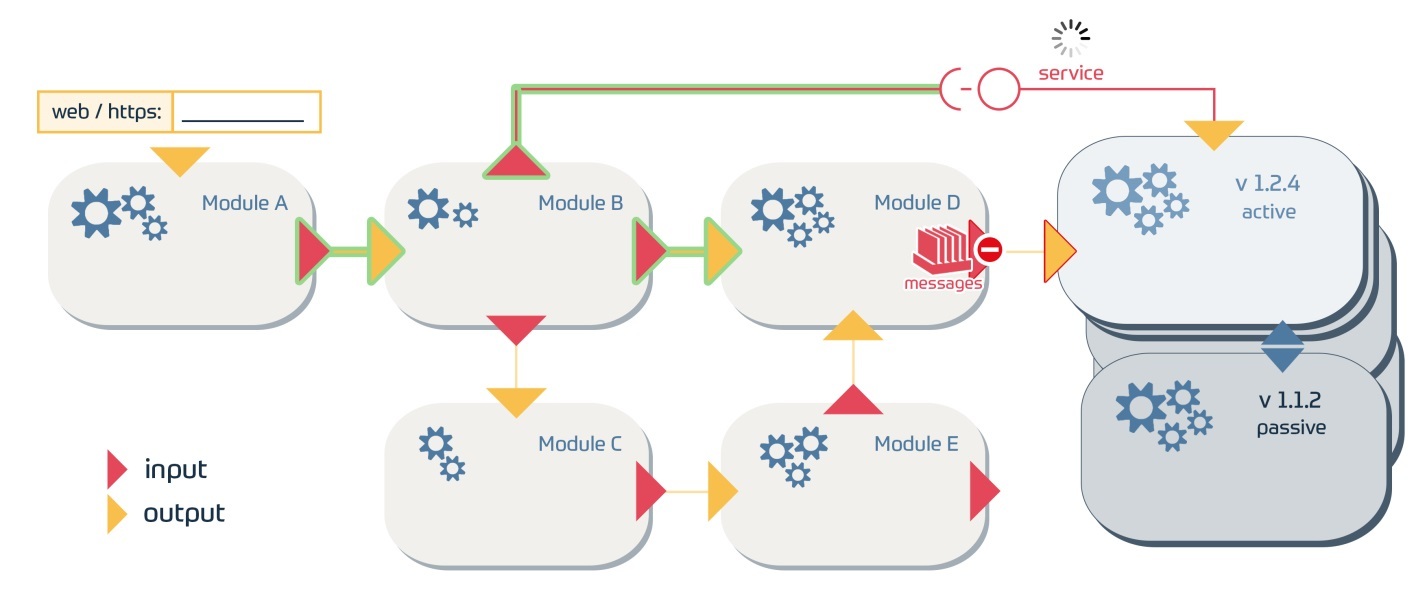
При написании любого достаточно крупного проекта всегда встают более-менее похожие проблемы. Одна из них — проблема скорости получения обновлений системы. Относительно легко можно наладить быстрое получение небольших обновлений. Довольно просто изредка получать обновления большого объема. Но что если надо быстро обновлять большой массив данных?
Для Таргета Mail.Ru, как и для всякой рекламной системы, быстрый учет изменений важен по следующим причинам:
• возможность быстрого отключения показа кампании, если рекламодатель остановил ее в интерфейсе или если у него кончились деньги, а значит, мы не будем показывать ее бесплатно;
• удобство для рекламодателя: он может поменять цену баннера в интерфейсе, и уже через несколько секунд его баннеры начнут показываться по новой стоимости;
• быстрое реагирование на изменение ситуации: изменение CTR, поступление новых данных для обучения математических моделей. Все это позволяет корректировать стратегию показа рекламы, чутко реагируя на внешние факторы.
В этой статье я расскажу об обновлении данных, лежащих в больших таблицах в БД MySQL, фокусируясь на скорости и консистентности — ведь не хотелось бы уже получить новый заведенный баннер, но при этом не получить данную рекламную кампанию.