Одна из вещей, которые никогда не делают пользователи — это чтение до конца лицензионных соглашений. Тем временем, читать их стоит, даже если, казалось бы, в контексте конкретного сервиса их содержание представляется очевидным.
К таким «очевидным» сервисам относится, например, сервис проверки цифрового пропуска
https://i.moscow/covid. Если раньше он позволял проверить только организацию по ИНН, то с недавних пор ДИТ Москвы стал массово аннулировать пропуска горожанам за якобы предоставление неверных сведений о месте работы — и отсылать их для подтверждения места работы на указанный сервис.
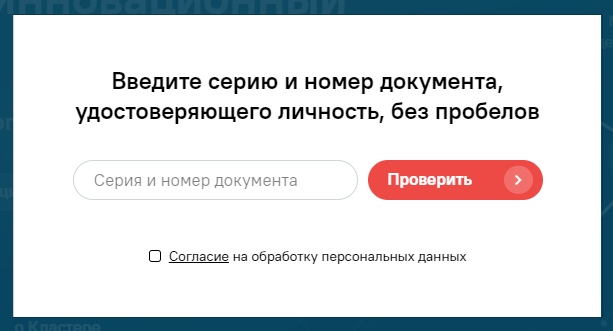
При нажатии на «Если у Вас заблокировали цифровой пропуск, перейдите по ссылке» сервис выдаёт просьбу ввести сначала номер паспорта, а потом ИНН компании, сопровождаемую непримечательной галочкой:
Абсолютное большинство людей проставят её, не читая сопутствующий документ — и
очень зря.
Если говорить коротко, все граждане, попавшие на этот сервис, подписываются на передачу абсолютно всех данных, которые сервис в принципе способен о них собрать — от IP-адреса до номера паспорта и названия работодателя — любым третьим лицам с практически любыми целями, включая рассылку рекламы, на срок в 10 лет.