Меня зовут Эдуард Мацуков, я делаю Таксометр — приложение для водителей Яндекс.Такси. Занимаюсь инфраструктурой и всем, что с ней связано. Какое-то время назад я выступил с докладом — рассказал об опыте дружбы TeamCity с нашим проектом и с разработчиками в целом. Отдельная часть доклада посвящена тому, при чем здесь Kotlin.
— Практически каждый день ко мне лично и к нашим разработчикам приходят с вопросами. А где достать сборку? А где взять такую-то ветку? А почему что-то упало? Где в моем коде проблема? Почему что-то работает неправильно? Для этого у нас в проекте есть много самописной инфраструктуры, плагинов, различных хаков и трюков, которые мы используем. С одной стороны — чтобы облегчить жизнь разработчика, с другой — чтобы реализовать конкретные бизнес-задачи.
— Практически каждый день ко мне лично и к нашим разработчикам приходят с вопросами. А где достать сборку? А где взять такую-то ветку? А почему что-то упало? Где в моем коде проблема? Почему что-то работает неправильно? Для этого у нас в проекте есть много самописной инфраструктуры, плагинов, различных хаков и трюков, которые мы используем. С одной стороны — чтобы облегчить жизнь разработчика, с другой — чтобы реализовать конкретные бизнес-задачи.
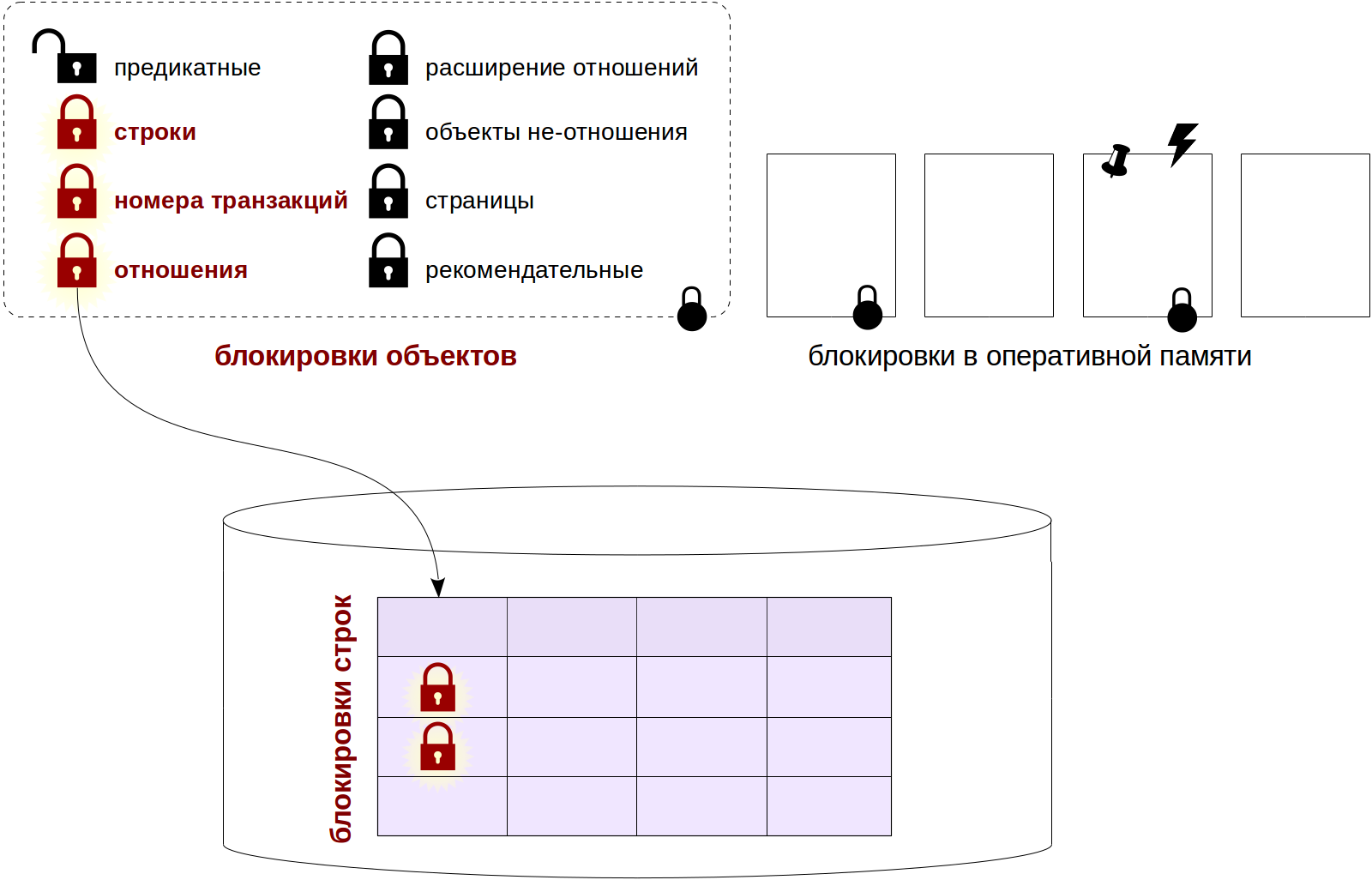
 Язык структурированных запросов (SQL) является незаменимым навыком в индустрии информатики, и вообще говоря, изучение этого навыка относительно просто. Однако большинство забывают, что SQL — это не только написание запросов, это всего лишь первый шаг дальше по дороге. Обеспечение производительности запросов или их соответствия контексту, в котором вы работаете, — это совсем другая вещь.
Язык структурированных запросов (SQL) является незаменимым навыком в индустрии информатики, и вообще говоря, изучение этого навыка относительно просто. Однако большинство забывают, что SQL — это не только написание запросов, это всего лишь первый шаг дальше по дороге. Обеспечение производительности запросов или их соответствия контексту, в котором вы работаете, — это совсем другая вещь.