Лучшие практики Kubernetes. Создание небольших контейнеров
Лучшие практики Kubernetes. Организация Kubernetes с пространством имен
Лучшие практики Kubernetes. Проверка жизнеспособности Kubernetes с помощью тестов Readiness и Liveness
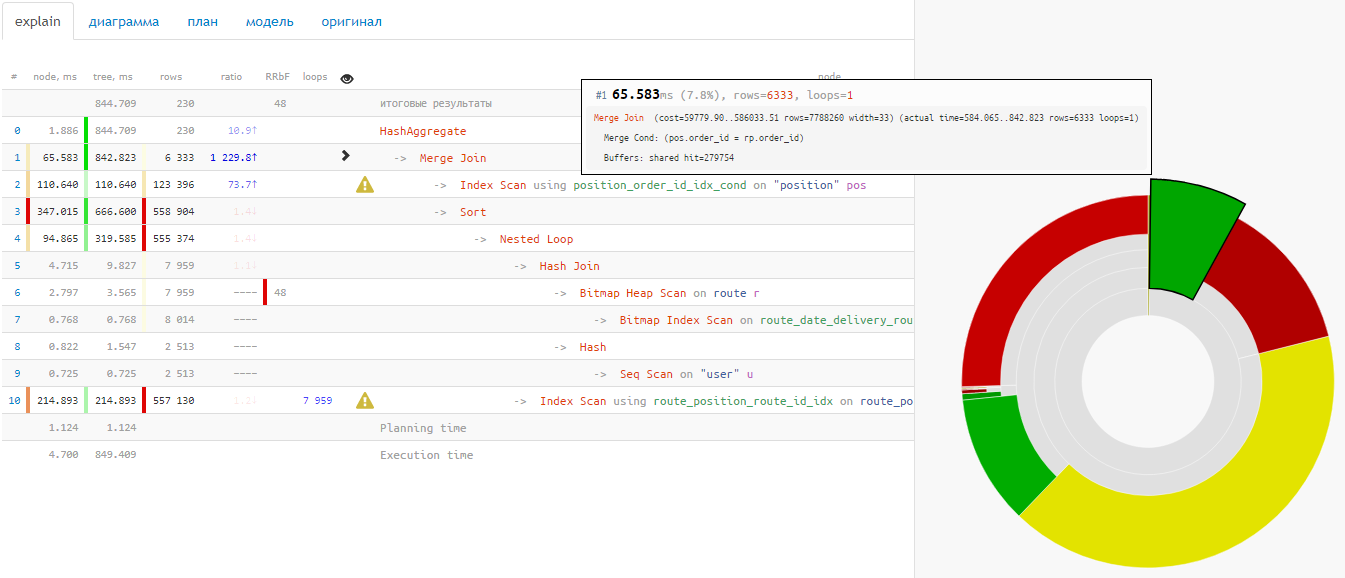
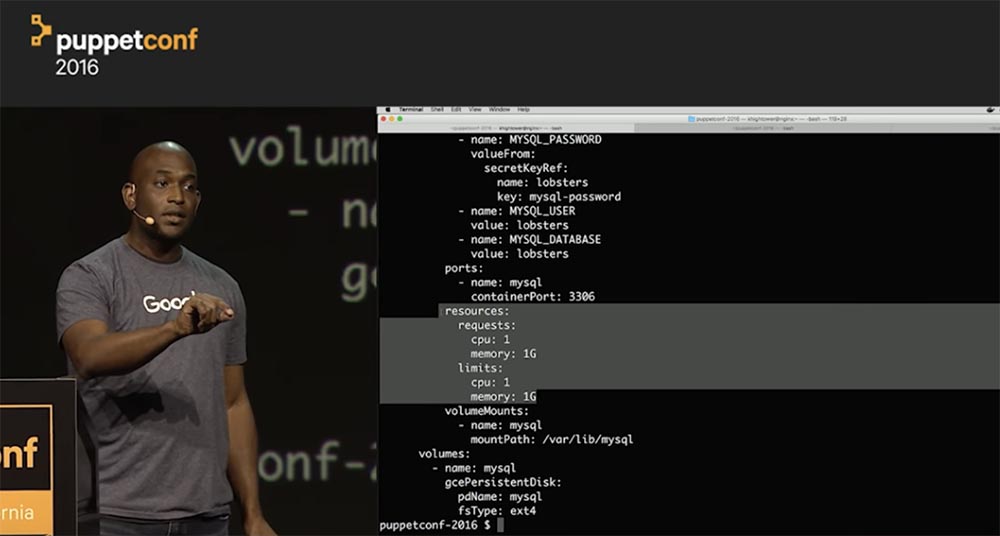
Для каждого ресурса Kubernetes имеется возможность настраивать два типа требований — Requests и Limits. Первое описывает минимальные требования к наличию свободных ресурсов узла, необходимых для запуска контейнера или пода, второе жестко ограничивает ресурсы, доступные контейнеру.
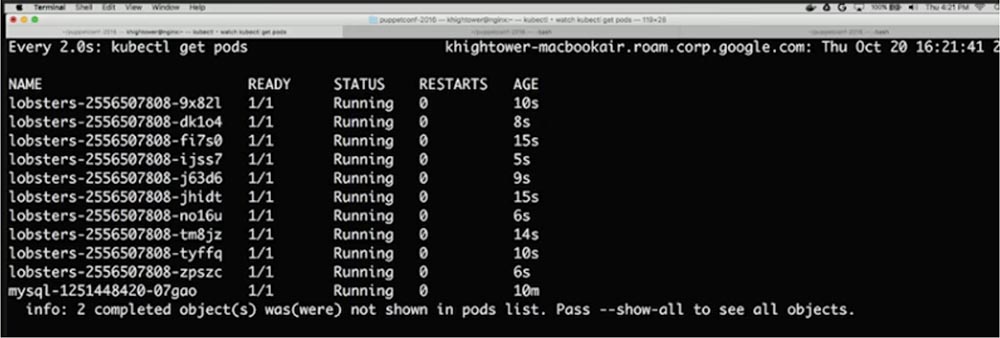
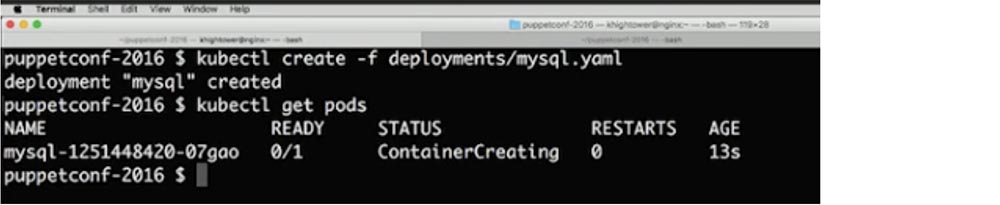
Когда Kubernetes планирует pod, очень важно, чтобы у контейнеров было достаточно ресурсов для нормальной работы. Если вы планируете развернуть большое приложение на узле с ограниченными ресурсами, вполне возможно, что оно не будет работать по причине того, что у узла заканчивается память или ему не хватает мощности процессора. В этой статье мы рассмотрим, как можно решить проблемы нехватки компьютерных мощностей с помощью запросов на ресурсы и ограничения.
Запросы Requests и ограничения Limits — это механизмы, которые Kubernetes использует для управления такими ресурсами, как, например, процессор и память. Requests — это то, в результате чего контейнер гарантированно получает запрашиваемый ресурс. Если контейнер запрашивает ресурс, то Kubernetes запланирует его только на том узле, который способен его предоставить. Ограничения Limits контролируют, что ресурсы, запрашиваемые контейнером, никогда не превысят определенного значения.

Лучшие практики Kubernetes. Организация Kubernetes с пространством имен
Лучшие практики Kubernetes. Проверка жизнеспособности Kubernetes с помощью тестов Readiness и Liveness
Для каждого ресурса Kubernetes имеется возможность настраивать два типа требований — Requests и Limits. Первое описывает минимальные требования к наличию свободных ресурсов узла, необходимых для запуска контейнера или пода, второе жестко ограничивает ресурсы, доступные контейнеру.
Когда Kubernetes планирует pod, очень важно, чтобы у контейнеров было достаточно ресурсов для нормальной работы. Если вы планируете развернуть большое приложение на узле с ограниченными ресурсами, вполне возможно, что оно не будет работать по причине того, что у узла заканчивается память или ему не хватает мощности процессора. В этой статье мы рассмотрим, как можно решить проблемы нехватки компьютерных мощностей с помощью запросов на ресурсы и ограничения.
Запросы Requests и ограничения Limits — это механизмы, которые Kubernetes использует для управления такими ресурсами, как, например, процессор и память. Requests — это то, в результате чего контейнер гарантированно получает запрашиваемый ресурс. Если контейнер запрашивает ресурс, то Kubernetes запланирует его только на том узле, который способен его предоставить. Ограничения Limits контролируют, что ресурсы, запрашиваемые контейнером, никогда не превысят определенного значения.