Часть 1
Давай сразу код!
import numpy as np
X = np.array([ [0,0,1],[0,1,1],[1,0,1],[1,1,1] ])
y = np.array([[0,1,1,0]]).T
alpha,hidden_dim = (0.5,4)
synapse_0 = 2*np.random.random((3,hidden_dim)) - 1
synapse_1 = 2*np.random.random((hidden_dim,1)) - 1
for j in xrange(60000):
layer_1 = 1/(1+np.exp(-(np.dot(X,synapse_0))))
layer_2 = 1/(1+np.exp(-(np.dot(layer_1,synapse_1))))
layer_2_delta = (layer_2 - y)*(layer_2*(1-layer_2))
layer_1_delta = layer_2_delta.dot(synapse_1.T) * (layer_1 * (1-layer_1))
synapse_1 -= (alpha * layer_1.T.dot(layer_2_delta))
synapse_0 -= (alpha * X.T.dot(layer_1_delta))
Часть 1: Оптимизация
В первой части я описал основные принципы обратного распространения в простой нейросети. Сеть позволила нам померить, каким образом каждый из весов сети вносит свой вклад в ошибку. И это позволило нам менять веса при помощи другого алгоритма — градиентного спуска.
Суть происходящего в том, что обратное распространение не вносит в работу сети оптимизацию. Оно перемещает неверную информацию с конца сети на все веса внутри, чтобы другой алгоритм уже смог оптимизировать эти веса так, чтобы они соответствовали нашим данным. Но в принципе, у нас в изобилии присутствуют и другие методы нелинейной оптимизации, которые мы можем использовать с обратным распространением:



 Посмотрим на то, как с ними работать в Python, какие возможные методы и модели можно использовать для прогнозирования; что такое двойное и тройное экспоненциальное взвешивание; что делать, если стационарность — это не про вас; как построить SARIMA и не умереть; и как прогнозировать xgboost-ом. И всё это будем применять к примеру из суровой реальности.
Посмотрим на то, как с ними работать в Python, какие возможные методы и модели можно использовать для прогнозирования; что такое двойное и тройное экспоненциальное взвешивание; что делать, если стационарность — это не про вас; как построить SARIMA и не умереть; и как прогнозировать xgboost-ом. И всё это будем применять к примеру из суровой реальности. 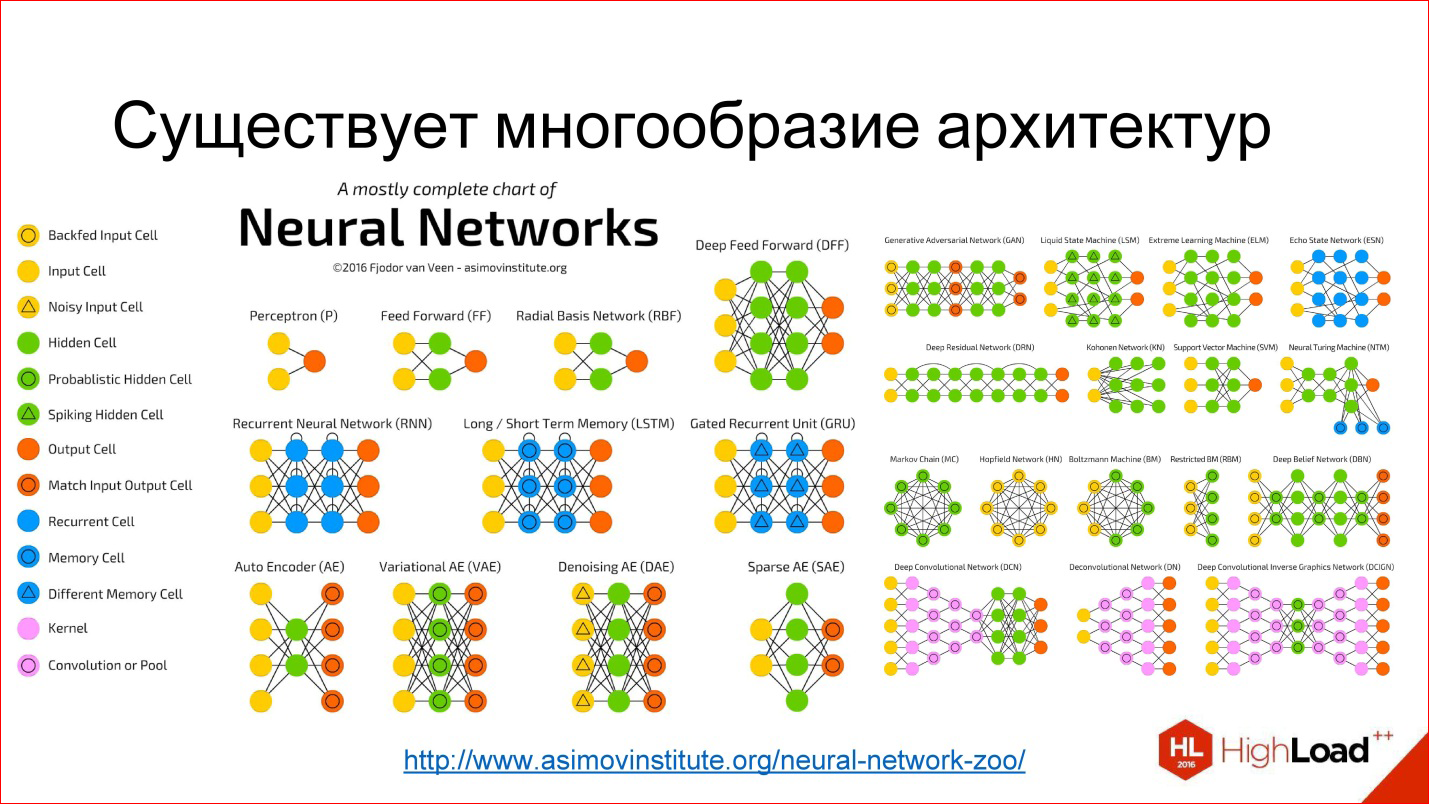


 Данное занятие мы посвятим методам обучения без учителя (unsupervised learning), в частности методу главных компонент (PCA — principal component analysis) и кластеризации. Вы узнаете, зачем снижать размерность в данных, как это делать и какие есть способы группирования схожих наблюдений в данных.
Данное занятие мы посвятим методам обучения без учителя (unsupervised learning), в частности методу главных компонент (PCA — principal component analysis) и кластеризации. Вы узнаете, зачем снижать размерность в данных, как это делать и какие есть способы группирования схожих наблюдений в данных.





