Посмотрите, как Google отслеживает ваше местоположение. С Python, Jupyter, Pandas, Geopandas и Matplotlib
В отделе продаж можно услышать аббревиатуру ABC: Always Be Closing, что означает заключение сделки с покупателем. Последнее десятилетие породило еще одну аббревиатуру ABCD: Always Be Collecting Data.
Мы используем Google для почты, карт, фотографий, хранилищ, видео и многого другого. Мы используем Twitter, чтобы читать поток сознания одного президента. Мы используем Facebook для обмена сообщениями и… ну, почти все. Но наши родители пользуются им. Мы используем TikTok… Понятия не имею, зачем.
На самом деле, оказывается, что большинство из вышеперечисленного бесполезно… Ничего подобного, суть в том, что мы их используем. Мы их используем, и они бесплатны. В экономике XXI века, если вы не платите за товар, вы являетесь товаром.
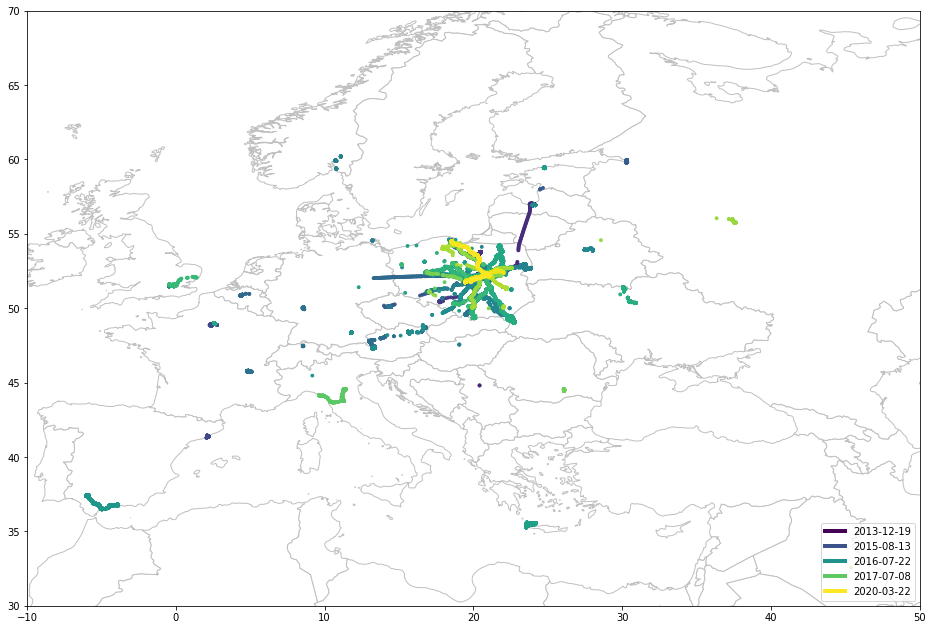
Итак, короче говоря, я хотел выяснить, насколько корпорация Alphabet, владелец Google, обо мне знает. Крошечная доля, я посмотрел на историю геолокации. Я никогда не отключал службы определения местоположения, потому что ценил комфорт выше конфиденциальности. Плохая идея.