Разрабатывая свою игру, движок или фреймворк, вы в любом случае столкнетесь с необходимостью реализации системы загрузки ресурсов, выполнения задач вне основного цикла игры, вынесения различных подсистем (звук, рендер, физика, эффекты) в отдельные потоки, чтобы снизить время подготовки кадра и улучшить общую производительность. Будучи классическим программистом, вы, наверное, знаете о проблемах реализации многопоточности, использовании блокировок и алгоритмов, которые основаны на блокировках.
В обычном программировании с блокировками, когда возникает необходимость пошарить данные, приходится использовать механизмы сериализации доступа к таким данным, чтобы операции, выполняющие работу с такими данными, были ограничены от одновременного вмешательства со стороны других потоков и возможности их поломать. В прямом смысле поломать. Даже такая простая операция, как ++count, где count имеет тип integer, требует блокировки, поскольку операция инкремента в общем случае представляет собой трехшаговую операцию (чтение, модификация, запись), которая не является атомарной. Про что-то более сложное и длительное я уже и не говорю.
За кажущейся простотой скрывается множество граблей и ловушек: взаимные блокировки (deadlock), «голодание» потоков, асинхронные ошибки. Это похоже на попытку дирижировать оркестром, где музыканты игнорируют ритм. Проще говоря, любые действия над данными могут привести к проблемам, и чтобы этого не происходило, операции над данными должны быть атомарными, это решается вводом в код примитивов синхронизации, вроде мьютексов, семафоров, спинлоков.
Первая хорошая сторона программирования с блокировками состоит в том, что пока ресурс заблокирован, никакая другая логика не может вмешаться. Вторая хорошая сторона — люди прекрасно понимают, читают и работают с таким кодом, потому что он хорошо вписывается в "естественное" понимание устройства мира. А вот дальше начинаются проблемы...




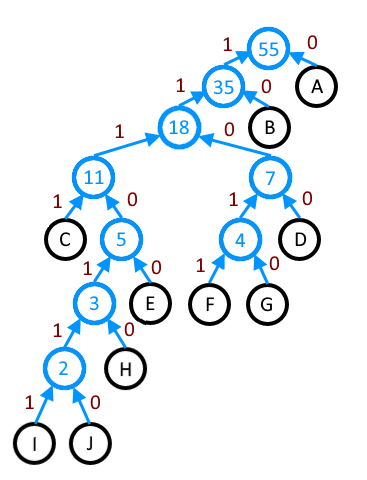
 Давным-давно, когда я был ещё наивным школьником, мне вдруг стало жутко любопытно: а каким же волшебным образом данные в архивах занимают меньше места? Оседлав свой верный диалап, я начал бороздить просторы Интернетов в поисках ответа, и нашёл множество статей с довольно подробным изложением интересующей меня информации. Но ни одна из них тогда не показалась мне простой для понимания — листинги кода казались китайской грамотой, а попытки понять необычную терминологию и разнообразные формулы не увенчивались успехом.
Давным-давно, когда я был ещё наивным школьником, мне вдруг стало жутко любопытно: а каким же волшебным образом данные в архивах занимают меньше места? Оседлав свой верный диалап, я начал бороздить просторы Интернетов в поисках ответа, и нашёл множество статей с довольно подробным изложением интересующей меня информации. Но ни одна из них тогда не показалась мне простой для понимания — листинги кода казались китайской грамотой, а попытки понять необычную терминологию и разнообразные формулы не увенчивались успехом.