После написания первой части статьи аппетит разыгрался и захотелось продолжить изучение, на этот раз больше с уклом в практическую часть. Весь сыр-бор у нас разгорелся из-за необходимости взаимодействии приложений и платформ, поэтому именно этому в основном и будет посвящена статья.

Пользователь
Hadoop, часть 1: развертывание кластера
11 min

Непрерывный рост данных и увеличение скорости их генерации порождают проблему их обработки и хранения. Неудивительно, что тема «больших данных» (Big Data) является одной из самых обсуждаемых в современном ИТ-сообществе.
Материалов по теории «больших данных» в специализированных журналах и на сайтах сегодня публикуется довольно много. Но из теоретических публикаций далеко не всегда ясно, как можно использовать соответствующие технологии для решения конкретных практических задач.
Одним из самых известных и обсуждаемых проектов в области распределенных вычислений является Hadoop — разрабатываемый фондом Apache Software Foundation свободно распространяемый набор из утилит, библиотек и фреймворк для разработки и выполнения программ распределенных вычислений.
Мы уже давно используем Hadoop для решения собственных практических задач. Результаты нашей работы в этой области стоят того, чтобы рассказать о них широкой публике. Эта статья — первая в цикле о Hadoop. Сегодня мы расскажем об истории и структуре проекта Hadoop, а также покажем на примере дистрибутива Hadoop Cloudera, как осуществляется развертывание и настройка кластера.
Осторожно, под катом много трафика.
Играем в RSS с PlayFramework 2.2 и Scala
12 min

Доброго времени суток, уважаемые хабравчане.
Мы,
Мы с товарищами часто задавались подобным вопросом. В итоге родилась простая мысль — напиши RSS читалку. Тут тебе и работа с сетью, и XML парсер, и БД можно подключить, поглядеть на шаблонизатор. Да мало ли.
Итак, здесь начинается увлекательное путешествие в стек Play Framework 2.2 + Scala + MongoDB на бэкэнде и AngularJS + CoffeeScript на фронтенде.
TL;DR
Весь проект вместился в ~250-300 строк на Scala с документацией и ~150 строк на CS. Ну и немного HTML.
Код доступен на Bitbucket
Код доступен на Bitbucket
Технологии правят… информацией. Технологическая пицца
4 min
Всё лучшее, зачастую, случается внезапно. Редко когда тщательно спланированная вечеринка может сравниться с внезапным визитом друзей, а блюдо, приготовленное точно по рецепту, с импровизацией мастера. В нашей команде этот феномен тоже имеет место быть: мы не задумывались о «рецептах», когда за пару недель реализовывали Media Monitor, который, как иногда случается в разработке нишевых B2B продуктов, оказался на удивление востребованным.

Большие данные — неотъемлемая часть нашей жизни
5 min
В прошлой статье речь шла о том, как Big Data вообще и продукты LSI в частности позволяют предсказывать погоду, и почему это так важно. С момента выхода той статьи произошло одно интересное событие, подтверждающее важность затронутой темы. Всем известная компания Monsanto, мировой лидер биотехнологии растений приобрела компанию The Climate Corporation из Сан-Франциско за 930 миллионов долларов, последняя как раз занимается анализом «больших данных» связанных с погодой и климатом. По словам СЕО Monsanto: «Climate Corporation фокусируется на том, чтоб предоставить сельскому хозяйству больше возможностей за счет науки обработки данных». Но, разумеется, не одними только прогнозами состояния атмосферы полезны для нас «большие данные», давайте рассмотрим еще пару интересных применений.
Каждый год, в конце осени — начале зимы, мы все с определенной покорностью ожидаем начала неизбежной эпидемии гриппа. Несмотря на относительную «безопасность» этой болезни, часто она способна дать огромные осложнения, а ежегодное число жертв по всему миру по данным ВОЗ составляет от 250 до 500 тысяч человек.

Каждый год, в конце осени — начале зимы, мы все с определенной покорностью ожидаем начала неизбежной эпидемии гриппа. Несмотря на относительную «безопасность» этой болезни, часто она способна дать огромные осложнения, а ежегодное число жертв по всему миру по данным ВОЗ составляет от 250 до 500 тысяч человек.
Runnable: поисковик по коду с его исполнением в VM
1 min

Бывший сотрудник Amazon запустил поисковик по исходному коду Runnable.com, который отличается уникальной особенностью: он не только ищет код, но и исполняет его в виртуальной машине EC2 прямо в результатах поиска. Более того, можно собственноручно внести изменения в код — и снова запустить его, чтобы посмотреть результаты.
Количество ложно-положительных срабатываний фильтра Блума [перевод]
3 min
Количество ложно-положительных срабатываний фильтра Блума.
Описание
Фильтр Блума — это рандомизированная структура данных для запросов, разработанная Бёртоном Блумом в 1970 году. Фильтр Блума даёт ошибочный ответ на запрос, т.н. ложно-положитеное срабатывание. Т.е. если мы добавляем некоторый элемент, то существует отличная от нуля вероятность, что фильтр Блума вернет ответ что элемент находится в векторе, хотя его там нет.
Грубо говоря, фильтр Блума возвращает 2 возможных ответа:
- элемента нет в векторе
- элемент возможно есть в векторе
Блум проанализировал вероятность таких ошибочных ответов, но его анализ является некорректным.
PostgreSQL 9.3 Что нового?
9 min

Здравствуйте, хабрачеловеки! Не так уж давно вышел релиз PostgreSQL 9.3 и я хотел бы ознакомить Вас с наиболее важными новшествами, касающимися клиентской части, которые, возможно, пригодятся Вам. В этой статье рассмотрено следующее:
- материализированные представления
- обновляемые представления
- триггеры к событиям
- рекурсивные представления
- латеральное присоединение
- изменяемые внешние таблицы
- функции и операторы для работы с типом JSON
Выучить французский и остаться в Тулузе
3 min

Про Тулузу многие читатели Хабра должны были слышать как о штаб-квартире Аэробус и аэрокосмическом центре Европы. К этому добавлю, что до Средиземного моря отсюда меньше двух часов езды и до Атлантического океана три часа на машине. Так же в двух шагах Пиренеи и Испания. Температура воздуха сегодня 27 градусов. Если вам интересно, то я могу раскрыть легкий способ переехать сюда жить.
Генерация больших объемов полезных данных
4 min
Хочу поделиться опытом создания механизма генерации большой базы данных товаров. С его помощью наши пользователи могут за несколько минут сгенерировать более миллиона однотипных, но разных записей.
Прочтите это, прежде чем отправить очередное деловое письмо
2 min
Translation

До того, как вы отправите следующий рабочий email, прочтите этот список. Здесь перечислено пять вредных привычек, которые присущи многим в общении. Прочитав, удаляйте, удаляйте и удаляйте все ошибки, которые найдете в своих письмах!
После этого ваши сообщения станут внушительнее, а коллеги оценят вашу новую манеру письма — более внятную и лаконичную.
Итак, ниже небольшой чеклист для вас.
Переведено в Alconost.
HBase, загрузка больших массивов данных через bulk load
4 min
Привет коллеги.
Хочу поделиться своим опытом использования HBase, а именно рассказать про bulk loading. Это еще один метод загрузки данных. Он принципиально отличается от обычного подхода (записи в таблицу через клиента). Есть мнение, что с помощью bulk load можно очень быстро загружать огромные массивы данных. Именно в этом я решил разобраться.
Хочу поделиться своим опытом использования HBase, а именно рассказать про bulk loading. Это еще один метод загрузки данных. Он принципиально отличается от обычного подхода (записи в таблицу через клиента). Есть мнение, что с помощью bulk load можно очень быстро загружать огромные массивы данных. Именно в этом я решил разобраться.
BigQuery с функцией анализа данных – теперь и в режиме реального времени
3 min
Translation
Коммерческие предприятия постоянно получают огромные объемы данных от сетевых приложений, совершающих множество транзакций, обслуживающих миллионы людей и постоянно растущее число подключенных устройств. Важнейшее условие сохранения конкурентоспособности — способность быстро реагировать на изменения в этих данных. В то же время, компании занимаются сбором, хранением и анализом больших объемов информации, иногда сотен гигабайт в день, используя системы, которые просто не способны справиться с подобным темпом работы.
Мы создали BigQuery, чтобы помочь коммерческим предприятиям справиться с этой проблемой без необходимости инвестировать в сложное дорогостоящее оборудование. Представляем две новые функции, которые смогут упростить их задачу.
Мы создали BigQuery, чтобы помочь коммерческим предприятиям справиться с этой проблемой без необходимости инвестировать в сложное дорогостоящее оборудование. Представляем две новые функции, которые смогут упростить их задачу.
Google Constitute — сравнение 160 мировых конституций
1 min
Компания Google запустила уникальный научный проект Constitute — справочник по всем мировым конституциям.
«Конституции уникальны настолько же, насколько и народы под их управлением, — пишет компания в официальном блоге, — они существуют в той или иной форме уже тысячу лет. Каждый год появляется примерно пять новых конституций, а 20-30 пересматриваются»
Аналитика в рознице: сегодня вы не купили презервативы, а магазин уже знает, когда вам пригодится скидка на детское питание
9 min
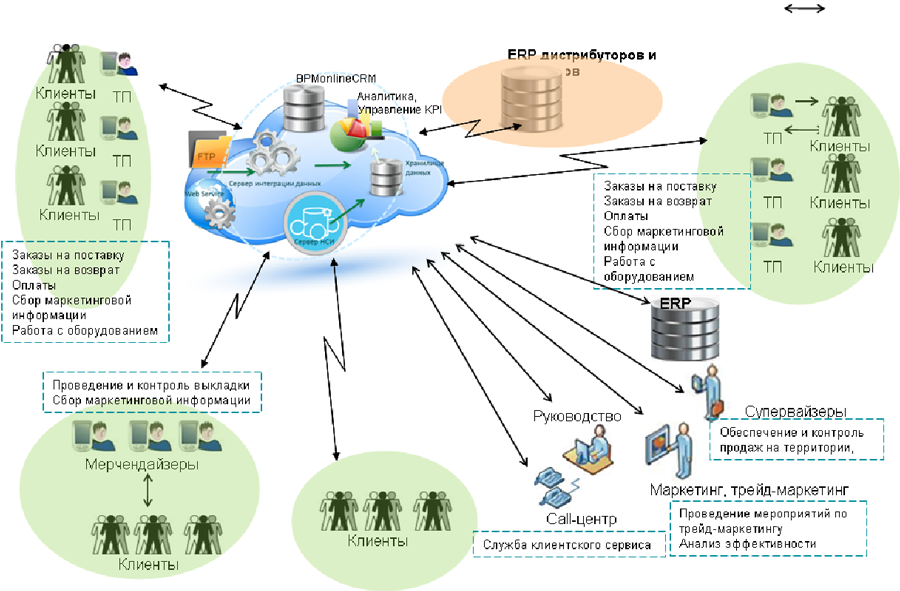
Вот как-то так это хитро работает
Про вашего будущего ребёнка – это, конечно, утрировано, но все может быть. На практике мы помогаем рознице бороться за каждый рубль с помощью математического аппарата. Вот, например, у вас в бумажнике есть карта лояльности, либо вы расплачиваетесь кредиткой. Это значит, что в целом магазин знает, сколько и каких продуктов вам надо. Дальше можно построить оптимальную модель вашего путешествия по магазину и понять, в какой ситуации вы купите больше. Что где должно стоять, какое молоко вы предпочитаете (вдруг вы готовы брать дорогое и натуральное без колебаний?) и так далее. Смоделировать вас по совокупности данных легко.
Такую же аналитику можно применять ко всем аспектам работы розницы.
Из смешного — один раз система просчитала, что будет выгодно уничтожить примерно полтонны бумаги. Сначала думали, что баг — но начали копать и выяснили, что поставщик даёт скидку за определённый порог закупки. А сеть может не успевать продавать нужное количество бумаги. С учётом стоимости склада, поставки и уровня скидки начиная с порога — проще взять и уничтожить кучу товара, чтобы получать его по цене ниже. Скидка минимум вдвое компенсирует убытки от его потери.
Вам не нужен Hadoop — у вас просто нет столько данных
4 min
Translation
Меня спросили: «Сколько у вас опыта с большими данными и Hadoop?» Я ответил, что часто использую Hadoop, но редко — с объёмами данных больше нескольких ТБ. Я новичок в больших данных — понимаю идеи, писал код, но не в серьёзных масштабах.
Следующий вопрос был: «Можете ли вы сделать простую группировку и сумму в Hadoop?» Разумеется, могу, и я попросил пример формата данных.
Они вручили мне флэш-диск со всеми 600 МБ данных (да, это были именно все данные, а не выборка). Не понимаю, почему, но им не понравилось моё решение, в котором был
Следующий вопрос был: «Можете ли вы сделать простую группировку и сумму в Hadoop?» Разумеется, могу, и я попросил пример формата данных.
Они вручили мне флэш-диск со всеми 600 МБ данных (да, это были именно все данные, а не выборка). Не понимаю, почему, но им не понравилось моё решение, в котором был
pandas.read_csv и не было Hadoop.Вы понимаете Hadoop неправильно
5 min
— Мы получаем больше миллиона твитов в день, и наш сервер просто не успевает их обрабатывать. Поэтому мы хотим установить на кластер Hadoop и распределить обработку.
Речь шла о вычислительно тяжёлом сентиментном анализе, поэтому я мог поверить, что у одного сервера действительно не хватает CPU, чтобы справиться с большим потоком твитов.
— А что вы собираетесь делать с уже обработанными данными?
— Скорее всего, мы будем складывать их в MySQL, как делали это раньше, или даже удалять.
— Тогда вам определённо не нужен Hadoop.
Мой бывший коллега был далеко не первым, кто говорил про распределённые вычисления на Hadoop. И каждый раз я видел полное непонимание того, зачем была придумана и разработана эта платформа.
Как быстро запустить сложный проект?
4 min

Три недели назад мы выступали на коференции RockIT Conf, которая прошла в Таллине в формате баркемпа. На RockIT технические доклады сменялись выступлением рок-команд, в кулуарах царила неформальная атмосфера. Событие прошло в два дня — первый был стопроцентно боевой, на второй народ разошелся и было немного кисло. Организаторы обещали провести следующий ивент в Питере и учесть ошибки первого RockIT.
Мы выступили с рассказом о том, как быстро запустить сложный проект, перспективы которого можно оценить только по реакции публики. Мы сторонники реального фидбека, а не экспертных заключений. Доклад был посвящен тому, как весной 2012 года запускался sociate.ru — проект для автоматизированного размещения рекламных сообщений в сообществах ВКонтакте.
Многое из того, что написано ниже, можно смело вложить в уста Капитана. Да, это действительно так. Но! Я сам из технарей и сам знаю, как часто мы увлекаемся какой-то технической фитюлькой, крутым рефакторингом или внедрением новых технологий. В 90% случаев пользователь об этом не узнает, особенно, если проект новый.
Новому проекту нужен новый функционал, новые пользователи и новые впечатления. Уже когда концепция проверена, аудитория собралась, а проект живет — выкидываем рашпиль и берем в руки нулёвку, полируем до блеска.
* еще раз, чтобы не было войны в комментариях — подход, описанный в статье подходит не всегда и не для всех проектов
Чем поможет архитектору «NoSQL» и… поможет ли?
6 min
В последнее время все больше говорят про «NoSQL» — прямо «модный» тренд образовался. «Технологию» начинают активно использовать известные авторитетные компании, в т.ч. в высоконагруженных проектах с немалыми объемами данных — и кто-то восхищается, а кто-то обливает себя бензином и факелом выпрыгивает с 35 этажа с криком: "SQL ACID forever!"

Причем о каком бы продукте не говорили, будь то MongoDB или Cassandra — нередко приходится наблюдать прямо таки религиозную восторженность и трепет, как будто речь идет о чем-то новом и священном.
Причем о каком бы продукте не говорили, будь то MongoDB или Cassandra — нередко приходится наблюдать прямо таки религиозную восторженность и трепет, как будто речь идет о чем-то новом и священном.
История открытых данных и Хакатон Яндекса
14 min
14 — 15 сентября в Москве пройдёт первый Хакатон Яндекса, участники которого будут два дня и две ночи создавать проекты на основе открытых государственных данных с помощью технологий Яндекса.
Я уже много лет занимаюсь тем, чтобы у российских разработчиков рос интерес к работе с открытыми данными. Именно для этого создан конкурс Apps4Russia, организованный некоммерческим партнерством «Информационная культура». В этом году в нем появилась номинация для тех, кто создает приложения на отрытых данных и технологиях Яндекса. Эти события подтолкнули систематизированно рассказать здесь об истории открытых данных, их источниках, примерах использования и многих других важных вещах.
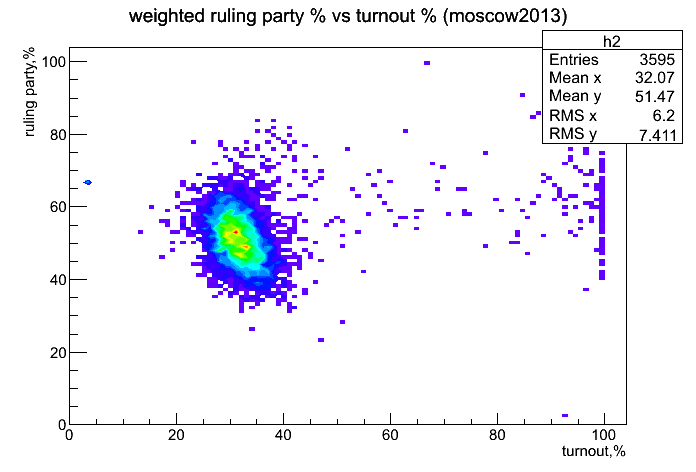
Это график из ЖЖ eugenyboger. То, что сейчас мы можем узнать подробные результаты выборов по каждому участку, — это норма, а еще совсем недавно это было не так даже в очень развитых странах.
Я уже много лет занимаюсь тем, чтобы у российских разработчиков рос интерес к работе с открытыми данными. Именно для этого создан конкурс Apps4Russia, организованный некоммерческим партнерством «Информационная культура». В этом году в нем появилась номинация для тех, кто создает приложения на отрытых данных и технологиях Яндекса. Эти события подтолкнули систематизированно рассказать здесь об истории открытых данных, их источниках, примерах использования и многих других важных вещах.
Это график из ЖЖ eugenyboger. То, что сейчас мы можем узнать подробные результаты выборов по каждому участку, — это норма, а еще совсем недавно это было не так даже в очень развитых странах.