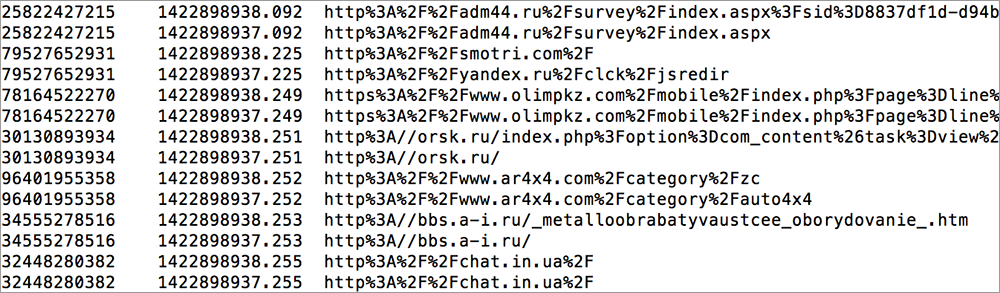
О чатботах, использующих нейронные сети я уже писал некоторое время назад. Сегодня я расскажу о том как я попробовал сделать полномасштабный русскоязычный вариант.

Обучаемые диалоговые системы приобрели в последнее время неожиданную популярность. К сожалению, все что сделано в рамках нейросетевых диалоговых систем, сделано для английского языка. Но сегодня мы восполним этот пробел и научим модель говорить по русски.
Обучаемые диалоговые системы приобрели в последнее время неожиданную популярность. К сожалению, все что сделано в рамках нейросетевых диалоговых систем, сделано для английского языка. Но сегодня мы восполним этот пробел и научим модель говорить по русски.