
Скрытые модели/цепи Маркова одни из подходов к представлению данных. Мне очень понравилось как обобщается множество таких подходов в этой статье.
В продолжение же моей предыдущей статьи описания скрытых моделей Маркова, задамся вопросом: откуда взять хорошую модель? Ответ достаточно стандартен, взять неплохую модель и сделать из нее хорошую.
Напомню пример: нам нужно реализовать детектор лжи, который по подрагиванию рук человека, определяет, говорит он правду или нет. Допустим, когда человек лжет, руки трясутся чуть больше, но нам не известно на сколько именно. Возьмем модель наобум, прогоним алгоритм Витерби из предыдущей статьи и получим довольно странные результаты:
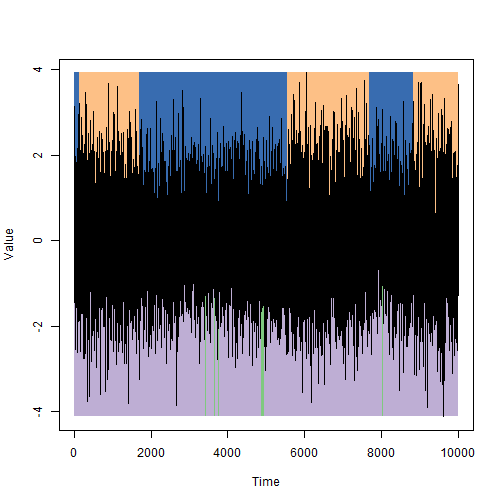
В продолжение же моей предыдущей статьи описания скрытых моделей Маркова, задамся вопросом: откуда взять хорошую модель? Ответ достаточно стандартен, взять неплохую модель и сделать из нее хорошую.
Напомню пример: нам нужно реализовать детектор лжи, который по подрагиванию рук человека, определяет, говорит он правду или нет. Допустим, когда человек лжет, руки трясутся чуть больше, но нам не известно на сколько именно. Возьмем модель наобум, прогоним алгоритм Витерби из предыдущей статьи и получим довольно странные результаты:


 В этой статье я расскажу об одном необычном подходе к генерации лабиринтов. Он основан на модели Амари́ нейронной активности коры головного мозга, являющейся непрерывным аналогом нейронных сетей. При определенных условиях она позволяет создавать красивые лабиринты очень сложной формы, подобные тому, что приведен на картинке.
В этой статье я расскажу об одном необычном подходе к генерации лабиринтов. Он основан на модели Амари́ нейронной активности коры головного мозга, являющейся непрерывным аналогом нейронных сетей. При определенных условиях она позволяет создавать красивые лабиринты очень сложной формы, подобные тому, что приведен на картинке.

 Многие слышали о великом и ужасном быстром преобразовании Фурье (БПФ / FFT — fast fourier transform) — но как его можно применять для решения практических задач за исключением
Многие слышали о великом и ужасном быстром преобразовании Фурье (БПФ / FFT — fast fourier transform) — но как его можно применять для решения практических задач за исключением 
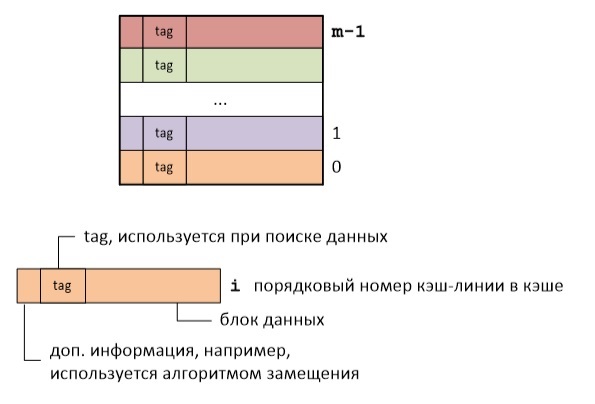
 Ко мне обратился один руководитель стартапа социальной игры с просьбой увеличить производительность своего проекта. На этом этапе был сделан и запущен прототип проекта. И надо отдать должное разработчикам, что проект работал и даже приносил какую-то прибыль. Но, запускать рекламную компанию не имело смысло, так как проект не выдерживал ни каких нагрузок. Валился MySQL (35% ошибок).
Ко мне обратился один руководитель стартапа социальной игры с просьбой увеличить производительность своего проекта. На этом этапе был сделан и запущен прототип проекта. И надо отдать должное разработчикам, что проект работал и даже приносил какую-то прибыль. Но, запускать рекламную компанию не имело смысло, так как проект не выдерживал ни каких нагрузок. Валился MySQL (35% ошибок).