
HyperDex — новое опенсорсное NoSQL key-value хранилище, заточенное на очень быстрый поиск
2 min
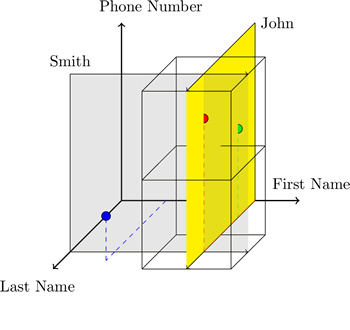
Авторы позиционируют HyperDex как распределённое, отказоустойчивое, легко-маштабируемое, заточенное на очень быстрый поиск NoSQL key-value хранилище.
Главная фича — новый принцип хранения объектов в многомерном эвклидовом пространстве (рис. слева), используя гиперпространственное хэширование (hyperspace hashing) (на который, кстати, авторы сейчас получают патент), которое позволяет выполнять большинство типичных задач от 2 до 13 раз быстрее, чем в MongoDB, Redis, Cassandra.
 Profile-guided optimization (далее PGO) — техника оптимизации программы компилятором, нацеленная на увеличение производительности выполнения программы. В отличии от традиционных способов оптимизации анализирующих исключительно исходные коды, PGO использует результаты измерений тестовых запусков оптимизируемой программы для генерации оптимального кода.
Profile-guided optimization (далее PGO) — техника оптимизации программы компилятором, нацеленная на увеличение производительности выполнения программы. В отличии от традиционных способов оптимизации анализирующих исключительно исходные коды, PGO использует результаты измерений тестовых запусков оптимизируемой программы для генерации оптимального кода.
 В современном мире наверно все адекватные системные администраторы корпоративных сетей используют виртуализацию. Для мелкого и среднего бизнеса одним из самых осмысленных выборов гипервизора является бесплатная версия Citrix XenServer. Основное его преимущество для небольшой фирмы, не имеющей возможности покупать железо под задачи — это огромная гибкость, во многом за счёт Linux, на котором базируется обозначенный гипервизор.
В современном мире наверно все адекватные системные администраторы корпоративных сетей используют виртуализацию. Для мелкого и среднего бизнеса одним из самых осмысленных выборов гипервизора является бесплатная версия Citrix XenServer. Основное его преимущество для небольшой фирмы, не имеющей возможности покупать железо под задачи — это огромная гибкость, во многом за счёт Linux, на котором базируется обозначенный гипервизор.

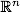 . Координаты вектора описывают отдельные аттрибуты объекта. Например, цвет c, заданный в модели RGB, является вектором в трехмерном пространстве: c=(red, green, blue).
. Координаты вектора описывают отдельные аттрибуты объекта. Например, цвет c, заданный в модели RGB, является вектором в трехмерном пространстве: c=(red, green, blue). 
 Всем доброго времени суток!
Всем доброго времени суток!
