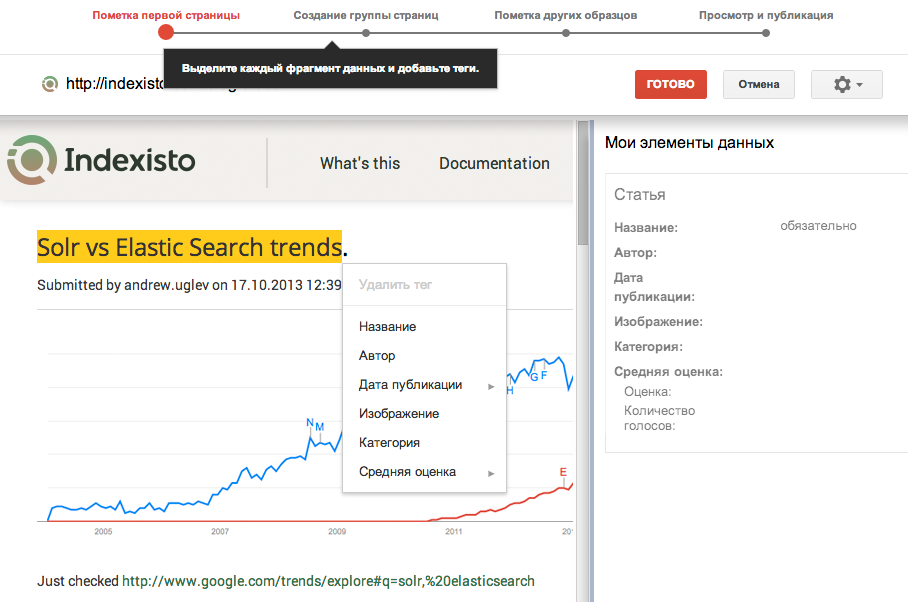
Прошлой осенью работа над моими побочными проектами зашла в тупик: я практически не продвигался вперёд и у меня никак не получалось делать больше, не принося в жертву свою основную работу в Khan Academy.
В моей организации работы обнаружилось несколько серьёзных проблем. В основном я работал по выходным и иногда по вечерам. Как оказалось, это не самая лучшая для меня стратегия. Необходимость сделать за выходные как можно больше и лучше сильно давила на меня, а если мне не удавалось доделать задуманное, это ощущалось как провал. Проблему усугубляло и то, что не было никакой гарантии, что очередные выходные будут свободны, и даже если так — не факт, что я захочу кодить с утра до вечера все эти два дня — надо ведь иногда как-то развлечься или просто расслабиться.
Кроме того, недельный перерыв — это слишком много, очень легко забыть, над чем ты работал и на чём остановился, даже если делать заметки. А уж если в выходные поработать не удавалось — то перерыв растягивался на две недели. Такие многонедельные переключения контекста могут быть смертельными — многие мои проекты погибли, не родившись, от такого недостатка внимания.
Услышав о невероятном эксперименте Дженнифер Девальт, которая решила изучить программирование, создав 180 сайтов за 180 дней, я отважился испробовать сходную тактику: работать над побочными проектами каждый день.

Иллюстрация Стивена Резига
В моей организации работы обнаружилось несколько серьёзных проблем. В основном я работал по выходным и иногда по вечерам. Как оказалось, это не самая лучшая для меня стратегия. Необходимость сделать за выходные как можно больше и лучше сильно давила на меня, а если мне не удавалось доделать задуманное, это ощущалось как провал. Проблему усугубляло и то, что не было никакой гарантии, что очередные выходные будут свободны, и даже если так — не факт, что я захочу кодить с утра до вечера все эти два дня — надо ведь иногда как-то развлечься или просто расслабиться.
Кроме того, недельный перерыв — это слишком много, очень легко забыть, над чем ты работал и на чём остановился, даже если делать заметки. А уж если в выходные поработать не удавалось — то перерыв растягивался на две недели. Такие многонедельные переключения контекста могут быть смертельными — многие мои проекты погибли, не родившись, от такого недостатка внимания.
Услышав о невероятном эксперименте Дженнифер Девальт, которая решила изучить программирование, создав 180 сайтов за 180 дней, я отважился испробовать сходную тактику: работать над побочными проектами каждый день.
Иллюстрация Стивена Резига